(h, w) = {out_data[2*pix_num+index+frame_pix_num*frame], out_data[pix_num+index+frame_pix_num*frame], out_data[index+frame_pix_num*frame]};
+ index+=1;
+ }
+ }
+ result->push_back(res);
+ }
+}
+
+}
\ No newline at end of file
diff --git a/deploy/export_model.md b/deploy/export_model.md
new file mode 100644
index 0000000000000000000000000000000000000000..0d2073c2ba403699b1966c2f5115d88ac64ffa7b
--- /dev/null
+++ b/deploy/export_model.md
@@ -0,0 +1,36 @@
+# PaddleGAN模型导出教程
+
+## 一、模型导出
+本章节介绍如何使用`tools/export_model.py`脚本导出模型。
+
+### 1、启动参数说明
+
+| FLAG | 用途 | 默认值 | 备注 |
+|:--------------:|:--------------:|:------------:|:-----------------------------------------:|
+| -c | 指定配置文件 | None | |
+| --load | 指定加载的模型参数路径 | None | |
+| -s|--inputs_size | 指定模型输入形状 | None | |
+| --output_dir | 模型保存路径 | `./inference_model` | |
+
+### 2、使用示例
+
+使用训练得到的模型进行试用,这里使用CycleGAN模型为例,脚本如下
+
+```bash
+# 下载预训练好的CycleGAN_horse2zebra模型
+wget https://paddlegan.bj.bcebos.com/models/CycleGAN_horse2zebra.pdparams
+
+# 导出Cylclegan模型
+python -u tools/export_model.py -c configs/cyclegan_horse2zebra.yaml --load CycleGAN_horse2zebra.pdparams --inputs_size="-1,3,-1,-1;-1,3,-1,-1"
+```
+
+### 3、config配置说明
+```python
+export_model:
+ - {name: 'netG_A', inputs_num: 1}
+ - {name: 'netG_B', inputs_num: 1}
+```
+以上为```configs/cyclegan_horse2zebra.yaml```中的配置, 由于```CycleGAN_horse2zebra.pdparams```是个字典,需要制定其中用于导出模型的权重键值。```inputs_num```
+为该网络的输入个数。
+
+预测模型会导出到`inference_model/`目录下,分别为`cycleganmodel_netG_A.pdiparams`, `cycleganmodel_netG_A.pdiparams.info`, `cycleganmodel_netG_A.pdmodel`, `cycleganmodel_netG_B.pdiparams`, `cycleganmodel_netG_B.pdiparams.info`, `cycleganmodel_netG_B.pdmodel`,。
diff --git a/deploy/lite/README.md b/deploy/lite/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..c67c6bbe6385f05695ee1e521f9cef6320a02607
--- /dev/null
+++ b/deploy/lite/README.md
@@ -0,0 +1,177 @@
+# Paddle-Lite端侧部署
+
+本教程将介绍基于[Paddle Lite](https://github.com/PaddlePaddle/Paddle-Lite) 在移动端部署FOM模型的详细步骤。
+
+Paddle Lite是飞桨轻量化推理引擎,为手机、IOT端提供高效推理能力,并广泛整合跨平台硬件,为端侧部署及应用落地问题提供轻量化的部署方案。
+
+## 1. 准备环境
+
+### 运行准备
+- 电脑(编译Paddle Lite)
+- 安卓手机(armv7或armv8)
+
+### 1.1 准备交叉编译环境
+交叉编译环境用于编译 Paddle Lite 和 FOM 的C++ demo。
+支持多种开发环境,不同开发环境的编译流程请参考对应文档,请确保安装完成Java jdk、Android NDK(R17以上)。
+
+1. [Docker](https://paddle-lite.readthedocs.io/zh/latest/source_compile/compile_env.html#docker)
+2. [Linux](https://paddle-lite.readthedocs.io/zh/latest/source_compile/compile_env.html#linux)
+3. [MAC OS](https://paddle-lite.readthedocs.io/zh/latest/source_compile/compile_env.html#mac-os)
+
+### 1.2 准备预测库
+
+预测库有两种获取方式:
+1. 直接下载,预测库下载链接如下:
+ |平台|预测库下载链接|
+ |-|-|
+ |Android|[arm7](https://github.com/PaddlePaddle/Paddle-Lite/releases/download/v2.8/inference_lite_lib.android.armv7.gcc.c++_static.with_extra.with_cv.tar.gz) / [arm8](https://github.com/PaddlePaddle/Paddle-Lite/releases/download/v2.8/inference_lite_lib.android.armv8.gcc.c++_static.with_extra.with_cv.tar.gz)|
+
+**注意**:1. 目前FOM的算子只在PaddleLite的develop版本中支持,需要自行下载编译 2.如果是从 Paddle-Lite [官方文档](https://paddle-lite.readthedocs.io/zh/latest/quick_start/release_lib.html#android-toolchain-gcc)下载的预测库,注意选择`with_extra=ON,with_cv=ON`的下载链接。3. 目前只提供Android端demo.
+
+
+2. 编译Paddle-Lite得到预测库,Paddle-Lite的编译方式如下:
+```shell
+git clone https://github.com/PaddlePaddle/Paddle-Lite.git
+cd Paddle-Lite
+# 如果使用编译方式,建议使用develop分支编译预测库
+git checkout develop
+./lite/tools/build_android.sh --arch=armv8 --with_cv=ON --with_extra=ON
+```
+
+**注意**:编译Paddle-Lite获得预测库时,需要打开`--with_cv=ON --with_extra=ON`两个选项,`--arch`表示`arm`版本,这里指定为armv8,更多编译命令介绍请参考[链接](https://paddle-lite.readthedocs.io/zh/latest/source_compile/compile_andriod.html#id2)。
+
+直接下载预测库并解压后,可以得到`inference_lite_lib.android.armv8.gcc.c++_static.with_extra.with_cv/`文件夹,通过编译Paddle-Lite得到的预测库位于`Paddle-Lite/build.lite.android.armv8.gcc/inference_lite_lib.android.armv8/`文件夹下。
+预测库的文件目录如下:
+
+```
+inference_lite_lib.android.armv8/
+|-- cxx C++ 预测库和头文件
+| |-- include C++ 头文件
+| | |-- paddle_api.h
+| | |-- paddle_image_preprocess.h
+| | |-- paddle_lite_factory_helper.h
+| | |-- paddle_place.h
+| | |-- paddle_use_kernels.h
+| | |-- paddle_use_ops.h
+| | `-- paddle_use_passes.h
+| `-- lib C++预测库
+| |-- libpaddle_api_light_bundled.a C++静态库
+| `-- libpaddle_light_api_shared.so C++动态库
+|-- java Java预测库
+| |-- jar
+| | `-- PaddlePredictor.jar
+| |-- so
+| | `-- libpaddle_lite_jni.so
+| `-- src
+|-- demo C++和Java示例代码
+| |-- cxx C++ 预测库demo
+| `-- java Java 预测库demo
+```
+
+## 2 开始运行
+
+### 2.1 模型优化
+
+Paddle-Lite 提供了多种策略来自动优化原始的模型,其中包括量化、子图融合、混合调度、Kernel优选等方法,使用Paddle-Lite的`opt`工具可以自动对inference模型进行优化,目前支持两种优化方式,优化后的模型更轻量,模型运行速度更快。
+
+**注意**:如果已经准备好了 `.nb` 结尾的模型文件,可以跳过此步骤。
+
+#### 2.1.1 安装paddle_lite_opt工具
+安装paddle_lite_opt工具有如下两种方法:
+1. [**建议**]pip安装paddlelite并进行转换
+ ```shell
+ pip install paddlelite
+ ```
+
+2. 源码编译Paddle-Lite生成opt工具
+
+ 模型优化需要Paddle-Lite的`opt`可执行文件,可以通过编译Paddle-Lite源码获得,编译步骤如下:
+ ```shell
+ # 如果准备环境时已经clone了Paddle-Lite,则不用重新clone Paddle-Lite
+ git clone https://github.com/PaddlePaddle/Paddle-Lite.git
+ cd Paddle-Lite
+ git checkout develop
+ # 启动编译
+ ./lite/tools/build.sh build_optimize_tool
+ ```
+
+ 编译完成后,`opt`文件位于`build.opt/lite/api/`下,可通过如下方式查看`opt`的运行选项和使用方式;
+ ```shell
+ cd build.opt/lite/api/
+ ./opt
+ ```
+
+ `opt`的使用方式与参数与上面的`paddle_lite_opt`完全一致。
+
+之后使用`paddle_lite_opt`工具可以进行inference模型的转换。`paddle_lite_opt`的部分参数如下:
+
+|选项|说明|
+|-|-|
+|--model_file|待优化的PaddlePaddle模型(combined形式)的网络结构文件路径|
+|--param_file|待优化的PaddlePaddle模型(combined形式)的权重文件路径|
+|--optimize_out_type|输出模型类型,目前支持两种类型:protobuf和naive_buffer,其中naive_buffer是一种更轻量级的序列化/反序列化实现,默认为naive_buffer|
+|--optimize_out|优化模型的输出路径|
+|--valid_targets|指定模型可执行的backend,默认为arm。目前可支持x86、arm、opencl、npu、xpu,可以同时指定多个backend(以空格分隔),Model Optimize Tool将会自动选择最佳方式。如果需要支持华为NPU(Kirin 810/990 Soc搭载的达芬奇架构NPU),应当设置为npu, arm|
+
+更详细的`paddle_lite_opt`工具使用说明请参考[使用opt转化模型文档](https://paddle-lite.readthedocs.io/zh/latest/user_guides/opt/opt_bin.html)
+
+`--model_file`表示inference模型的model文件地址,`--param_file`表示inference模型的param文件地址;`optimize_out`用于指定输出文件的名称(不需要添加`.nb`的后缀)。直接在命令行中运行`paddle_lite_opt`,也可以查看所有参数及其说明。
+
+
+#### 2.1.3 FOM转换示例
+```shell
+# 将inference模型转化为Paddle-Lite优化模型
+paddle_lite_opt --model_file=output_inference/fom_dy2st/generator.pdmodel \
+ --param_file=output_inference/fom_dy2st/generator.pdiparams \
+ --optimize_out=output_inference/fom_dy2st/generator_lite \
+ --optimize_out_type=naive_buffer \
+ --valid_targets=arm
+paddle_lite_opt --model_file=output_inference/fom_dy2st/kp_detector.pdmodel \
+ --param_file=output_inference/fom_dy2st/kp_detector.pdiparams \
+ --optimize_out=output_inference/fom_dy2st/kp_detector_lite \
+ --optimize_out_type=naive_buffer \
+ --valid_targets=arm
+```
+
+最终在当前文件夹下生成`generator_lite.nb`和`kp_detector_lite.nb`的文件。
+
+**注意**:`--optimize_out` 参数为优化后模型的保存路径,无需加后缀`.nb`;`--model_file` 参数为模型结构信息文件的路径,`--param_file` 参数为模型权重信息文件的路径,请注意文件名。
+
+### 2.2 与手机联调
+
+首先需要进行一些准备工作。
+1. 准备一台arm8的安卓手机,如果编译的预测库和opt文件是armv7,则需要arm7的手机,并修改Makefile中`ARM_ABI = arm7`。
+2. 电脑上安装ADB工具,用于调试。 ADB安装方式如下:
+
+ 2.1. MAC电脑安装ADB:
+
+ ```shell
+ brew cask install android-platform-tools
+ ```
+ 2.2. Linux安装ADB
+ ```shell
+ sudo apt update
+ sudo apt install -y wget adb
+ ```
+ 2.3. Window安装ADB
+
+ win上安装需要去谷歌的安卓平台下载ADB软件包进行安装:[链接](https://developer.android.com/studio)
+
+3. 手机连接电脑后,开启手机`USB调试`选项,选择`文件传输`模式,在电脑终端中输入:
+
+```shell
+adb devices
+```
+如果有device输出,则表示安装成功,如下所示:
+```
+List of devices attached
+744be294 device
+```
+
+4. 准备优化后的模型、预测库文件、测试图像和类别映射文件, 导入手机等运行,目前apk还存在一些效果问题,还在优化中。
+
+
+## FAQ
+Q1:如果想更换模型怎么办,需要重新按照流程走一遍吗?
+A1:如果已经走通了上述步骤,更换模型只需要替换 `.nb` 模型文件即可,同时要注意修改下配置文件中的 `.nb` 文件路径以及类别映射文件(如有必要)。
+
diff --git a/deploy/serving/README.md b/deploy/serving/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..9d16e022b5b4f44bc4a697a2a7973822c18ec2b8
--- /dev/null
+++ b/deploy/serving/README.md
@@ -0,0 +1,101 @@
+# 服务端预测部署
+
+`PaddleGAN`训练出来的模型可以使用[Serving](https://github.com/PaddlePaddle/Serving) 部署在服务端。
+本教程以在REDS数据集上用`configs/msvsr_reds.yaml`算法训练的模型进行部署。
+预训练模型权重文件为[PP-MSVSR_reds_x4.pdparams](https://paddlegan.bj.bcebos.com/models/PP-MSVSR_reds_x4.pdparams) 。
+
+## 1. 安装 paddle serving
+请参考[PaddleServing](https://github.com/PaddlePaddle/Serving/tree/v0.6.0) 中安装教程安装(版本>=0.6.0)。
+
+## 2. 导出模型
+PaddleGAN在训练过程包括网络的前向和优化器相关参数,而在部署过程中,我们只需要前向参数,具体参考:[导出模型](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/deploy/EXPORT_MODEL.md)
+
+```
+python tools/export_model.py -c configs/msvsr_reds.yaml --inputs_size="1,2,3,180,320" --load /path/to/model --export_serving_model True
+----output_dir /path/to/output
+```
+
+以上命令会在`/path/to/output`文件夹下生成一个`msvsr`文件夹:
+```
+output
+│ ├── multistagevsrmodel_generator
+│ │ ├── multistagevsrmodel_generator.pdiparams
+│ │ ├── multistagevsrmodel_generator.pdiparams.info
+│ │ ├── multistagevsrmodel_generator.pdmodel
+│ │ ├── serving_client
+│ │ │ ├── serving_client_conf.prototxt
+│ │ │ ├── serving_client_conf.stream.prototxt
+│ │ ├── serving_server
+│ │ │ ├── __model__
+│ │ │ ├── __params__
+│ │ │ ├── serving_server_conf.prototxt
+│ │ │ ├── serving_server_conf.stream.prototxt
+│ │ │ ├── ...
