# GLM-4.6-GPTQ-Int4-Int8Mix
**Repository Path**: hf-models/GLM-4.6-GPTQ-Int4-Int8Mix
## Basic Information
- **Project Name**: GLM-4.6-GPTQ-Int4-Int8Mix
- **Description**: Mirror of https://huggingface.co/QuantTrio/GLM-4.6-GPTQ-Int4-Int8Mix
- **Primary Language**: Unknown
- **License**: Not specified
- **Default Branch**: main
- **Homepage**: None
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 0
- **Created**: 2025-11-11
- **Last Updated**: 2025-11-11
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
---
library_name: transformers
license: mit
pipeline_tag: text-generation
tags:
- GPTQ
- vLLM
base_model:
- zai-org/GLM-4.6
base_model_relation: quantized
---
# GLM-4.6-GPTQ-Int4-Int8Mix
Base Model: [zai-org/GLM-4.6](https://huggingface.co/zai-org/GLM-4.6)
### 【Dependencies / Installation】
As of **2025-10-01**, create a fresh Python environment and run:
```bash
pip install -U pip
pip install vllm==0.10.2
```
### 【vLLM Startup Command】
Note: When launching with TP=8, include `--enable-expert-parallel`;
otherwise the expert tensors couldn’t be evenly sharded across GPU devices.
```
CONTEXT_LENGTH=32768
vllm serve \
QuantTrio/GLM-4.6-GPTQ-Int4-Int8Mix \
--served-model-name My_Model \
--enable-auto-tool-choice \
--tool-call-parser glm45 \
--reasoning-parser glm45 \
--swap-space 16 \
--max-num-seqs 64 \
--max-model-len $CONTEXT_LENGTH \
--gpu-memory-utilization 0.9 \
--tensor-parallel-size 8 \
--enable-expert-parallel \
--trust-remote-code \
--disable-log-requests \
--host 0.0.0.0 \
--port 8000
```
### 【Logs】
```
2025-10-03
1. Initial commit
```
### 【Model Files】
| File Size | Last Updated |
|-----------|--------------|
| `232GB` | `2025-10-03` |
### 【Model Download】
```python
from modelscope import snapshot_download
snapshot_download('QuantTrio/GLM-4.6-GPTQ-Int4-Int8Mix', cache_dir="your_local_path")
```
### 【Overview】
# GLM-4.6
👋 Join our Discord community.
📖 Check out the GLM-4.6 technical blog, technical report(GLM-4.5), and Zhipu AI technical documentation.
📍 Use GLM-4.6 API services on Z.ai API Platform.
👉 One click to GLM-4.6.
## Model Introduction
Compared with GLM-4.5, **GLM-4.6** brings several key improvements:
* **Longer context window:** The context window has been expanded from 128K to 200K tokens, enabling the model to handle more complex agentic tasks.
* **Superior coding performance:** The model achieves higher scores on code benchmarks and demonstrates better real-world performance in applications such as Claude Code、Cline、Roo Code and Kilo Code, including improvements in generating visually polished front-end pages.
* **Advanced reasoning:** GLM-4.6 shows a clear improvement in reasoning performance and supports tool use during inference, leading to stronger overall capability.
* **More capable agents:** GLM-4.6 exhibits stronger performance in tool using and search-based agents, and integrates more effectively within agent frameworks.
* **Refined writing:** Better aligns with human preferences in style and readability, and performs more naturally in role-playing scenarios.
We evaluated GLM-4.6 across eight public benchmarks covering agents, reasoning, and coding. Results show clear gains over GLM-4.5, with GLM-4.6 also holding competitive advantages over leading domestic and international models such as **DeepSeek-V3.1-Terminus** and **Claude Sonnet 4**.