+```
+
+`serving_client`文件夹下`serving_client_conf.prototxt`详细说明了模型输入输出信息
+`serving_client_conf.prototxt`文件内容为:
+```
+feed_var {
+ name: "lqs"
+ alias_name: "lqs"
+ is_lod_tensor: false
+ feed_type: 1
+ shape: 1
+ shape: 2
+ shape: 3
+ shape: 180
+ shape: 320
+}
+fetch_var {
+ name: "stack_18.tmp_0"
+ alias_name: "stack_18.tmp_0"
+ is_lod_tensor: false
+ fetch_type: 1
+ shape: 1
+ shape: 2
+ shape: 3
+ shape: 720
+ shape: 1280
+}
+fetch_var {
+ name: "stack_19.tmp_0"
+ alias_name: "stack_19.tmp_0"
+ is_lod_tensor: false
+ fetch_type: 1
+ shape: 1
+ shape: 3
+ shape: 720
+ shape: 1280
+}
+```
+
+## 4. 启动PaddleServing服务
+
+```
+cd output_dir/multistagevsrmodel_generator/
+
+# GPU
+python -m paddle_serving_server.serve --model serving_server --port 9393 --gpu_ids 0
+
+# CPU
+python -m paddle_serving_server.serve --model serving_server --port 9393
+```
+
+## 5. 测试部署的服务
+```
+# 进入到导出模型文件夹
+cd output/msvsr/
+```
+
+设置`prototxt`文件路径为`serving_client/serving_client_conf.prototxt` 。
+设置`fetch`为`fetch=["stack_19.tmp_0"])`
+
+测试
+```
+# 进入目录
+cd output/msvsr/
+
+# 测试代码 test_client.py 会自动创建output文件夹,并在output下生成`res.mp4`文件
+python ../../deploy/serving/test_client.py input_video frame_num
+```
diff --git a/deploy/serving/test_client.py b/deploy/serving/test_client.py
new file mode 100644
index 0000000000000000000000000000000000000000..c5e0ae73a50673840a376cdca37b69e2bfd74933
--- /dev/null
+++ b/deploy/serving/test_client.py
@@ -0,0 +1,78 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+import numpy as np
+from paddle_serving_client import Client
+from paddle_serving_app.reader import *
+import cv2
+import os
+import imageio
+
+def get_img(pred):
+ pred = pred.squeeze()
+ pred = np.clip(pred, a_min=0., a_max=1.0)
+ pred = pred * 255
+ pred = pred.round()
+ pred = pred.astype('uint8')
+ pred = np.transpose(pred, (1, 2, 0)) # chw -> hwc
+ return pred
+
+preprocess = Sequential([
+ BGR2RGB(), Resize(
+ (320, 180)), Div(255.0), Transpose(
+ (2, 0, 1))
+])
+
+client = Client()
+
+client.load_client_config("serving_client/serving_client_conf.prototxt")
+client.connect(['127.0.0.1:9393'])
+
+frame_num = int(sys.argv[2])
+
+cap = cv2.VideoCapture(sys.argv[1])
+fps = cap.get(cv2.CAP_PROP_FPS)
+size = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),
+ int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
+success, frame = cap.read()
+read_end = False
+res_frames = []
+output_dir = "./output"
+if not os.path.exists(output_dir):
+ os.makedirs(output_dir)
+
+while success:
+ frames = []
+ for i in range(frame_num):
+ if success:
+ frames.append(preprocess(frame))
+ success, frame = cap.read()
+ else:
+ read_end = True
+ if read_end: break
+
+ frames = np.stack(frames, axis=0)
+ fetch_map = client.predict(
+ feed={
+ "lqs": frames,
+ },
+ fetch=["stack_19.tmp_0"],
+ batch=False)
+ res_frames.extend([fetch_map["stack_19.tmp_0"][0][i] for i in range(frame_num)])
+
+imageio.mimsave("output/output.mp4",
+ [get_img(frame) for frame in res_frames],
+ fps=fps)
+
diff --git a/docs/en_US/apis/apps.md b/docs/en_US/apis/apps.md
deleted file mode 120000
index 5e0941aad3f32570ca9539cefba472e7e32efc25..0000000000000000000000000000000000000000
--- a/docs/en_US/apis/apps.md
+++ /dev/null
@@ -1 +0,0 @@
-../../zh_CN/apis/apps.md
\ No newline at end of file
diff --git a/docs/en_US/apis/apps.md b/docs/en_US/apis/apps.md
new file mode 100644
index 0000000000000000000000000000000000000000..4d5e343d5b4632861a8ee04668d5483b0ecd31a6
--- /dev/null
+++ b/docs/en_US/apis/apps.md
@@ -0,0 +1,627 @@
+# Introduction of Prediction Interface
+
+PaddleGAN(ppgan.apps)provides prediction APIs covering multiple applications, including super resolution, video frame interpolation, colorization, makeup shifter, image animation, face parsing, etc. The integral pre-trained high-performance models enable users' flexible and efficient usage and inference.
+
+* Colorization:
+ * [DeOldify](#ppgan.apps.DeOldifyPredictor)
+ * [DeepRemaster](#ppgan.apps.DeepRemasterPredictor)
+* Super Resolution:
+ * [RealSR](#ppgan.apps.RealSRPredictor)
+ * [PPMSVSR](#ppgan.apps.PPMSVSRPredictor)
+ * [PPMSVSRLarge](#ppgan.apps.PPMSVSRLargePredictor)
+ * [EDVR](#ppgan.apps.EDVRPredictor)
+ * [BasicVSR](#ppgan.apps.BasicVSRPredictor)
+ * [IconVSR](#ppgan.apps.IconVSRPredictor)
+ * [BasiVSRPlusPlus](#ppgan.apps.BasiVSRPlusPlusPredictor)
+* Video Frame Interpolation:
+ * [DAIN](#ppgan.apps.DAINPredictor)
+* Motion Driving:
+ * [FirstOrder](#ppgan.apps.FirstOrderPredictor)
+* Face:
+ * [FaceFaceParse](#ppgan.apps.FaceParsePredictor)
+* Image Animation:
+ * [AnimeGAN](#ppgan.apps.AnimeGANPredictor)
+* Lip-syncing:
+ * [Wav2Lip](#ppgan.apps.Wav2LipPredictor)
+
+
+## Public Usage
+
+### Switch of CPU and GPU
+
+By default, GPU devices with the [PaddlePaddle](https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/install/pip/windows-pip.html) GPU environment package installed conduct inference by using GPU. If the CPU environment package is installed, CPU is used for inference.
+
+If manual switch of CPU and GPU is needed,you can do the following:
+
+
+```
+import paddle
+paddle.set_device('cpu') #set as CPU
+#paddle.set_device('gpu') #set as GPU
+```
+
+## ppgan.apps.DeOldifyPredictor
+
+```python
+ppgan.apps.DeOldifyPredictor(output='output', weight_path=None, render_factor=32)
+```
+
+> Build the instance of DeOldify. DeOldify is a coloring model based on GAN. The interface supports the colorization of images or videos. The recommended video format is mp4.
+>
+> **Example**
+>
+> ```python
+> from ppgan.apps import DeOldifyPredictor
+> deoldify = DeOldifyPredictor()
+> deoldify.run("docs/imgs/test_old.jpeg")
+> ```
+> **Parameters**
+>
+> > - output (str): path of the output image, default: output. Note that the save path should be set as output/DeOldify.
+> > - weight_path (str): path of the model, default: None,pre-trained integral model will then be automatically downloaded.
+> > - artistic (bool): whether to use "artistic" model, which may produce interesting colors, but there are more glitches.
+> > - render_factor (int): the zoom factor during image rendering and colorization. The image will be zoomed to a square with side length of 16xrender_factor before being colorized. For example, with a default value of 32,the entered image will be resized to (16x32=512) 512x512. Normally,the smaller the render_factor,the faster the computation and the more vivid the colors. Therefore, old images with low quality usually benefits from lowering the value of rendering factor. The higher the value, the better the image quality, but the color may fade slightly.
+### run
+
+```python
+run(input)
+```
+
+> The execution interface after building the instance.
+> **Parameters**
+>
+> > - input (str|np.ndarray|Image.Image): the input image or video files。For images, it could be its path, np.ndarray, or PIL.Image type. For videos, it could only be the file path.
+>
+>**Return Value**
+>
+>> - tuple(pred_img(np.array), out_paht(str)): for image input, return the predicted image, PIL.Image type and the path where the image is saved.
+> > - tuple(frame_path(str), out_path(str)): for video input, frame_path is the save path of the images after colorizing each frame of the video, and out_path is the save path of the colorized video.
+### run_image
+
+```python
+run_image(img)
+```
+
+> The interface of image colorization.
+> **Parameters**
+>
+> > - img (str|np.ndarray|Image.Image): input image,it could be the path of the image, np.ndarray, or PIL.Image type.
+>
+>**Return Value**
+>
+>> - pred_img(PIL.Image): return the predicted image, PIL.Image type.
+### run_video
+
+```python
+run_video(video)
+```
+
+> The interface of video colorization.
+> **Parameters**
+>
+> > - Video (str): path of the input video files.
+>
+> **Return Value**
+>
+> > - tuple(frame_path(str), out_path(str)): frame_path is the save path of the images after colorizing each frame of the video, and out_path is the save path of the colorized video.
+
+
+## ppgan.apps.DeepRemasterPredictor
+
+```python
+ppgan.apps.DeepRemasterPredictor(output='output', weight_path=None, colorization=False, reference_dir=None, mindim=360)
+```
+
+> Build the instance of DeepRemasterPredictor. DeepRemaster is a GAN-based coloring and restoring model, which can provide input reference frames. Only video input is available now, and the recommended format is mp4.
+>
+> **Example**
+>
+> ```
+> from ppgan.apps import DeepRemasterPredictor
+> deep_remaster = DeepRemasterPredictor()
+> deep_remaster.run("docs/imgs/test_old.jpeg")
+> ```
+>
+>
+> **Parameters**
+>
+> > - output (str): path of the output image, default: output. Note that the path should be set as output/DeepRemaster.
+> > - weight_path (str): path of the model, default: None,pre-trained integral model will then be automatically downloaded.
+> > - colorization (bool): whether to enable the coloring function, default: False, only the restoring function will be executed.
+> > - reference_dir(str|None): path of the reference frame when the coloring function is on, no reference frame is also allowed.
+> > - mindim(int): minimum side length of the resized image before prediction.
+### run
+
+```python
+run(video_path)
+```
+
+> The execution interface after building the instance.
+> **Parameters**
+>
+> > - video_path (str): path of the video file.
+> >
+> > **Return Value**
+> >
+> > - tuple(str, str)): return two types of str, the former is the save path of each frame of the colorized video, the latter is the save path of the colorized video.
+
+
+## ppgan.apps.RealSRPredictor
+
+```python
+ppgan.apps.RealSRPredictor(output='output', weight_path=None)
+```
+
+> Build the instance of RealSR。RealSR, Real-World Super-Resolution via Kernel Estimation and Noise Injection, is launched by CVPR 2020 Workshops in its super resolution model based on real-world images training. The interface imposes 4x super resolution on the input image or video. The recommended video format is mp4.
+>
+> *Note: the size of the input image should be less than 1000x1000pix。
+>
+> **Example**
+>
+> ```
+> from ppgan.apps import RealSRPredictor
+> sr = RealSRPredictor()
+> sr.run("docs/imgs/test_sr.jpeg")
+> ```
+> **Parameters**
+>
+> > - output (str): path of the output image, default: output. Note that the path should be set as output/RealSR.
+> > - weight_path (str): path of the model, default: None,pre-trained integral model will then be automatically downloaded.
+```python
+run(video_path)
+```
+
+> The execution interface after building the instance.
+> **Parameters**
+>
+> > - video_path (str): path of the video file.
+>
+>**Return Value**
+>
+>> - tuple(pred_img(np.array), out_paht(str)): for image input, return the predicted image, PIL.Image type and the path where the image is saved.
+> > - tuple(frame_path(str), out_path(str)): for video input, frame_path is the save path of each frame of the video after super resolution, and out_path is the save path of the video after super resolution.
+### run_image
+
+```python
+run_image(img)
+```
+
+> The interface of image super resolution.
+> **Parameter**
+>
+> > - img (str|np.ndarray|Image.Image): input image, it could be the path of the image, np.ndarray, or PIL.Image type.
+>
+> **Return Value**
+>
+> > - pred_img(PIL.Image): return the predicted image, PIL.Image type.
+### run_video
+
+```python
+run_video(video)
+```
+
+> The interface of video super resolution.
+> **Parameter**
+>
+> > - Video (str): path of the video file.
+>
+> **Return Value**
+>
+> > - tuple(frame_path(str), out_path(str)): frame_path is the save path of each frame of the video after super resolution, and out_path is the save path of the video after super resolution.
+
+
+
+## ppgan.apps.PPMSVSRPredictor
+
+```python
+ppgan.apps.PPMSVSRPredictor(output='output', weight_path=None, num_frames=10)
+```
+
+> Build the instance of PPMSVSR. PPMSVSR is a multi-stage VSR deep architecture. For more details, see the paper, PP-MSVSR: Multi-Stage Video Super-Resolution (https://arxiv.org/pdf/2112.02828.pdf). The interface imposes 4x super resolution on the input video. The recommended video format is mp4.
+>
+> **Parameter**
+>
+> ```
+> from ppgan.apps import PPMSVSRPredictor
+> sr = PPMSVSRPredictor()
+> # test a video file
+> sr.run("docs/imgs/test.mp4")
+> ```
+> **参数**
+>
+> > - output (str): path of the output image, default: output. Note that the path should be set as output/EDVR.
+> > - weight_path (str): path of the model, default: None,pre-trained integral model will then be automatically downloaded.
+> > - num_frames (int): the number of input frames of the PPMSVSR model, the default value: 10. Note that the larger the num_frames, the better the effect of the video after super resolution.
+```python
+run(video_path)
+```
+
+> The execution interface after building the instance.
+> **Parameter**
+>
+> > - video_path (str): path of the video files.
+>
+> **Return Value**
+>
+> > - tuple(str, str): the former is the save path of each frame of the video after super resolution, the latter is the save path of the video after super resolution.
+
+
+## ppgan.apps.PPMSVSRLargePredictor
+
+```python
+ppgan.apps.PPMSVSRLargePredictor(output='output', weight_path=None, num_frames=10)
+```
+
+> Build the instance of PPMSVSRLarge. PPMSVSRLarge is a Large PPMSVSR model. For more details, see the paper, PP-MSVSR: Multi-Stage Video Super-Resolution (https://arxiv.org/pdf/2112.02828.pdf). The interface imposes 4x super resolution on the input video. The recommended video format is mp4.
+>
+> **Parameter**
+>
+> ```
+> from ppgan.apps import PPMSVSRLargePredictor
+> sr = PPMSVSRLargePredictor()
+> # test a video file
+> sr.run("docs/imgs/test.mp4")
+> ```
+> **参数**
+>
+> > - output (str): path of the output image, default: output. Note that the path should be set as output/EDVR.
+> > - weight_path (str): path of the model, default: None,pre-trained integral model will then be automatically downloaded.
+> > - num_frames (int): the number of input frames of the PPMSVSR model, the default value: 10. Note that the larger the num_frames, the better the effect of the video after super resolution.
+```python
+run(video_path)
+```
+
+> The execution interface after building the instance.
+> **Parameter**
+>
+> > - video_path (str): path of the video files.
+>
+> **Return Value**
+>
+> > - tuple(str, str): the former is the save path of each frame of the video after super resolution, the latter is the save path of the video after super resolution.
+
+## ppgan.apps.EDVRPredictor
+
+```python
+ppgan.apps.EDVRPredictor(output='output', weight_path=None)
+```
+
+> Build the instance of EDVR. EDVR is a model designed for video super resolution. For more details, see the paper, EDVR: Video Restoration with Enhanced Deformable Convolutional Networks (https://arxiv.org/abs/1905.02716). The interface imposes 4x super resolution on the input video. The recommended video format is mp4.
+>
+> **Parameter**
+>
+> ```
+> from ppgan.apps import EDVRPredictor
+> sr = EDVRPredictor()
+> # test a video file
+> sr.run("docs/imgs/test.mp4")
+> ```
+> **参数**
+>
+> > - output (str): path of the output image, default: output. Note that the path should be set as output/EDVR.
+> > - weight_path (str): path of the model, default: None,pre-trained integral model will then be automatically downloaded.
+```python
+run(video_path)
+```
+
+> The execution interface after building the instance.
+> **Parameter**
+>
+> > - video_path (str): path of the video files.
+>
+> **Return Value**
+>
+> > - tuple(str, str): the former is the save path of each frame of the video after super resolution, the latter is the save path of the video after super resolution.
+
+
+## ppgan.apps.BasicVSRPredictor
+
+```python
+ppgan.apps.BasicVSRPredictor(output='output', weight_path=None, num_frames=10)
+```
+
+> Build the instance of BasicVSR. BasicVSR is a model designed for video super resolution. For more details, see the paper, BasicVSR: The Search for Essential Components in Video Super-Resolution and Beyond (https://arxiv.org/pdf/2012.02181.pdf). The interface imposes 4x super resolution on the input video. The recommended video format is mp4.
+>
+> **Parameter**
+>
+> ```
+> from ppgan.apps import BasicVSRPredictor
+> sr = BasicVSRPredictor()
+> # test a video file
+> sr.run("docs/imgs/test.mp4")
+> ```
+> **参数**
+>
+> > - output (str): path of the output image, default: output. Note that the path should be set as output/EDVR.
+> > - weight_path (str): path of the model, default: None,pre-trained integral model will then be automatically downloaded.
+> > - num_frames (int): the number of input frames of the PPMSVSR model, the default value: 10. Note that the larger the num_frames, the better the effect of the video after super resolution.
+```python
+run(video_path)
+```
+
+> The execution interface after building the instance.
+> **Parameter**
+>
+> > - video_path (str): path of the video files.
+>
+> **Return Value**
+>
+> > - tuple(str, str): the former is the save path of each frame of the video after super resolution, the latter is the save path of the video after super resolution.
+
+## ppgan.apps.IconVSRPredictor
+
+```python
+ppgan.apps.IconVSRPredictor(output='output', weight_path=None, num_frames=10)
+```
+
+> Build the instance of IconVSR. IconVSR is a VSR model expanded by BasicVSR. For more details, see the paper, BasicVSR: The Search for Essential Components in Video Super-Resolution and Beyond (https://arxiv.org/pdf/2012.02181.pdf). The interface imposes 4x super resolution on the input video. The recommended video format is mp4.
+>
+> **Parameter**
+>
+> ```
+> from ppgan.apps import IconVSRPredictor
+> sr = IconVSRPredictor()
+> # test a video file
+> sr.run("docs/imgs/test.mp4")
+> ```
+> **参数**
+>
+> > - output (str): path of the output image, default: output. Note that the path should be set as output/EDVR.
+> > - weight_path (str): path of the model, default: None,pre-trained integral model will then be automatically downloaded.
+> > - num_frames (int): the number of input frames of the PPMSVSR model, the default value: 10. Note that the larger the num_frames, the better the effect of the video after super resolution.
+```python
+run(video_path)
+```
+
+> The execution interface after building the instance.
+> **Parameter**
+>
+> > - video_path (str): path of the video files.
+>
+> **Return Value**
+>
+> > - tuple(str, str): the former is the save path of each frame of the video after super resolution, the latter is the save path of the video after super resolution.
+
+
+## ppgan.apps.BasiVSRPlusPlusPredictor
+
+```python
+ppgan.apps.BasiVSRPlusPlusPredictor(output='output', weight_path=None, num_frames=10)
+```
+
+> Build the instance of BasiVSRPlusPlus. BasiVSRPlusPlus is a model designed for video super resolution. For more details, see the paper, BasicVSR++: Improving Video Super-Resolution with Enhanced Propagation and Alignment (https://arxiv.org/pdf/2104.13371v1.pdf). The interface imposes 4x super resolution on the input video. The recommended video format is mp4.
+>
+> **Parameter**
+>
+> ```
+> from ppgan.apps import BasiVSRPlusPlusPredictor
+> sr = BasiVSRPlusPlusPredictor()
+> # test a video file
+> sr.run("docs/imgs/test.mp4")
+> ```
+> **参数**
+>
+> > - output (str): path of the output image, default: output. Note that the path should be set as output/EDVR.
+> > - weight_path (str): path of the model, default: None,pre-trained integral model will then be automatically downloaded.
+> > - num_frames (int): the number of input frames of the PPMSVSR model, the default value: 10. Note that the larger the num_frames, the better the effect of the video after super resolution.
+```python
+run(video_path)
+```
+
+> The execution interface after building the instance.
+> **Parameter**
+>
+> > - video_path (str): path of the video files.
+>
+> **Return Value**
+>
+> > - tuple(str, str): the former is the save path of each frame of the video after super resolution, the latter is the save path of the video after super resolution.
+
+
+
+## ppgan.apps.DAINPredictor
+
+```python
+ppgan.apps.DAINPredictor(output='output', weight_path=None,time_step=None, use_gpu=True, key_frame_thread=0,remove_duplicates=False)
+```
+
+> Build the instance of DAIN model. DAIN supports video frame interpolation, producing videos with higher frame rate. For more details, see the paper, DAIN: Depth-Aware Video Frame interpolation (https://arxiv.org/abs/1904.00830).
+>
+> *Note: The interface is only available in static graph, add the following codes to enable static graph before using it:
+>
+> ```
+> import paddle
+> paddle.enable_static() #enable static graph
+> paddle.disable_static() #disable static graph
+> ```
+>
+> **Example**
+>
+> ```
+> from ppgan.apps import DAINPredictor
+> dain = DAINPredictor(time_step=0.5) # With no defualt value, time_step need to be manually specified
+> # test a video file
+> dain.run("docs/imgs/test.mp4")
+> ```
+> **Parameters**
+>
+> > - output_path (str): path of the predicted output, default: output. Note that the path should be set as output/DAIN.
+> > - weight_path (str): path of the model, default: None, pre-trained integral model will then be automatically downloaded.
+> > - time_step (float): the frame rate changes by a factor of 1./time_step, e.g. 2x frames if time_step is 0.5 and 4x frames if it is 0.25.
+> > - use_gpu (bool): whether to make predictions by using GPU, default: True.
+> > - remove_duplicates (bool): whether to remove duplicates, default: False.
+```python
+run(video_path)
+```
+
+> The execution interface after building the instance.
+> **Parameters**
+>
+> > - video_path (str): path of the video file.
+>
+> **Return Value**
+>
+> > - tuple(str, str): for video input, frame_path is the save path of the image after colorizing each frame of the video, and out_path is the save path of the colorized video.
+
+
+## ppgan.apps.FirstOrderPredictor
+
+```python
+ppgan.apps.FirstOrderPredictor(output='output', weight_path=None,config=None, relative=False, adapt_scale=False,find_best_frame=False, best_frame=None)
+```
+
+> Build the instance of FirstOrder model. The model is dedicated to Image Animation, i.e., generating a video sequence so that an object in a source image is animated according to the motion of a driving video.
+>
+> For more details, see paper, First Order Motion Model for Image Animation (https://arxiv.org/abs/2003.00196) .
+>
+> **Example**
+>
+> ```
+> from ppgan.apps import FirstOrderPredictor
+> animate = FirstOrderPredictor()
+> # test a video file
+> animate.run("source.png","driving.mp4")
+> ```
+> **Parameters**
+>
+> > - output_path (str): path of the predicted output, default: output. Note that the path should be set as output/result.mp4.
+> > - weight_path (str): path of the model, default: None, pre-trained integral model will then be automatically downloaded.
+> > - config (dict|str|None): model configuration, it can be a dictionary type or a YML file, and the default value None is adopted. When the weight is None by default, the config also needs to adopt the default value None. otherwise, the configuration here should be consistent with the corresponding weight.
+> > - relative (bool): indicate whether the relative or absolute coordinates of key points in the video are used in the program, default: False.
+> > - adapt_scale (bool): adapt movement scale based on convex hull of key points, default: False.
+> > - find_best_frame (bool): whether to start generating from the frame that best matches the source image, which exclusively applies to face applications and requires libraries with face alignment.
+> > - best_frame (int): set the number of the starting frame, default: None, that is, starting from the first frame(counting from 1).
+```python
+run(source_image,driving_video)
+```
+
+> The execution interface after building the instance, the predicted video is save in output/result.mp4.
+> **Parameters**
+>
+> > - source_image (str): input the source image。
+> > - driving_video (str): input the driving video, mp4 format recommended.
+>
+> **Return Value**
+>
+> > None.
+## ppgan.apps.FaceParsePredictor
+
+```pyhton
+ppgan.apps.FaceParsePredictor(output_path='output')
+```
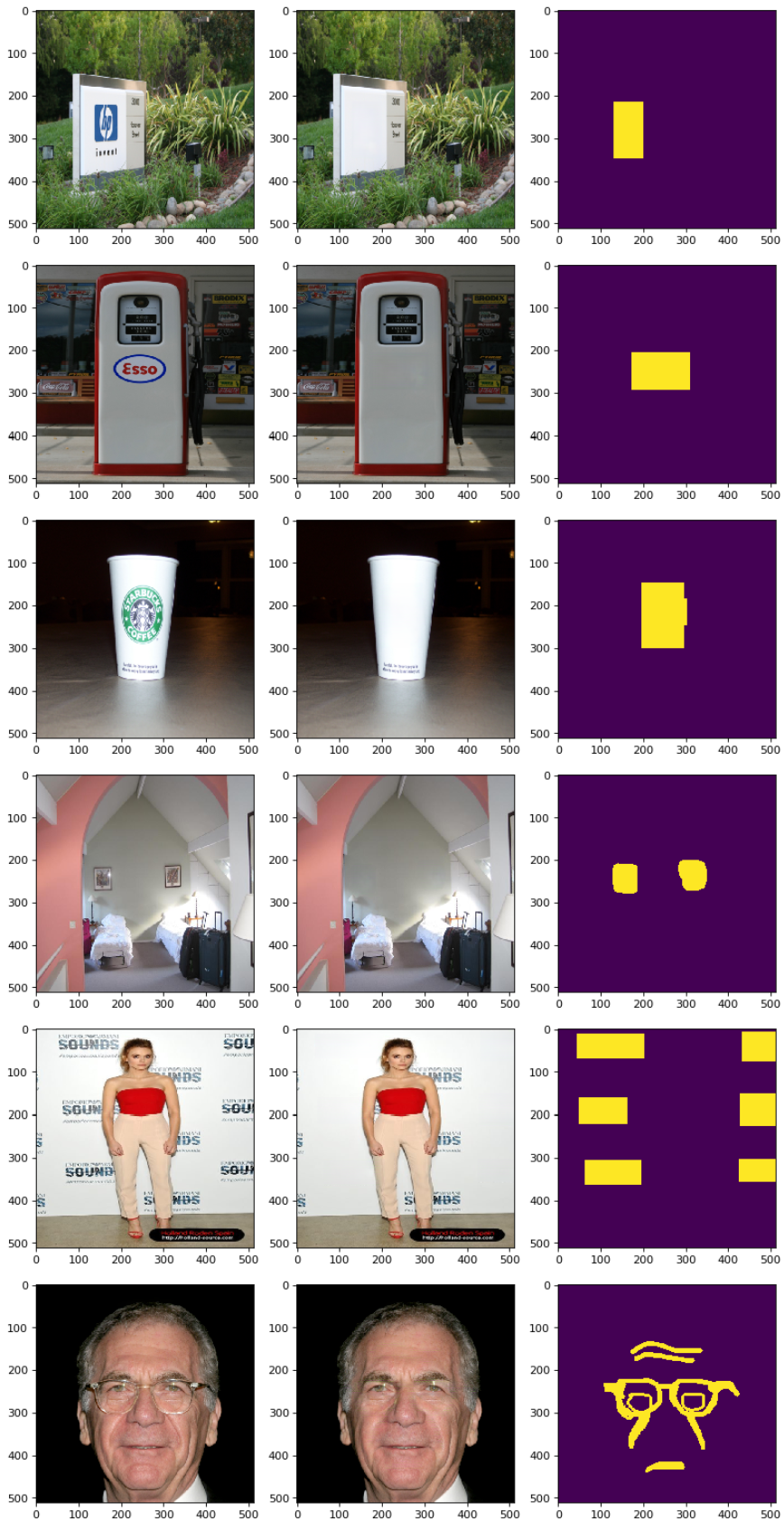
+> Build the instance of the face parsing model. The model is devoted to address the task of distributing a pixel-wise label to each semantic components (e.g. hair, lips, nose, ears, etc.) in accordance with the input facial image. The task proceeds with the help of BiseNet.
+>
+> For more details, see the paper, BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation (https://arxiv.org/abs/1808.00897v1).
+>
+> *Note: dlib package is needed for this interface, use the following codes to install it:
+>
+> ```
+> pip install dlib
+> ```
+> It may take long to install this package under Windows, please be patient.
+>
+> **Parameters:**
+>
+> > - input_image: path of the input image to be parsed
+> > - output_path: path of the output to be saved
+> **Example:**
+>
+> ```
+> from ppgan.apps import FaceParsePredictor
+> parser = FaceParsePredictor()
+> parser.run('docs/imgs/face.png')
+> ```
+> **Return Value:**
+>
+> > - mask(numpy.ndarray): return the mask matrix of the parsed facial components, data type: numpy.ndarray.
+## ppgan.apps.AnimeGANPredictor
+
+```pyhton
+ppgan.apps.AnimeGANPredictor(output_path='output_dir',weight_path=None,use_adjust_brightness=True)
+```
+> Adopt the AnimeGAN v2 to realize the animation of scenery images.
+>
+> For more details, see the paper, AnimeGAN: A Novel Lightweight GAN for Photo Animation (https://link.springer.com/chapter/10.1007/978-981-15-5577-0_18).
+> **Parameters:**
+>
+> > - input_image: path of the input image to be parsed.
+> **Example:**
+>
+> ```
+> from ppgan.apps import AnimeGANPredictor
+> predictor = AnimeGANPredictor()
+> predictor.run('docs/imgs/animeganv2_test.jpg')
+> ```
+> **Return Value:**
+>
+> > - anime_image(numpy.ndarray): return the stylized scenery image.
+
+## ppgan.apps.MiDaSPredictor
+
+```pyhton
+ppgan.apps.MiDaSPredictor(output=None, weight_path=None)
+```
+
+> MiDaSv2 is a monocular depth estimation model (see https://github.com/intel-isl/MiDaS). Monocular depth estimation is a method used to compute depth from a singe RGB image.
+>
+> For more details, see the paper Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer (https://arxiv.org/abs/1907.01341v3).
+> **Example**
+>
+> ```python
+> from ppgan.apps import MiDaSPredictor
+> # if set output, will write depth pfm and png file in output/MiDaS
+> model = MiDaSPredictor()
+> prediction = model.run()
+> ```
+>
+> Color display of the depth image:
+>
+> ```python
+> import numpy as np
+> import PIL.Image as Image
+> import matplotlib as mpl
+> import matplotlib.cm as cm
+>
+> vmax = np.percentile(prediction, 95)
+> normalizer = mpl.colors.Normalize(vmin=prediction.min(), vmax=vmax)
+> mapper = cm.ScalarMappable(norm=normalizer, cmap='magma')
+> colormapped_im = (mapper.to_rgba(prediction)[:, :, :3] * 255).astype(np.uint8)
+> im = Image.fromarray(colormapped_im)
+> im.save('test_disp.jpeg')
+> ```
+>
+> **Parameters:**
+>
+> > - output (str): path of the output, if it is None, no pfm and png depth image will be saved.