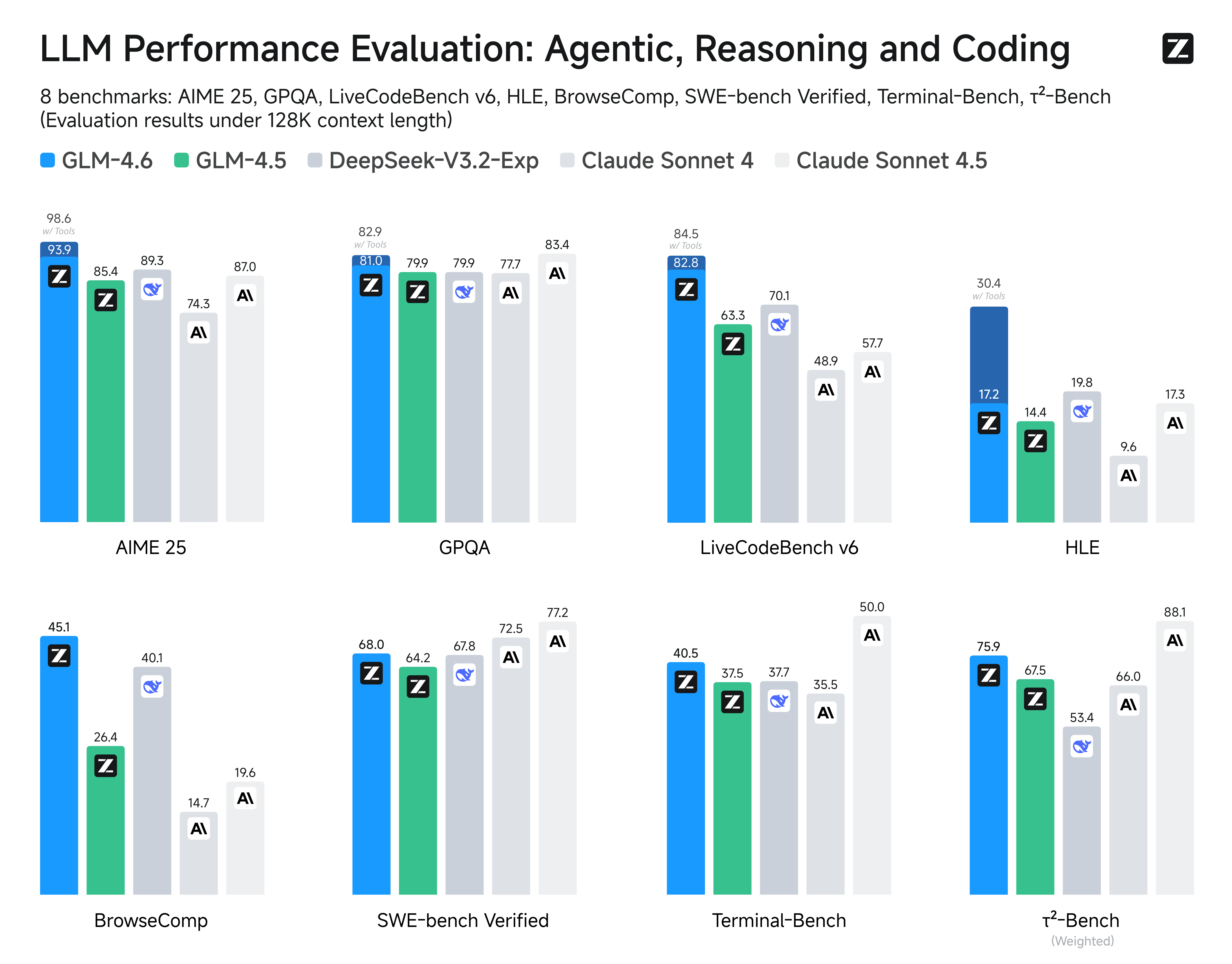
## Inference
**Both GLM-4.5 and GLM-4.6 use the same inference method.**
you can check our [github](https://github.com/zai-org/GLM-4.5) for more detail.
## Recommended Evaluation Parameters
For general evaluations, we recommend using a **sampling temperature of 1.0**.
For **code-related evaluation tasks** (such as LCB), it is further recommended to set:
- `top_p = 0.95`
- `top_k = 40`
## Evaluation
- For tool-integrated reasoning, please refer to [this doc](https://github.com/zai-org/GLM-4.5/blob/main/resources/glm_4.6_tir_guide.md).
- For search benchmark, we design a specific format for searching toolcall in thinking mode to support search agent, please refer to [this](https://github.com/zai-org/GLM-4.5/blob/main/resources/trajectory_search.json). for the detailed template.