+> > - weight_path (str): path of the model, default: None, pre-trained integral model will then be automatically downloaded.
+> **Return Value:**
+>
+> > - prediction (numpy.ndarray): return the prediction.
+> > - pfm_f (str): return the save path of pfm files if the output path is set.
+> > - png_f (str): return the save path of png files if the output path is set.
+
+## ppgan.apps.Wav2LipPredictor
+
+```python
+ppgan.apps.Wav2LipPredictor(face=None, ausio_seq=None, outfile=None)
+```
+
+> Build the instance for the Wav2Lip model, which is used for lip generation, i.e., achieving the synchronization of lip movements on a talking face video and the voice from an input audio.
+>
+> For more details, see the paper, A Lip Sync Expert Is All You Need for Speech to Lip Generation In the Wild (http://arxiv.org/abs/2008.10010).
+>
+> **Example**
+>
+> ```
+> from ppgan.apps import Wav2LipPredictor
+> import ppgan
+> predictor = Wav2LipPredictor()
+> predictor.run('/home/aistudio/先烈.jpeg', '/home/aistudio/pp_guangquan_zhenzhu46s.mp4','wav2lip')
+> ```
+> **Parameters:**
+> - face (str): path of images or videos containing human face.
+> - audio_seq (str): path of the input audio, any processable format in ffmpeg is supported, including `.wav`, `.mp3`, `.m4a` etc.
+> - outfile (str): path of the output video file.
+>**Return Value**
+>
+>> None
diff --git a/docs/en_US/config_doc.md b/docs/en_US/config_doc.md
new file mode 100644
index 0000000000000000000000000000000000000000..a4f3f7065357935f8b915b0b72bd0deed947f862
--- /dev/null
+++ b/docs/en_US/config_doc.md
@@ -0,0 +1,77 @@
+# Instruction of Config Files
+
+## Introduction of Parameters
+
+Take`lapstyle_rev_first.yaml` as an example.
+
+### Global
+
+| Field | Usage | Default |
+| ------------------------- | :------------------------- | --------------- |
+| total_iters | total training steps | 30000 |
+| min_max | numeric range of tensor(for image storage) | (0., 1.) |
+| output_dir | path of the output | ./output_dir |
+| snapshot_config: interval | interval for saving model parameters | 5000 |
+
+### Model
+
+| Field | Usage | Default |
+| :---------------------- | -------- | ------ |
+| name | name of the model | LapStyleRevFirstModel |
+| revnet_generator | set the revnet generator | RevisionNet |
+| revnet_discriminator | set the revnet discriminator | LapStyleDiscriminator |
+| draftnet_encode | set the draftnet encoder | Encoder |
+| draftnet_decode | set the draftnet decoder | DecoderNet |
+| calc_style_emd_loss | set the style loss 1 | CalcStyleEmdLoss |
+| calc_content_relt_loss | set the content loss 1 | CalcContentReltLoss |
+| calc_content_loss | set the content loss 2 | CalcContentLoss |
+| calc_style_loss | set the style loss 2 | CalcStyleLoss |
+| gan_criterion: name | set the GAN loss | GANLoss |
+| gan_criterion: gan_mode | set the modal parameter of GAN loss | vanilla |
+| content_layers | set the network layer that calculates content loss 2 |['r11', 'r21', 'r31', 'r41', 'r51']|
+| style_layers | set the network layer that calculates style loss 2 | ['r11', 'r21', 'r31', 'r41', 'r51'] |
+| content_weight | set the weight of total content loss | 1.0 |
+| style_weigh | set the weight of total style loss | 3.0 |
+
+### Dataset (train & test)
+
+| Field | Usage | Default |
+| :----------- | -------------------- | -------------------- |
+| name | name of the dataset | LapStyleDataset |
+| content_root | path of the dataset | data/coco/train2017/ |
+| style_root | path of the target style image | data/starrynew.png |
+| load_size | image size after resizing the input image | 280 |
+| crop_size | image size after random cropping | 256 |
+| num_workers | number of worker process | 16 |
+| batch_size | size of the data sample for one training session | 5 |
+
+### Lr_scheduler
+
+| Field | Usage | Default |
+| :------------ | ---------------- | -------------- |
+| name | name of the learning strategy | NonLinearDecay |
+| learning_rate | initial learning rate | 1e-4 |
+| lr_decay | decay rate of the learning rate | 5e-5 |
+
+### Optimizer
+
+| Field | Usage | Default |
+| :-------- | ---------- | ------- |
+| name | class name of the optimizer | Adam |
+| net_names | the network under the optimizer | net_rev |
+| beta1 | set beta1, parameter of the optimizer | 0.9 |
+| beta2 | set beta2, parameter of the optimizer | 0.999 |
+
+### Validate
+
+| Field | Usage | Default |
+| :------- | ---- | ------ |
+| interval | validation interval | 500 |
+| save_img | whether to save image while validating | false |
+
+### Log_config
+
+| Field | Usage | Default |
+| :--------------- | ---- | ------ |
+| interval | log printing interval | 10 |
+| visiual_interval | interval for saving the generated images during training | 500 |
diff --git a/docs/en_US/data_prepare.md b/docs/en_US/data_prepare.md
index 7fde7c98b1d3e53df2547b85d2b5028695e98c65..be8589b8d8173395ab26449e73cd120b1e3ea82f 100644
--- a/docs/en_US/data_prepare.md
+++ b/docs/en_US/data_prepare.md
@@ -1,6 +1,8 @@
-## Data prepare
+## Data Preparation
-The config will suppose your data put in `$PaddleGAN/data`. You can symlink your datasets to `$PaddleGAN/data`.
+## **1. Routes Configuration of Datasets**
+
+The config will suppose your data is in `$PaddleGAN/data`. You can symlink your datasets to `$PaddleGAN/data`.
```
PaddleGAN
@@ -28,7 +30,7 @@ PaddleGAN
```
-If you put your datasets on other place,for example ```your/data/path```, you can also change ```dataroot``` in config file:
+If you put the datasets on other place,for example ```your/data/path```, you can also change ```dataroot``` in config file:
```
dataset:
@@ -38,22 +40,30 @@ dataset:
num_workers: 4
```
-### Datasets of CycleGAN
+## 2. Datasets Preparation
+
+### 2.1 Download of Datasets
+
+#### 2.1.1 Datasets of CycleGAN
+
+- #### Download from website
-#### download form website
-Datasets for CycleGAN can be downloaded from [here](https://people.eecs.berkeley.edu/~taesung_park/CycleGAN/datasets/)
+Datasets of CycleGAN can be downloaded from [here](https://people.eecs.berkeley.edu/~taesung_park/CycleGAN/datasets/), remember to symlink your datasets to `$PaddleGAN/data`.
-#### download by script
+- #### Download by script
-You can use ```download_cyclegan_data.py``` in ```PaddleGAN/data``` to download datasets you wanted. Supported datasets are: apple2orange, summer2winter_yosemite,horse2zebra, monet2photo, cezanne2photo, ukiyoe2photo, vangogh2photo, maps, cityscapes, facades, iphone2dslr_flower, ae_photos, cityscapes。
+
+You can use ```download_cyclegan_data.py``` in ```PaddleGAN/data``` to download datasets you wanted.
+
+Supported datasets are: apple2orange, summer2winter_yosemite,horse2zebra, monet2photo, cezanne2photo, ukiyoe2photo, vangogh2photo, maps, cityscapes, facades, iphone2dslr_flower, ae_photos, cityscapes。
run following command. Dataset will be downloaded to ```~/.cache/ppgan``` and symlink to ```PaddleGAN/data/``` .
```
python data/download_cyclegan_data.py --name horse2zebra
```
-#### custom dataset
+#### Custom dataset
Data should be arranged in following way if you use custom dataset.
@@ -65,13 +75,15 @@ custom_datasets
└── trainB
```
-### Datasets of Pix2Pix
+#### 2.1.2 Datasets of Pix2Pix
+
+- #### Download from website
-#### Download from website
Dataset for pix2pix can be downloaded from [here](https://people.eecs.berkeley.edu/~tinghuiz/projects/pix2pix/datasets/)
-#### Download by script
+- #### Download by script
+
You can use ```download_pix2pix_data.py``` in ```PaddleGAN/data``` to download datasets you wanted. Supported datasets are: apple2orange, summer2winter_yosemite,horse2zebra, monet2photo, cezanne2photo, ukiyoe2photo, vangogh2photo, maps, cityscapes, facades, iphone2dslr_flower, ae_photos, cityscapes.
@@ -82,7 +94,7 @@ python data/download_pix2pix_data.py --name cityscapes
```
#### Custom datasets
-Data should be arranged in following way if you use custom dataset. And image content shoubld be same with example image.
+Data should be arranged in following way if you use custom dataset. And image content should be the same with example image.
```
facades
diff --git a/docs/en_US/get_started.md b/docs/en_US/get_started.md
index 5a3fe7cd5e7dfbd3e80609bb918b78894d0e1da4..85de5fb56a26e630aad35d74a1e835ff39275f76 100644
--- a/docs/en_US/get_started.md
+++ b/docs/en_US/get_started.md
@@ -1,28 +1,63 @@
-## Getting started with PaddleGAN
+# Quick Start
-Note:
-* Before starting to use PaddleGAN, please make sure you have read the [install document](./install_en.md), and prepare the dataset according to the [data preparation document](./data_prepare_en.md)
-* The following tutorial uses the train and evaluate of the CycleGAN model on the Cityscapes dataset as an example
+PaddleGAN is a PaddlePaddle Generative Adversarial Network (GAN) development kit that provides a high-performance replication of a variety of classical networks with applications covering a wide range of areas such as image generation, style migration, ainimation driving, image/video super resolution and colorization.
-### Train
+This section will teach you how to quickly get started with PaddleGAN, using the train and evaluate of the CycleGAN model on the Cityscapes dataset as an example.
+
+Note that all model configuration files in PaddleGAN are available at [. /PaddleGAN/configs](https://github.com/PaddlePaddle/PaddleGAN/tree/develop/configs).
+
+## Contents
+
+* [Installation](#Installation)
+* [Data preparation](#Data-preparation)
+* [Training](#Trianing)
+ * [Single Card Training](#Single-Card-Training)
+ * [Parameters](#Parameters)
+ * [Visualize Training](#Visualize-Training)
+ * [Resume Training](#Resume-Training)
+ * [Multi-Card Training](#Multi-Card-Training)
+* [Evaluation](#Evaluation)
+
+## Installation
+
+For installation and configuration of the runtime environment, please refer to the [installation documentation](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/en_US/install.md) to complete the installation of PaddlePaddle and PaddleGAN.
+
+In this demo, it is assumed that the user cloned and placed the code of PaddleGAN in the '/home/paddle' directory. The user executes the command operations in the '/home/paddle/PaddleGAN' directory.
+
+## Data preparation
+
+Prepare the Cityscapes dataset according to the [data preparation](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/en_US/data_prepare.md).
+
+Download the Cityscapes dataset to ~/.cache/ppgan and softlink to PaddleGAN/data/ using the following script.
-#### Train with single gpu
```
-python -u tools/main.py --config-file configs/cyclegan_cityscapes.yaml
+python data/download_cyclegan_data.py --name cityscapes
```
-#### Args
+## Trianing
-- `--config-file (str)`: path of config file。
+### 1. Single Card Training
-The output log, weight, and visualization result will be saved in ```./output_dir``` by default, which can be modified by the ```output_dir``` parameter in the config file:
```
- output_dir: output_dir
+ python -u tools/main.py --config-file configs/cyclegan_cityscapes.yaml
```
+#### Parameters
+
+* `--config-file (str)`: path to the config file. This is the configuration file used here for CycleGAN training on the Cityscapes dataset.
+
+* The output logs, weights, and visualization results are saved by default in `. /output_dir`, which can be modified by the `output_dir` parameter in the configuration file:
+ ```
+ output_dir: output_dir
+ ```
+
+
+

+
+

+
+

+
+

+
| CUDA | python3.8 | python3.7 | python3.6 | | 10.1 | install python -m pip install https://paddle-wheel.bj.bcebos.com/2.0.0-rc0-gpu-cuda10.1-cudnn7-mkl_gcc8.2%2Fpaddlepaddle_gpu-2.0.0rc0.post101-cp38-cp38-linux_x86_64.whl
-
| install python -m pip install https://paddle-wheel.bj.bcebos.com/2.0.0-rc0-gpu-cuda10.1-cudnn7-mkl_gcc8.2%2Fpaddlepaddle_gpu-2.0.0rc0.post101-cp37-cp37m-linux_x86_64.whl
-
| install python -m pip install https://paddle-wheel.bj.bcebos.com/2.0.0-rc0-gpu-cuda10.1-cudnn7-mkl_gcc8.2%2Fpaddlepaddle_gpu-2.0.0rc0.post101-cp36-cp36m-linux_x86_64.whl
-
| |
| 10.0 | install python -m pip install https://paddle-wheel.bj.bcebos.com/2.0.0-rc0-gpu-cuda10-cudnn7-mkl%2Fpaddlepaddle_gpu-2.0.0rc0.post100-cp38-cp38-linux_x86_64.whl
-
| install python -m pip install https://paddle-wheel.bj.bcebos.com/2.0.0-rc0-gpu-cuda10-cudnn7-mkl%2Fpaddlepaddle_gpu-2.0.0rc0.post100-cp37-cp37m-linux_x86_64.whl
-
| install python -m pip install https://paddle-wheel.bj.bcebos.com/2.0.0-rc0-gpu-cuda10-cudnn7-mkl%2Fpaddlepaddle_gpu-2.0.0rc0.post100-cp36-cp36m-linux_x86_64.whl
-
| |
| 9.0 | install python -m pip install https://paddle-wheel.bj.bcebos.com/2.0.0-rc0-gpu-cuda9-cudnn7-mkl%2Fpaddlepaddle_gpu-2.0.0rc0.post90-cp38-cp38-linux_x86_64.whl
-
| install python -m pip install https://paddle-wheel.bj.bcebos.com/2.0.0-rc0-gpu-cuda9-cudnn7-mkl%2Fpaddlepaddle_gpu-2.0.0rc0.post90-cp37-cp37m-linux_x86_64.whl
-
| install python -m pip install https://paddle-wheel.bj.bcebos.com/2.0.0-rc0-gpu-cuda9-cudnn7-mkl%2Fpaddlepaddle_gpu-2.0.0rc0.post90-cp36-cp36m-linux_x86_64.whl
-
|
+Make sure that your PaddlePaddle is successfully installed in the required or higher version, and then please use the following command to verify.
-Visit home page of [paddlepaddle](https://www.paddlepaddle.org.cn/install/quick) for support of other systems, such as Windows10.
+```
+# verify that PaddlePaddle is installed successfully in your Python interpreter
+>>> import paddle
+>>> paddle.utils.run_check()
-### 2. Install paddleGAN
+# Confirm PaddlePaddle version
+python -c "import paddle; print(paddle.__version__)"
+```
-#### 2.1 Install through pip
+### Install PaddleGAN
+
+#### 1. Install via PIP (only Python3 is available)
+
+* Install
```
-# only support Python3
python3 -m pip install --upgrade ppgan
```
-Download the examples and configuration files via cloning the source code:
+* Download the examples and configuration files via cloning the source code:
```
git clone https://github.com/PaddlePaddle/PaddleGAN
cd PaddleGAN
```
-#### 2.2 Install through source code
+#### 2. Install via source code
```
git clone https://github.com/PaddlePaddle/PaddleGAN
cd PaddleGAN
+
pip install -v -e . # or "python setup.py develop"
+
+# Install other dependencies
+pip install -r requirements.txt
```
-### 4. Installation of other tools that may be used
+### Other Third-Party Tool Installation
-#### 4.1 ffmpeg
+#### 1. ffmpeg
-If you need to use ppgan to handle video-related tasks, you need to install ffmpeg. It is recommended that you use [conda](https://docs.conda.io/en/latest/miniconda.html) to install:
+All tasks involving video require `ffmpeg` to be installed, here we recommend using conda
```
conda install x264=='1!152.20180717' ffmpeg=4.0.2 -c conda-forge
```
-#### 4.2 Visual DL
-If you want to use [PaddlePaddle VisualDL](https://github.com/PaddlePaddle/VisualDL) to monitor the training process, Please install `VisualDL`(For more detail refer [here](./get_started.md)):
+#### 2. VisualDL
+If you want to use [PaddlePaddle VisualDL](https://github.com/PaddlePaddle/VisualDL) to visualize the training process, Please install `VisualDL`(For more detail refer [here](./get_started.md)):
```
python -m pip install visualdl -i https://mirror.baidu.com/pypi/simple
```
+
+*Note: Only versions installed under Python 3 or higher are maintained by VisualDL officially.
diff --git a/docs/en_US/tutorials/animegan.md b/docs/en_US/tutorials/animegan.md
index 38aaaf349f9330303dfb328cbf20cf5505f5f723..d216719e147ee77852846a777ba26035643c8c41 100644
--- a/docs/en_US/tutorials/animegan.md
+++ b/docs/en_US/tutorials/animegan.md
@@ -70,7 +70,7 @@ animedataset
2. After the warmup, we strat to training GAN.:
**NOTE:** you must modify the `configs/animeganv2.yaml > pretrain_ckpt ` parameter first! ensure the GAN can reuse the warmup generator model.
- Set the `batch size=4` and the `learning rate=0.00002`. Train 30 epochs on a GTX2060S GPU to reproduce the result. For other hyperparameters, please refer to `configs/animeganv2.yaml`.
+ Set the `batch size=4` and the `learning rate=0.0002`. Train 30 epochs on a GTX2060S GPU to reproduce the result. For other hyperparameters, please refer to `configs/animeganv2.yaml`.
```sh
python tools/main.py --config-file configs/animeganv2.yaml
```
diff --git a/docs/en_US/tutorials/aotgan.md b/docs/en_US/tutorials/aotgan.md
new file mode 100644
index 0000000000000000000000000000000000000000..9d0c3609ed359e9ed1586fccfb24f9d1db8ddae4
--- /dev/null
+++ b/docs/en_US/tutorials/aotgan.md
@@ -0,0 +1,89 @@
+# AOT GAN
+
+## 1 Principle
+
+ The Aggregated COntextual-Transformation GAN (AOT-GAN) is for high-resolution image inpainting.The AOT blocks aggregate contextual
+transformations from various receptive fields, allowing to capture both informative distant image contexts and rich patterns of interest
+for context reasoning.
+
+
+
+**Paper:** [Aggregated Contextual Transformations for High-Resolution Image Inpainting](https://paperswithcode.com/paper/aggregated-contextual-transformations-for)
+
+**Official Repo:** [https://github.com/megvii-research/NAFNet](https://github.com/megvii-research/NAFNet)
+
+
+## 2 How to use
+
+### 2.1 Prediction
+
+Download pretrained generator weights from: (https://paddlegan.bj.bcebos.com/models/AotGan_g.pdparams)
+
+```
+python applications/tools/aotgan.py \
+ --input_image_path data/aotgan/armani1.jpg \
+ --input_mask_path data/aotgan/armani1.png \
+ --weight_path test/aotgan/g.pdparams \
+ --output_path output_dir/armani_pred.jpg \
+ --config-file configs/aotgan.yaml
+```
+Parameters:
+* input_image_path:input image
+* input_mask_path:input mask
+* weight_path:pretrained generator weights
+* output_path:predicted image
+* config-file:yaml file,same with the training process
+
+AI Studio Project:(https://aistudio.baidu.com/aistudio/datasetdetail/165081)
+
+### 2.2 Train
+
+Data Preparation:
+
+The pretained model uses 'Place365Standard' and 'NVIDIA Irregular Mask' as its training datasets. You can download then from ([Place365Standard](http://places2.csail.mit.edu/download.html)) and ([NVIDIA Irregular Mask Dataset](https://nv-adlr.github.io/publication/partialconv-inpainting)).
+
+```
+└─data
+ └─aotgan
+ ├─train_img
+ ├─train_mask
+ ├─val_img
+ └─val_mask
+```
+Train(Single Card):
+
+`python -u tools/main.py --config-file configs/aotgan.yaml`
+
+Train(Mult-Card):
+
+```
+!python -m paddle.distributed.launch \
+ tools/main.py \
+ --config-file configs/photopen.yaml \
+ -o dataset.train.batch_size=6
+```
+Train(continue):
+
+```
+python -u tools/main.py \
+ --config-file configs/aotgan.yaml \
+ --resume output_dir/[path_to_checkpoint]/iter_[iternumber]_checkpoint.pdparams
+```
+
+# Results
+
+On Places365-Val Dataset
+
+| mask | PSNR | SSIM | download |
+| ---- | ---- | ---- | ---- |
+| 20-30% | 26.04001 | 0.89011 | [download](https://paddlegan.bj.bcebos.com/models/AotGan_g.pdparams) |
+
+# References
+
+@inproceedings{yan2021agg,
+ author = {Zeng, Yanhong and Fu, Jianlong and Chao, Hongyang and Guo, Baining},
+ title = {Aggregated Contextual Transformations for High-Resolution Image Inpainting},
+ booktitle = {Arxiv},
+ pages={-},
+ year = {2020}
+}
diff --git a/docs/en_US/tutorials/face_enhancement.md b/docs/en_US/tutorials/face_enhancement.md
new file mode 100644
index 0000000000000000000000000000000000000000..318c010483fdd7b29ffaa7f6c88f5000f9994672
--- /dev/null
+++ b/docs/en_US/tutorials/face_enhancement.md
@@ -0,0 +1,43 @@
+# Face Enhancement
+
+## 1. face enhancement introduction
+
+Blind face restoration (BFR) from severely degraded face images in the wild is a very challenging problem. Due to the high illness of the problem and the complex unknown degradation, directly training a deep neural network (DNN) usually cannot lead to acceptable results. Existing generative adversarial network (GAN) based methods can produce better results but tend to generate over-smoothed restorations. Here we provide the [GPEN](https://arxiv.org/abs/2105.06070) model. GPEN was proposed by first learning a GAN for high-quality face image generation and embedding it into a U-shaped DNN as a prior decoder, then fine-tuning the GAN prior embedded DNN with a set of synthesized low-quality face images. The GAN blocks are designed to ensure that the latent code and noise input to the GAN can be respectively generated from the deep and shallow features of the DNN, controlling the global face structure, local face details and background of the reconstructed image. The proposed GAN prior embedded network (GPEN) is easy-to-implement, and it can generate visually photo-realistic results. Experiments demonstrated that the proposed GPEN achieves significantly superior results to state-of-the-art BFR methods both quantitatively and qualitatively, especially for the restoration of severely degraded face images in the wild.
+
+## How to use
+
+### face enhancement
+
+The user could use the following command to do face enhancement and select the local image as input:
+
+```python
+import paddle
+from ppgan.faceutils.face_enhancement import FaceEnhancement
+
+faceenhancer = FaceEnhancement()
+img = faceenhancer.enhance_from_image(img)
+```
+
+Note: please convert the image to float type, currently does not support int8 type.
+
+### Train (TODO)
+
+In the future, training scripts will be added to facilitate users to train more types of GPEN.
+
+## Results
+
+
+
+## Reference
+
+```
+@inproceedings{inproceedings,
+author = {Yang, Tao and Ren, Peiran and Xie, Xuansong and Zhang, Lei},
+year = {2021},
+month = {06},
+pages = {672-681},
+title = {GAN Prior Embedded Network for Blind Face Restoration in the Wild},
+doi = {10.1109/CVPR46437.2021.00073}
+}
+
+```
diff --git a/docs/en_US/tutorials/face_parse.md b/docs/en_US/tutorials/face_parse.md
index 3bf4acbd5d489e5a2cdce1426a4377cb44a1939d..8f21b8138cd974b32efdba8dad849f4247990675 100644
--- a/docs/en_US/tutorials/face_parse.md
+++ b/docs/en_US/tutorials/face_parse.md
@@ -12,7 +12,7 @@ Runing the following command to complete the face parsing task. The output resul
```
cd applications
-python face_parse.py --input_image ../docs/imgs/face.png
+python tools/face_parse.py --input_image ../docs/imgs/face.png
```
**params:**
diff --git a/docs/en_US/tutorials/gfpgan.md b/docs/en_US/tutorials/gfpgan.md
new file mode 100644
index 0000000000000000000000000000000000000000..d4ca57bff64ca288159dff41720fb65df91a3442
--- /dev/null
+++ b/docs/en_US/tutorials/gfpgan.md
@@ -0,0 +1,207 @@
+## GFPGAN Blind Face Restoration Model
+
+
+
+## 1、Introduction
+
+GFP-GAN that leverages rich and diverse priors encapsulated in a pretrained face GAN for blind face restoration.
+### Overview of GFP-GAN framework:
+
+
+
+GFP-GAN is comprised of a degradation removal
+module (U-Net) and a pretrained face GAN (such as StyleGAN2) as prior. They are bridged by a latent code
+mapping and several Channel-Split Spatial Feature Transform (CS-SFT) layers.
+
+By dealing with features, it achieving realistic results while preserving high fidelity.
+
+For a more detailed introduction to the model, and refer to the repo, you can view the following AI Studio project
+[https://aistudio.baidu.com/aistudio/projectdetail/4421649](https://aistudio.baidu.com/aistudio/projectdetail/4421649)
+
+In this experiment, We train
+our model with Adam optimizer for a total of 210k iterations.
+
+The result of experiments of recovering of GFPGAN as following:
+
+Model | LPIPS | FID | PSNR
+--- |:---:|:---:|:---:|
+GFPGAN | 0.3817 | 36.8068 | 65.0461
+
+## 2、Ready to work
+
+### 2.1 Dataset Preparation
+
+The GFPGAN model training set is the classic FFHQ face data set,
+with a total of 70,000 high-resolution 1024 x 1024 high-resolution face pictures,
+and the test set is the CELEBA-HQ data set, with a total of 2,000 high-resolution face pictures. The generation way is the same as that during training.
+For details, please refer to **Dataset URL:** [FFHQ](https://github.com/NVlabs/ffhq-dataset), [CELEBA-HQ](https://github.com/tkarras/progressive_growing_of_gans).
+The specific download links are given below:
+
+**Original dataset download address:**
+
+**FFHQ :** https://drive.google.com/drive/folders/1tZUcXDBeOibC6jcMCtgRRz67pzrAHeHL?usp=drive_open
+
+**CELEBA-HQ:** https://drive.google.com/drive/folders/0B4qLcYyJmiz0TXY1NG02bzZVRGs?resourcekey=0-arAVTUfW9KRhN-irJchVKQ&usp=sharing
+
+The structure of data as following
+
+```
+|-- data/GFPGAN
+ |-- train
+ |-- 00000.png
+ |-- 00001.png
+ |-- ......
+ |-- 00999.png
+ |-- ......
+ |-- 69999.png
+ |-- lq
+ |-- 2000张jpg图片
+ |-- gt
+ |-- 2000张jpg图片
+```
+
+
+Please modify the dataroot parameters of dataset train and test in the configs/gfpgan_ffhq1024.yaml configuration file to your training set and test set path.
+
+
+### 2.2 Model preparation
+
+**Model parameter file and training log download address:**
+
+https://paddlegan.bj.bcebos.com/models/GFPGAN.pdparams
+
+Download the model parameters and test images from the link and put them in the data/ folder in the project root directory. The specific file structure is as follows:
+
+the params is a dict(one type in python),and could be load by paddlepaddle. It contains key (net_g,net_g_ema),you can use any of one to inference
+
+## 3、Start using
+
+### 3.1 model training
+
+Enter the following code in the console to start training:
+
+ ```bash
+ python tools/main.py -c configs/gfpgan_ffhq1024.yaml
+ ```
+
+The model supports single-card training and multi-card training.So you can use this bash to train
+
+ ```bash
+!CUDA_VISIBLE_DEVICES=0,1,2,3
+!python -m paddle.distributed.launch tools/main.py \
+ --config-file configs/gpfgan_ffhq1024.yaml
+ ```
+
+Model training needs to use paddle2.3 and above, and wait for paddle to implement the second-order operator related functions of elementwise_pow. The paddle2.2.2 version can run normally, but the model cannot be successfully trained because some loss functions will calculate the wrong gradient. . If an error is reported during training, training is not supported for the time being. You can skip the training part and directly use the provided model parameters for testing. Model evaluation and testing can use paddle2.2.2 and above.
+
+
+
+### 3.2 Model evaluation
+
+When evaluating the model, enter the following code in the console, using the downloaded model parameters mentioned above:
+
+ ```shell
+python tools/main.py -c configs/gfpgan_ffhq1024.yaml --load GFPGAN.pdparams --evaluate-only
+ ```
+
+If you want to test on your own provided model, please modify the path after --load .
+
+
+
+### 3.3 Model prediction
+
+#### 3.3.1 Export model
+
+After training, you need to use ``tools/export_model.py`` to extract the weights of the generator from the trained model (including the generator only)
+Enter the following command to extract the model of the generator:
+
+```bash
+python -u tools/export_model.py --config-file configs/gfpgan_ffhq1024.yaml \
+ --load GFPGAN.pdparams \
+ --inputs_size 1,3,512,512
+```
+
+
+#### 3.3.2 Process a single image
+
+You can use our tools in ppgan/faceutils/face_enhancement/gfpgan_enhance.py to inferences one picture quickly
+```python
+%env PYTHONPATH=.:$PYTHONPATH
+%env CUDA_VISIBLE_DEVICES=0
+import paddle
+import cv2
+import numpy as np
+import sys
+from ppgan.faceutils.face_enhancement.gfpgan_enhance import gfp_FaceEnhancement
+# you can use your path
+img_path='test/2.png'
+img = cv2.imread(img_path, cv2.IMREAD_COLOR)
+# this is origin picture
+cv2.imwrite('test/outlq.png',img)
+img=np.array(img).astype('float32')
+faceenhancer = gfp_FaceEnhancement()
+img = faceenhancer.enhance_from_image(img)
+# the result of prediction
+cv2.imwrite('test/out_gfpgan.png',img)
+```
+
+
+
+
+
+
+
+## 4. Tipc
+
+### 4.1 Export the inference model
+
+```bash
+python -u tools/export_model.py --config-file configs/gfpgan_ffhq1024.yaml \
+ --load GFPGAN.pdparams \
+ --inputs_size 1,3,512,512
+```
+
+You can also modify the parameters after --load to the model parameter file you want to test.
+
+
+
+### 4.2 Inference with a prediction engine
+
+```bash
+%cd /home/aistudio/work/PaddleGAN
+# %env PYTHONPATH=.:$PYTHONPATH
+# %env CUDA_VISIBLE_DEVICES=0
+!python -u tools/inference.py --config-file configs/gfpgan_ffhq1024.yaml \
+ --model_path GFPGAN.pdparams \
+ --model_type gfpgan \
+ --device gpu \
+ -o validate=None
+```
+
+
+### 4.3 Call the script to complete the training and push test in two steps
+
+To invoke the `lite_train_lite_infer` mode of the foot test base training prediction function, run:
+
+```bash
+%cd /home/aistudio/work/PaddleGAN
+!bash test_tipc/prepare.sh \
+ test_tipc/configs/GFPGAN/train_infer_python.txt \
+ lite_train_lite_infer
+!bash test_tipc/test_train_inference_python.sh \
+ test_tipc/configs/GFPGAN/train_infer_python.txt \
+ lite_train_lite_infer
+```
+
+
+
+## 5、References
+
+```
+@InProceedings{wang2021gfpgan,
+ author = {Xintao Wang and Yu Li and Honglun Zhang and Ying Shan},
+ title = {Towards Real-World Blind Face Restoration with Generative Facial Prior},
+ booktitle={The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
+ year = {2021}
+}
+```
diff --git a/docs/en_US/tutorials/gpen.md b/docs/en_US/tutorials/gpen.md
new file mode 100644
index 0000000000000000000000000000000000000000..0384a44784792c64960dad1a94175f9c58e0952a
--- /dev/null
+++ b/docs/en_US/tutorials/gpen.md
@@ -0,0 +1,202 @@
+English | [Chinese](../../zh_CN/tutorials/gpen.md)
+
+## GPEN Blind Face Restoration Model
+
+
+## 1、Introduction
+
+The GPEN model is a blind face restoration model. The author embeds the decoder of StyleGAN V2 proposed by the previous model as the decoder of GPEN; reconstructs a simple encoder with DNN to provide input for the decoder. In this way, while retaining the excellent performance of the StyleGAN V2 decoder, the function of the model is changed from image style conversion to blind face restoration. The overall structure of the model is shown in the following figure:
+
+
+
+For a more detailed introduction to the model, and refer to the repo, you can view the following AI Studio project [link]([GPEN Blind Face Repair Model Reproduction - Paddle AI Studio (baidu.com)](https://aistudio.baidu.com/ The latest version of aistudio/projectdetail/3936241?contributionType=1)).
+
+
+
+
+## 2、Ready to work
+
+### 2.1 Dataset Preparation
+
+The GPEN model training set is the classic FFHQ face data set, with a total of 70,000 high-resolution 1024 x 1024 high-resolution face pictures, and the test set is the CELEBA-HQ data set, with a total of 2,000 high-resolution face pictures. For details, please refer to **Dataset URL:** [FFHQ](https://github.com/NVlabs/ffhq-dataset), [CELEBA-HQ](https://github.com/tkarras/progressive_growing_of_gans). The specific download links are given below:
+
+**Original dataset download address:**
+
+**FFHQ :** https://drive.google.com/drive/folders/1tZUcXDBeOibC6jcMCtgRRz67pzrAHeHL?usp=drive_open
+
+**CELEBA-HQ:** https://drive.google.com/drive/folders/0B4qLcYyJmiz0TXY1NG02bzZVRGs?resourcekey=0-arAVTUfW9KRhN-irJchVKQ&usp=sharing
+
+
+
+Since the original FFHQ dataset is too large, you can also download the 256-resolution FFHQ dataset from the following link:
+
+https://paddlegan.bj.bcebos.com/datasets/images256x256.tar
+
+
+
+**After downloading, the file organization is as follows**
+
+```
+|-- data/GPEN
+ |-- ffhq/images256x256/
+ |-- 00000
+ |-- 00000.png
+ |-- 00001.png
+ |-- ......
+ |-- 00999.png
+ |-- 01000
+ |-- ......
+ |-- ......
+ |-- 69000
+ |-- ......
+ |-- 69999.png
+ |-- test
+ |-- 2000张png图片
+```
+
+Please modify the dataroot parameters of dataset train and test in the configs/gpen_256_ffhq.yaml configuration file to your training set and test set path.
+
+
+
+### 2.2 Model preparation
+
+**Model parameter file and training log download address:**
+
+link:https://paddlegan.bj.bcebos.com/models/gpen.zip
+
+
+Download the model parameters and test images from the link and put them in the data/ folder in the project root directory. The specific file structure is as follows:
+
+
+```
+data/gpen/weights
+ |-- model_ir_se50.pdparams
+ |-- weight_pretrain.pdparams
+data/gpen/lite_data
+```
+
+
+
+## 3、Start using
+
+### 3.1 model training
+
+Enter the following code in the console to start training:
+
+ ```shell
+ python tools/main.py -c configs/gpen_256_ffhq.yaml
+ ```
+
+The model only supports single-card training.
+
+Model training needs to use paddle2.3 and above, and wait for paddle to implement the second-order operator related functions of elementwise_pow. The paddle2.2.2 version can run normally, but the model cannot be successfully trained because some loss functions will calculate the wrong gradient. . If an error is reported during training, training is not supported for the time being. You can skip the training part and directly use the provided model parameters for testing. Model evaluation and testing can use paddle2.2.2 and above.
+
+
+
+### 3.2 Model evaluation
+
+When evaluating the model, enter the following code in the console, using the downloaded model parameters mentioned above:
+
+ ```shell
+python tools/main.py -c configs/gpen_256_ffhq.yaml -o dataset.test.amount=2000 --load data/gpen/weights/weight_pretrain.pdparams --evaluate-only
+ ```
+
+If you want to test on your own provided model, please modify the path after --load .
+
+
+
+### 3.3 Model prediction
+
+#### 3.3.1 Export generator weights
+
+After training, you need to use ``tools/extract_weight.py`` to extract the weights of the generator from the trained model (including the generator and discriminator) for inference to `applications/tools/gpen.py` to achieve Various applications of the GPEN model. Enter the following command to extract the weights of the generator:
+
+```bash
+python tools/extract_weight.py data/gpen/weights/weight_pretrain.pdparams --net-name g_ema --output data/gpen/weights/g_ema.pdparams
+```
+
+
+
+#### 3.3.2 Process a single image
+
+After extracting the weights of the generator, enter the following command to test the images under the --test_img path. Modifying the --seed parameter can generate different degraded images to show richer effects. You can modify the path after --test_img to any image you want to test. If no weight is provided after the --weight_path parameter, the trained model weights will be automatically downloaded for testing.
+
+```bash
+python applications/tools/gpen.py --test_img data/gpen/lite_data/15006.png --seed=100 --weight_path data/gpen/weights/g_ema.pdparams --model_type gpen-ffhq-256
+```
+
+The following are the sample images and the corresponding inpainted images, from left to right, the degraded image, the generated image, and the original clear image:
+
+
+ +An example output is as follows:
+
+
+```
+result saved in : output_dir/gpen_predict.png
+ FID: 92.11730631094356
+ PSNR:19.014782083825743
+```
+
+
+
+## 4. Tipc
+
+### 4.1 Export the inference model
+
+```bash
+python tools/export_model.py -c configs/gpen_256_ffhq.yaml --inputs_size=1,3,256,256 --load data/gpen/weights/weight_pretrain.pdparams
+```
+
+The above command will generate the model structure file `gpenmodel_g_ema.pdmodel` and model weight files `gpenmodel_g_ema.pdiparams` and `gpenmodel_g_ema.pdiparams.info` files required for prediction, which are stored in the `inference_model/` directory. You can also modify the parameters after --load to the model parameter file you want to test.
+
+
+
+### 4.2 Inference with a prediction engine
+
+```bash
+python tools/inference.py --model_type GPEN --seed 100 -c configs/gpen_256_ffhq.yaml -o dataset.test.dataroot="./data/gpen/lite_data/" --output_path test_tipc/output/ --model_path inference_model/gpenmodel_g_ema
+```
+
+At the end of the inference, the repaired image generated by the model will be saved in the test_tipc/output/GPEN directory by default, and the FID value obtained by the test will be output in test_tipc/output/GPEN/metric.txt.
+
+
+The default output is as follows:
+
+```
+Metric fid: 187.0158
+```
+
+Note: Since the operation of degrading high-definition pictures has a certain degree of randomness, the results of each test will be different. In order to ensure that the test results are consistent, here I fixed the random seed, so that the same degradation operation is performed on the image for each test.
+
+
+
+### 4.3 Call the script to complete the training and push test in two steps
+
+To invoke the `lite_train_lite_infer` mode of the foot test base training prediction function, run:
+
+```shell
+# Corrected format of sh file
+sed -i 's/\r//' test_tipc/prepare.sh
+sed -i 's/\r//' test_tipc/test_train_inference_python.sh
+sed -i 's/\r//' test_tipc/common_func.sh
+# prepare data
+bash test_tipc/prepare.sh ./test_tipc/configs/GPEN/train_infer_python.txt 'lite_train_lite_infer'
+# run the test
+bash test_tipc/test_train_inference_python.sh ./test_tipc/configs/GPEN/train_infer_python.txt 'lite_train_lite_infer'
+```
+
+
+
+## 5、References
+
+```
+@misc{2021GAN,
+ title={GAN Prior Embedded Network for Blind Face Restoration in the Wild},
+ author={ Yang, T. and Ren, P. and Xie, X. and Zhang, L. },
+ year={2021},
+ archivePrefix={CVPR},
+ primaryClass={cs.CV}
+}
+```
+
diff --git a/docs/en_US/tutorials/invdn.md b/docs/en_US/tutorials/invdn.md
new file mode 100644
index 0000000000000000000000000000000000000000..08741fa2bcd0dff3f3f619e12f5bc6fe453872fc
--- /dev/null
+++ b/docs/en_US/tutorials/invdn.md
@@ -0,0 +1,119 @@
+English | [Chinese](../../zh_CN/tutorials/invdn.md)
+
+# Invertible Denoising Network: A Light Solution for Real Noise Removal
+
+**Invertible Denoising Network: A Light Solution for Real Noise Removal** (CVPR 2021)
+
+Official code:[https://github.com/Yang-Liu1082/InvDN](https://github.com/Yang-Liu1082/InvDN)
+
+Paper:[https://arxiv.org/abs/2104.10546](https://arxiv.org/abs/2104.10546)
+
+## 1、Introduction
+
+InvDN uses invertible network to divide noise image into low resolution clean image and high frequency latent representation, which contains noise information and content information. Since the invertible network is information lossless, if we can separate the noise information in the high-frequency representation, then we can reconstruct the clean picture with the original resolution together with the clean picture with the low resolution. However, it is difficult to remove the noise in the high-frequency information. In this paper, the high-frequency latent representation with noise is directly replaced by another representation sampled from the prior distribution in the process of reduction, and then the low-resolution clean image is reconstructed back to the original resolution clean image. The network implemented in this paper is lightweight.
+
+
+
+
+## 2 How to use
+
+### 2.1 Quick start
+
+After installing `PaddleGAN`, you can run a command as follows to generate the restorated image `./output_dir/Denoising/image_name.png`.
+
+```sh
+python applications/tools/invdn_denoising.py --images_path ${PATH_OF_IMAGE}
+```
+
+Where `PATH_OF_IMAGE` is the path of the image you need to denoise, or the path of the folder where the images is located.
+
+- Note that in the author's original code, Monte Carlo self-ensemble is used for testing to improve performance, but it slows things down. Users are free to choose whether to use the `--disable_mc` parameter to turn off Monte Carlo self-ensemble for faster speeds. (Monte-carlo self-ensemble is enabled by default for $test$, and disabled by default for $train$ and $valid$.)
+
+### 2.2 Prepare dataset
+
+#### **Train Dataset**
+
+In this paper, we will use SIDD, including training dataset [SIDD-Medium](https://www.eecs.yorku.ca/~kamel/sidd/dataset.php). According to the requirements of the paper, it is necessary to process the dataset into patches of $512 \times 512$. In addition, this paper needs to produce a low-resolution version of the GT image with a size of $128 \times 128$ during training. The low-resolution image is denoted as LQ.
+
+The processed dataset can be find in [Ai Studio](https://aistudio.baidu.com/aistudio/datasetdetail/172084).
+
+The train dataset is placed under: `data/SIDD_Medium_Srgb_Patches_512/train/`.
+
+#### **Test Dataset**
+
+The test dataset is [SIDD_valid](https://www.eecs.yorku.ca/~kamel/sidd/dataset.php). The dataset downloaded from the official website is `./ValidationNoisyBlocksSrgb.mat and ./ValidationGtBlocksSrgb.mat`. You are advised to convert it to $.png$ for convenience.
+
+The converted dataset can be find in [Ai Studio](https://aistudio.baidu.com/aistudio/datasetdetail/172069).
+
+The test dataset is placed under:`data/SIDD_Valid_Srgb_Patches_256/valid/`.
+
+- The file structure under the `PaddleGAN/data` folder is
+```sh
+data
+├─ SIDD_Medium_Srgb_Patches_512
+│ └─ train
+│ ├─ GT
+│ │ 0_0.PNG
+│ │ ...
+│ ├─ LQ
+│ │ 0_0.PNG
+│ │ ...
+│ └─ Noisy
+│ 0_0.PNG
+│ ...
+│
+└─ SIDD_Valid_Srgb_Patches_256
+ └─ valid
+ ├─ GT
+ │ 0_0.PNG
+ │ ...
+ └─ Noisy
+ 0_0.PNG
+ ...
+```
+
+### 2.3 Training
+
+Run the following command to start training:
+```sh
+python -u tools/main.py --config-file configs/invdn_denoising.yaml
+```
+- TIPS:
+In order to ensure that the total $epoch$ number is the same as in the paper configuration, we need to ensure that $total\_batchsize*iter == 1gpus*14bs*600000iters$. Also make sure that $batchsize/learning\_rate == 14/0.0002$ when $batchsize$ is changed.
+For example, when using 4 GPUs, set $batchsize$ as 14, then the actual total $batchsize$ should be 14*4, and the total $iters$ needed to be set as 150,000, and the learning rate should be expanded to 8e-4.
+
+### 2.4 Test
+
+Run the following command to start testing:
+```sh
+python tools/main.py --config-file configs/invdn_denoising.yaml --evaluate-only --load ${PATH_OF_WEIGHT}
+```
+
+## 3 Results
+
+Denoising
+| model | dataset | PSNR/SSIM |
+|---|---|---|
+| InvDN | SIDD | 39.29 / 0.956 |
+
+
+## 4 Download
+
+| model | link |
+|---|---|
+| InvDN| [InvDN_Denoising](https://paddlegan.bj.bcebos.com/models/InvDN_Denoising.pdparams) |
+
+
+
+# References
+
+- [https://arxiv.org/abs/2104.10546](https://arxiv.org/abs/2104.10546)
+
+```
+@article{liu2021invertible,
+ title={Invertible Denoising Network: A Light Solution for Real Noise Removal},
+ author={Liu, Yang and Qin, Zhenyue and Anwar, Saeed and Ji, Pan and Kim, Dongwoo and Caldwell, Sabrina and Gedeon, Tom},
+ journal={arXiv preprint arXiv:2104.10546},
+ year={2021}
+}
+```
diff --git a/docs/en_US/tutorials/lap_style.md b/docs/en_US/tutorials/lap_style.md
new file mode 100644
index 0000000000000000000000000000000000000000..9449d1c0e95b8123ce3f24a041c05cc740fb00a2
--- /dev/null
+++ b/docs/en_US/tutorials/lap_style.md
@@ -0,0 +1,100 @@
+
+
+# LapStyle
+
+
+This repo holds the official codes of paper: "Drafting and Revision: Laplacian Pyramid Network for Fast High-Quality Artistic Style Transfer", which is accepted in CVPR 2021.
+
+## 1 Paper Introduction
+
+
+Artistic style transfer aims at migrating the style from an example image to a content image. Currently, optimization- based methods have achieved great stylization quality, but expensive time cost restricts their practical applications. Meanwhile, feed-forward methods still fail to synthesize complex style, especially when holistic global and local patterns exist. Inspired by the common painting process ofdrawing a draft and revising the details, [this paper](https://arxiv.org/pdf/2104.05376.pdf) introduce a novel feed- forward method Laplacian Pyramid Network (LapStyle). LapStyle first transfers global style pattern in low-resolution via a Drafting Network. It then revises the local details in high-resolution via a Revision Network, which hallucinates a residual image according to the draft and the image textures extracted by Laplacian filtering. Higher resolution details can be easily generated by stacking Revision Networks with multiple Laplacian pyramid levels. The final stylized image is obtained by aggregating outputs ofall pyramid levels. We also introduce a patch discriminator to better learn local pattern adversarially. Experiments demonstrate that our method can synthesize high quality stylized images in real time, where holistic style patterns are properly transferred.
+
+
+
+
+## 2 Quick experience
+Here four style images:
+| [StarryNew](https://user-images.githubusercontent.com/79366697/118655415-1ec8c000-b81c-11eb-8002-90bf8d477860.png) | [Stars](https://user-images.githubusercontent.com/79366697/118655423-20928380-b81c-11eb-92bd-0deeb320ff14.png) | [Ocean](https://user-images.githubusercontent.com/79366697/118655407-1c666600-b81c-11eb-83a6-300ee1952415.png) | [Circuit](https://user-images.githubusercontent.com/79366697/118655399-196b7580-b81c-11eb-8bc5-d5ece80c18ba.jpg)|
+
+```
+python applications/tools/lapstyle.py --content_img_path ${PATH_OF_CONTENT_IMG} --style_image_path ${PATH_OF_STYLE_IMG}
+```
+### Parameters
+
+- `--content_img_path (str)`: path to content image.
+- `--style_image_path (str)`: path to style image.
+- `--output_path (str)`: path to output image dir, default value:`output_dir`.
+- `--weight_path (str)`: path to model weight path, if `weight_path` is `None`, the pre-training model will be downloaded automatically, default value:`None`.
+- `--style (str)`: style of output image, if `weight_path` is `None`, `style` can be chosen in `starrynew`, `circuit`, `ocean` and `stars`, default value:`starrynew`.
+
+## 3 How to use
+
+### 3.1 Prepare Datasets
+
+To train LapStyle, we use the COCO dataset as content image set. You can choose one style image from [starrynew](https://user-images.githubusercontent.com/79366697/118655415-1ec8c000-b81c-11eb-8002-90bf8d477860.png), [ocean](https://user-images.githubusercontent.com/79366697/118655407-1c666600-b81c-11eb-83a6-300ee1952415.png), [stars](https://user-images.githubusercontent.com/79366697/118655423-20928380-b81c-11eb-92bd-0deeb320ff14.png) or [circuit](https://user-images.githubusercontent.com/79366697/118655399-196b7580-b81c-11eb-8bc5-d5ece80c18ba.jpg). Or you can choose any style image you like. Before training or testing, remember modify the data path of style image in the config file.
+
+
+### 3.2 Train
+
+Datasets used in example is COCO, you can also change it to your own dataset in the config file.
+
+Note that train of lapstyle model does not currently support Windows system.
+
+(1) Train the Draft Network of LapStyle under 128*128 resolution:
+```
+python -u tools/main.py --config-file configs/lapstyle_draft.yaml
+```
+
+(2) Then, train the Revision Network of LapStyle under 256*256 resolution:
+```
+python -u tools/main.py --config-file configs/lapstyle_rev_first.yaml --load ${PATH_OF_LAST_STAGE_WEIGHT}
+```
+
+(3) Further, you can train the second Revision Network under 512*512 resolution:
+
+```
+python -u tools/main.py --config-file configs/lapstyle_rev_second.yaml --load ${PATH_OF_LAST_STAGE_WEIGHT}
+```
+
+### 3.4 Test
+
+When testing, you need to change the parameter `validate/save_img` in the configuration file to `true` to save the output image.
+To test the trained model, you can directly test the "lapstyle_rev_second", since it also contains the trained weight of previous stages:
+```
+python tools/main.py --config-file configs/lapstyle_rev_second.yaml --evaluate-only --load ${PATH_OF_WEIGHT}
+```
+
+## 4 Results
+
+| Style | Stylized Results |
+| --- | --- |
+|  | |
+|  | |
+|  | |
+|  | |
+
+## 5 Pre-trained models
+
+We also provide several trained models.
+
+| model | style | path |
+|---|---|---|
+| lapstyle_circuit | circuit | [lapstyle_circuit](https://paddlegan.bj.bcebos.com/models/lapstyle_circuit.pdparams)
+| lapstyle_ocean | ocean | [lapstyle_ocean](https://paddlegan.bj.bcebos.com/models/lapstyle_ocean.pdparams)
+| lapstyle_starrynew | starrynew | [lapstyle_starrynew](https://paddlegan.bj.bcebos.com/models/lapstyle_starrynew.pdparams)
+| lapstyle_stars | stars | [lapstyle_stars](https://paddlegan.bj.bcebos.com/models/lapstyle_stars.pdparams)
+
+
+# References
+
+
+
+```
+@article{lin2021drafting,
+ title={Drafting and Revision: Laplacian Pyramid Network for Fast High-Quality Artistic Style Transfer},
+ author={Lin, Tianwei and Ma, Zhuoqi and Li, Fu and He, Dongliang and Li, Xin and Ding, Errui and Wang, Nannan and Li, Jie and Gao, Xinbo},
+ booktitle={Computer Vision and Pattern Recognition (CVPR)},
+ year={2021}
+}
+```
diff --git a/docs/en_US/tutorials/motion_driving.md b/docs/en_US/tutorials/motion_driving.md
index e5436f8760c8c4731335cf41b56446b332f8e274..b7f4150e58157755925faa86b0f6ea1c3569e39f 100644
--- a/docs/en_US/tutorials/motion_driving.md
+++ b/docs/en_US/tutorials/motion_driving.md
@@ -1,37 +1,200 @@
-# Fist order motion model
+# First Order Motion
-## First order motion model introduction
-
-[First order motion model](https://arxiv.org/abs/2003.00196) is to complete the Image animation task, which consists of generating a video sequence so that an object in a source image is animated according to the motion of a driving video. The first order motion framework addresses this problem without using any annotation or prior information about the specific object to animate. Once trained on a set of videos depicting objects of the same category (e.g. faces, human bodies), this method can be applied to any object of this class. To achieve this, the innovative method decouple appearance and motion information using a self-supervised formulation. In addition, to support complex motions, it use a representation consisting of a set of learned keypoints along with their local affine transformations. A generator network models occlusions arising during target motions and combines the appearance extracted from the source image and the motion derived from the driving video.
+[First order motion model](https://arxiv.org/abs/2003.00196) is to complete the Image animation task, which consists of generating a video sequence so that an object in a source image is animated according to the motion of the driving video. The image below gives examples of source images with objects and driving videos containing a series of motions.
+An example output is as follows:
+
+
+```
+result saved in : output_dir/gpen_predict.png
+ FID: 92.11730631094356
+ PSNR:19.014782083825743
+```
+
+
+
+## 4. Tipc
+
+### 4.1 Export the inference model
+
+```bash
+python tools/export_model.py -c configs/gpen_256_ffhq.yaml --inputs_size=1,3,256,256 --load data/gpen/weights/weight_pretrain.pdparams
+```
+
+The above command will generate the model structure file `gpenmodel_g_ema.pdmodel` and model weight files `gpenmodel_g_ema.pdiparams` and `gpenmodel_g_ema.pdiparams.info` files required for prediction, which are stored in the `inference_model/` directory. You can also modify the parameters after --load to the model parameter file you want to test.
+
+
+
+### 4.2 Inference with a prediction engine
+
+```bash
+python tools/inference.py --model_type GPEN --seed 100 -c configs/gpen_256_ffhq.yaml -o dataset.test.dataroot="./data/gpen/lite_data/" --output_path test_tipc/output/ --model_path inference_model/gpenmodel_g_ema
+```
+
+At the end of the inference, the repaired image generated by the model will be saved in the test_tipc/output/GPEN directory by default, and the FID value obtained by the test will be output in test_tipc/output/GPEN/metric.txt.
+
+
+The default output is as follows:
+
+```
+Metric fid: 187.0158
+```
+
+Note: Since the operation of degrading high-definition pictures has a certain degree of randomness, the results of each test will be different. In order to ensure that the test results are consistent, here I fixed the random seed, so that the same degradation operation is performed on the image for each test.
+
+
+
+### 4.3 Call the script to complete the training and push test in two steps
+
+To invoke the `lite_train_lite_infer` mode of the foot test base training prediction function, run:
+
+```shell
+# Corrected format of sh file
+sed -i 's/\r//' test_tipc/prepare.sh
+sed -i 's/\r//' test_tipc/test_train_inference_python.sh
+sed -i 's/\r//' test_tipc/common_func.sh
+# prepare data
+bash test_tipc/prepare.sh ./test_tipc/configs/GPEN/train_infer_python.txt 'lite_train_lite_infer'
+# run the test
+bash test_tipc/test_train_inference_python.sh ./test_tipc/configs/GPEN/train_infer_python.txt 'lite_train_lite_infer'
+```
+
+
+
+## 5、References
+
+```
+@misc{2021GAN,
+ title={GAN Prior Embedded Network for Blind Face Restoration in the Wild},
+ author={ Yang, T. and Ren, P. and Xie, X. and Zhang, L. },
+ year={2021},
+ archivePrefix={CVPR},
+ primaryClass={cs.CV}
+}
+```
+
diff --git a/docs/en_US/tutorials/invdn.md b/docs/en_US/tutorials/invdn.md
new file mode 100644
index 0000000000000000000000000000000000000000..08741fa2bcd0dff3f3f619e12f5bc6fe453872fc
--- /dev/null
+++ b/docs/en_US/tutorials/invdn.md
@@ -0,0 +1,119 @@
+English | [Chinese](../../zh_CN/tutorials/invdn.md)
+
+# Invertible Denoising Network: A Light Solution for Real Noise Removal
+
+**Invertible Denoising Network: A Light Solution for Real Noise Removal** (CVPR 2021)
+
+Official code:[https://github.com/Yang-Liu1082/InvDN](https://github.com/Yang-Liu1082/InvDN)
+
+Paper:[https://arxiv.org/abs/2104.10546](https://arxiv.org/abs/2104.10546)
+
+## 1、Introduction
+
+InvDN uses invertible network to divide noise image into low resolution clean image and high frequency latent representation, which contains noise information and content information. Since the invertible network is information lossless, if we can separate the noise information in the high-frequency representation, then we can reconstruct the clean picture with the original resolution together with the clean picture with the low resolution. However, it is difficult to remove the noise in the high-frequency information. In this paper, the high-frequency latent representation with noise is directly replaced by another representation sampled from the prior distribution in the process of reduction, and then the low-resolution clean image is reconstructed back to the original resolution clean image. The network implemented in this paper is lightweight.
+
+
+
+
+## 2 How to use
+
+### 2.1 Quick start
+
+After installing `PaddleGAN`, you can run a command as follows to generate the restorated image `./output_dir/Denoising/image_name.png`.
+
+```sh
+python applications/tools/invdn_denoising.py --images_path ${PATH_OF_IMAGE}
+```
+
+Where `PATH_OF_IMAGE` is the path of the image you need to denoise, or the path of the folder where the images is located.
+
+- Note that in the author's original code, Monte Carlo self-ensemble is used for testing to improve performance, but it slows things down. Users are free to choose whether to use the `--disable_mc` parameter to turn off Monte Carlo self-ensemble for faster speeds. (Monte-carlo self-ensemble is enabled by default for $test$, and disabled by default for $train$ and $valid$.)
+
+### 2.2 Prepare dataset
+
+#### **Train Dataset**
+
+In this paper, we will use SIDD, including training dataset [SIDD-Medium](https://www.eecs.yorku.ca/~kamel/sidd/dataset.php). According to the requirements of the paper, it is necessary to process the dataset into patches of $512 \times 512$. In addition, this paper needs to produce a low-resolution version of the GT image with a size of $128 \times 128$ during training. The low-resolution image is denoted as LQ.
+
+The processed dataset can be find in [Ai Studio](https://aistudio.baidu.com/aistudio/datasetdetail/172084).
+
+The train dataset is placed under: `data/SIDD_Medium_Srgb_Patches_512/train/`.
+
+#### **Test Dataset**
+
+The test dataset is [SIDD_valid](https://www.eecs.yorku.ca/~kamel/sidd/dataset.php). The dataset downloaded from the official website is `./ValidationNoisyBlocksSrgb.mat and ./ValidationGtBlocksSrgb.mat`. You are advised to convert it to $.png$ for convenience.
+
+The converted dataset can be find in [Ai Studio](https://aistudio.baidu.com/aistudio/datasetdetail/172069).
+
+The test dataset is placed under:`data/SIDD_Valid_Srgb_Patches_256/valid/`.
+
+- The file structure under the `PaddleGAN/data` folder is
+```sh
+data
+├─ SIDD_Medium_Srgb_Patches_512
+│ └─ train
+│ ├─ GT
+│ │ 0_0.PNG
+│ │ ...
+│ ├─ LQ
+│ │ 0_0.PNG
+│ │ ...
+│ └─ Noisy
+│ 0_0.PNG
+│ ...
+│
+└─ SIDD_Valid_Srgb_Patches_256
+ └─ valid
+ ├─ GT
+ │ 0_0.PNG
+ │ ...
+ └─ Noisy
+ 0_0.PNG
+ ...
+```
+
+### 2.3 Training
+
+Run the following command to start training:
+```sh
+python -u tools/main.py --config-file configs/invdn_denoising.yaml
+```
+- TIPS:
+In order to ensure that the total $epoch$ number is the same as in the paper configuration, we need to ensure that $total\_batchsize*iter == 1gpus*14bs*600000iters$. Also make sure that $batchsize/learning\_rate == 14/0.0002$ when $batchsize$ is changed.
+For example, when using 4 GPUs, set $batchsize$ as 14, then the actual total $batchsize$ should be 14*4, and the total $iters$ needed to be set as 150,000, and the learning rate should be expanded to 8e-4.
+
+### 2.4 Test
+
+Run the following command to start testing:
+```sh
+python tools/main.py --config-file configs/invdn_denoising.yaml --evaluate-only --load ${PATH_OF_WEIGHT}
+```
+
+## 3 Results
+
+Denoising
+| model | dataset | PSNR/SSIM |
+|---|---|---|
+| InvDN | SIDD | 39.29 / 0.956 |
+
+
+## 4 Download
+
+| model | link |
+|---|---|
+| InvDN| [InvDN_Denoising](https://paddlegan.bj.bcebos.com/models/InvDN_Denoising.pdparams) |
+
+
+
+# References
+
+- [https://arxiv.org/abs/2104.10546](https://arxiv.org/abs/2104.10546)
+
+```
+@article{liu2021invertible,
+ title={Invertible Denoising Network: A Light Solution for Real Noise Removal},
+ author={Liu, Yang and Qin, Zhenyue and Anwar, Saeed and Ji, Pan and Kim, Dongwoo and Caldwell, Sabrina and Gedeon, Tom},
+ journal={arXiv preprint arXiv:2104.10546},
+ year={2021}
+}
+```
diff --git a/docs/en_US/tutorials/lap_style.md b/docs/en_US/tutorials/lap_style.md
new file mode 100644
index 0000000000000000000000000000000000000000..9449d1c0e95b8123ce3f24a041c05cc740fb00a2
--- /dev/null
+++ b/docs/en_US/tutorials/lap_style.md
@@ -0,0 +1,100 @@
+
+
+# LapStyle
+
+
+This repo holds the official codes of paper: "Drafting and Revision: Laplacian Pyramid Network for Fast High-Quality Artistic Style Transfer", which is accepted in CVPR 2021.
+
+## 1 Paper Introduction
+
+
+Artistic style transfer aims at migrating the style from an example image to a content image. Currently, optimization- based methods have achieved great stylization quality, but expensive time cost restricts their practical applications. Meanwhile, feed-forward methods still fail to synthesize complex style, especially when holistic global and local patterns exist. Inspired by the common painting process ofdrawing a draft and revising the details, [this paper](https://arxiv.org/pdf/2104.05376.pdf) introduce a novel feed- forward method Laplacian Pyramid Network (LapStyle). LapStyle first transfers global style pattern in low-resolution via a Drafting Network. It then revises the local details in high-resolution via a Revision Network, which hallucinates a residual image according to the draft and the image textures extracted by Laplacian filtering. Higher resolution details can be easily generated by stacking Revision Networks with multiple Laplacian pyramid levels. The final stylized image is obtained by aggregating outputs ofall pyramid levels. We also introduce a patch discriminator to better learn local pattern adversarially. Experiments demonstrate that our method can synthesize high quality stylized images in real time, where holistic style patterns are properly transferred.
+
+
+
+
+## 2 Quick experience
+Here four style images:
+| [StarryNew](https://user-images.githubusercontent.com/79366697/118655415-1ec8c000-b81c-11eb-8002-90bf8d477860.png) | [Stars](https://user-images.githubusercontent.com/79366697/118655423-20928380-b81c-11eb-92bd-0deeb320ff14.png) | [Ocean](https://user-images.githubusercontent.com/79366697/118655407-1c666600-b81c-11eb-83a6-300ee1952415.png) | [Circuit](https://user-images.githubusercontent.com/79366697/118655399-196b7580-b81c-11eb-8bc5-d5ece80c18ba.jpg)|
+
+```
+python applications/tools/lapstyle.py --content_img_path ${PATH_OF_CONTENT_IMG} --style_image_path ${PATH_OF_STYLE_IMG}
+```
+### Parameters
+
+- `--content_img_path (str)`: path to content image.
+- `--style_image_path (str)`: path to style image.
+- `--output_path (str)`: path to output image dir, default value:`output_dir`.
+- `--weight_path (str)`: path to model weight path, if `weight_path` is `None`, the pre-training model will be downloaded automatically, default value:`None`.
+- `--style (str)`: style of output image, if `weight_path` is `None`, `style` can be chosen in `starrynew`, `circuit`, `ocean` and `stars`, default value:`starrynew`.
+
+## 3 How to use
+
+### 3.1 Prepare Datasets
+
+To train LapStyle, we use the COCO dataset as content image set. You can choose one style image from [starrynew](https://user-images.githubusercontent.com/79366697/118655415-1ec8c000-b81c-11eb-8002-90bf8d477860.png), [ocean](https://user-images.githubusercontent.com/79366697/118655407-1c666600-b81c-11eb-83a6-300ee1952415.png), [stars](https://user-images.githubusercontent.com/79366697/118655423-20928380-b81c-11eb-92bd-0deeb320ff14.png) or [circuit](https://user-images.githubusercontent.com/79366697/118655399-196b7580-b81c-11eb-8bc5-d5ece80c18ba.jpg). Or you can choose any style image you like. Before training or testing, remember modify the data path of style image in the config file.
+
+
+### 3.2 Train
+
+Datasets used in example is COCO, you can also change it to your own dataset in the config file.
+
+Note that train of lapstyle model does not currently support Windows system.
+
+(1) Train the Draft Network of LapStyle under 128*128 resolution:
+```
+python -u tools/main.py --config-file configs/lapstyle_draft.yaml
+```
+
+(2) Then, train the Revision Network of LapStyle under 256*256 resolution:
+```
+python -u tools/main.py --config-file configs/lapstyle_rev_first.yaml --load ${PATH_OF_LAST_STAGE_WEIGHT}
+```
+
+(3) Further, you can train the second Revision Network under 512*512 resolution:
+
+```
+python -u tools/main.py --config-file configs/lapstyle_rev_second.yaml --load ${PATH_OF_LAST_STAGE_WEIGHT}
+```
+
+### 3.4 Test
+
+When testing, you need to change the parameter `validate/save_img` in the configuration file to `true` to save the output image.
+To test the trained model, you can directly test the "lapstyle_rev_second", since it also contains the trained weight of previous stages:
+```
+python tools/main.py --config-file configs/lapstyle_rev_second.yaml --evaluate-only --load ${PATH_OF_WEIGHT}
+```
+
+## 4 Results
+
+| Style | Stylized Results |
+| --- | --- |
+|  | |
+|  | |
+|  | |
+|  | |
+
+## 5 Pre-trained models
+
+We also provide several trained models.
+
+| model | style | path |
+|---|---|---|
+| lapstyle_circuit | circuit | [lapstyle_circuit](https://paddlegan.bj.bcebos.com/models/lapstyle_circuit.pdparams)
+| lapstyle_ocean | ocean | [lapstyle_ocean](https://paddlegan.bj.bcebos.com/models/lapstyle_ocean.pdparams)
+| lapstyle_starrynew | starrynew | [lapstyle_starrynew](https://paddlegan.bj.bcebos.com/models/lapstyle_starrynew.pdparams)
+| lapstyle_stars | stars | [lapstyle_stars](https://paddlegan.bj.bcebos.com/models/lapstyle_stars.pdparams)
+
+
+# References
+
+
+
+```
+@article{lin2021drafting,
+ title={Drafting and Revision: Laplacian Pyramid Network for Fast High-Quality Artistic Style Transfer},
+ author={Lin, Tianwei and Ma, Zhuoqi and Li, Fu and He, Dongliang and Li, Xin and Ding, Errui and Wang, Nannan and Li, Jie and Gao, Xinbo},
+ booktitle={Computer Vision and Pattern Recognition (CVPR)},
+ year={2021}
+}
+```
diff --git a/docs/en_US/tutorials/motion_driving.md b/docs/en_US/tutorials/motion_driving.md
index e5436f8760c8c4731335cf41b56446b332f8e274..b7f4150e58157755925faa86b0f6ea1c3569e39f 100644
--- a/docs/en_US/tutorials/motion_driving.md
+++ b/docs/en_US/tutorials/motion_driving.md
@@ -1,37 +1,200 @@
-# Fist order motion model
+# First Order Motion
-## First order motion model introduction
-
-[First order motion model](https://arxiv.org/abs/2003.00196) is to complete the Image animation task, which consists of generating a video sequence so that an object in a source image is animated according to the motion of a driving video. The first order motion framework addresses this problem without using any annotation or prior information about the specific object to animate. Once trained on a set of videos depicting objects of the same category (e.g. faces, human bodies), this method can be applied to any object of this class. To achieve this, the innovative method decouple appearance and motion information using a self-supervised formulation. In addition, to support complex motions, it use a representation consisting of a set of learned keypoints along with their local affine transformations. A generator network models occlusions arising during target motions and combines the appearance extracted from the source image and the motion derived from the driving video.
+[First order motion model](https://arxiv.org/abs/2003.00196) is to complete the Image animation task, which consists of generating a video sequence so that an object in a source image is animated according to the motion of the driving video. The image below gives examples of source images with objects and driving videos containing a series of motions.

+Taking the face in the upper left corner as an example, given a source object and a driving video, a new video can be generated in which the source subject wears an expression that is derived from the driving video. Usually, we need to annotate the keypoints of the source object and train the model for facial expression transfer.
+
+The following gif clearly expounds the principle:
+
+[](https://user-images.githubusercontent.com/48054808/127443878-b9369c1a-909c-4af6-8c84-a62821262910.gif)
+
+The proposed method is not exclusively for facial expression transfer, it also supports other object with training on similar datasets. For example, you can transfer the motion of playing Tai Chi by training on Tai Chi video datasets and achieve facial expression transfer by using dataset voxceleb for training. After that, you could realize real-time image animation with the corresponding pre-training model.
+
+## Features
+
+- #### Multi-Faces Swapping
+
+ - **Unique face detection algorithm that supports automatic multi-faces detection and expression swapping.**
+
+ - We adopt PaddleGAN's face detection model [S3FD](https://github.com/PaddlePaddle/PaddleGAN/tree/develop/ppgan/faceutils/face_detection/detection) to detect all the faces in an image and transfer those expressions for multi-faces swapping.
+
+ Specific technical steps are shown below:
+
+ a. Use the S3FD model to detect all the faces in an image
+
+ b. Use the First Order Motion model to do the facial expression transfer of each face
+
+ c. Crop those "new" generated faces and put them back to the original photo
+
+ At the same time, PaddleGAN also provides a ["faceutils" tool](https://github.com/PaddlePaddle/PaddleGAN/tree/develop/ppgan/faceutils) for face-related work, including face detection, face segmentation, keypoints detection, etc.
+
+- #### Face Enhancement
+
+ - **This effect significantly improves the definition of the driven video.**
+
+- #### Abundant applications for online experience
+
+ - 🐜**Ant Ah Hey**🐜:https://aistudio.baidu.com/aistudio/projectdetail/1603391
+ - 💙**Special For Love Confession on May 20th (pronounced as I love you)**💙:https://aistudio.baidu.com/aistudio/projectdetail/1956943
+ - **Smile of the Deceased(▰˘◡˘▰)**:https://aistudio.baidu.com/aistudio/projectdetail/1660701
+ - 👨**Special For Father's Day**:https://aistudio.baidu.com/aistudio/projectdetail/2068655
## How to use
+### 1. Quick Start: Face Detection and Effect Enhancement
+
+Users can upload a source image with single or multiple faces and driving video, then substitute the paths of source image and driving video for the `source_image` and `driving_video` parameters respectively and run the following command. It will generate a video file named `result.mp4` in the `output` folder, which is the animated video file.
-Users can upload the prepared source image and driving video, then substitute the path of source image and driving video for the `source_image` and `driving_video` parameter in the following running command. It will geneate a video file named `result.mp4` in the `output` folder, which is the animated video file.
+Note: For photos with multiple faces, the longer the distances between faces, the better the result quality you can get, or you could optimize the effect by adjusting ratio.
+
+The original image and driving video here are provided for demonstration purposes, the running command is as follows:
+
+#### Running Command:
```
cd applications/
python -u tools/first-order-demo.py \
--driving_video ../docs/imgs/fom_dv.mp4 \
--source_image ../docs/imgs/fom_source_image.png \
- --relative --adapt_scale
+ --ratio 0.4 \
+ --relative \
+ --adapt_scale \
+ --image_size 512 \
+ --face_enhancement \
+ --multi_person
+```
+
+
+
+#### Parameters:
+
+| Parameters | Instructions |
+| ---------------- | ------------------------------------------------------------ |
+| driving_video | driving video, the motion and expression of the driving video is to be migrated. |
+| source_image | source image, support single face and multi-faces images, the image will be animated according to the motion and expression of the driving video. |
+| relative | indicate whether the relative or absolute coordinates of the key points in the video are used in the program. It is recommended to use relative coordinates, or the characters will be distorted after animation. |
+| adapt_scale | adaptive movement scale based on convex hull of keypoints. |
+| ratio | The pasted face percentage of generated image, this parameter should be adjusted in the case of multi-person image in which the adjacent faces are close. The default value is 0.4 and the range is [0.4, 0.5]. |
+| image_size | The image size of the face. 256 by default, 512 is supported |
+| face_enhancement | enhance the face, closed by default with no parameter added. |
+| multi_person | multiple faces in the image. Default means only one face in the image |
+
+#### 📣Result of Face Enhancement
+
+| Before | After |
+| :----------------------------------------------------------: | :----------------------------------------------------------: |
+| [](https://user-images.githubusercontent.com/17897185/126444836-b68593e3-ae43-4450-b18f-1a549230bf07.gif) | [](https://user-images.githubusercontent.com/17897185/126444194-436cc885-259d-4636-ad4c-c3dcc52fe175.gif) |
+
+### 2. Training
+
+#### **Datasets:**
+
+- fashion See [here](https://vision.cs.ubc.ca/datasets/fashion/)
+- VoxCeleb See [here](https://github.com/AliaksandrSiarohin/video-preprocessing). Here you can process the data sizes according to your requirements. We deal with two resolution sizes: 256 and 512, the results can be seen below: [](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/imgs/fom_512_vs_256.png)
+
+**Parameters:**
+
+- dataset_name.yaml: Configure your own yaml document and parameters
+
+- Training using single GPU:
+```
+export CUDA_VISIBLE_DEVICES=0
+python tools/main.py --config-file configs/dataset_name.yaml
+```
+- Training using multiple GPUs: change the *nn.BatchNorm* in /ppgan/modules/first_order.py to *nn.SyncBatchNorm*
+```
+export CUDA_VISIBLE_DEVICES=0,1,2,3
+python -m paddle.distributed.launch \
+ tools/main.py \
+ --config-file configs/dataset_name.yaml
+
```
-**params:**
-- driving_video: driving video, the motion of the driving video is to be migrated.
-- source_image: source_image, the image will be animated according to the motion of the driving video.
-- relative: indicate whether the relative or absolute coordinates of the key points in the video are used in the program. It is recommended to use relative coordinates. If absolute coordinates are used, the characters will be distorted after animation.
-- adapt_scale: adapt movement scale based on convex hull of keypoints.
+**Example:**
+- Training using single GPU:
+```
+export CUDA_VISIBLE_DEVICES=0
+python tools/main.py --config-file configs/firstorder_fashion.yaml \
+```
+- Training using multiple GPUs:
+```
+export CUDA_VISIBLE_DEVICES=0,1,2,3
+python -m paddle.distributed.launch \
+ tools/main.py \
+ --config-file configs/firstorder_fashion.yaml \
+```
+
+
## Animation results
-
+ [](https://user-images.githubusercontent.com/48054808/119469551-0a377b00-bd7a-11eb-9117-e4871c8fb9c0.gif)
+
+
+
+### 3. Model Compression
+
+**Prediction:**
+
+```
+cd applications/
+python -u tools/first-order-demo.py \
+ --driving_video ../docs/imgs/mayiyahei.MP4 \
+ --source_image ../docs/imgs/father_23.jpg \
+ --config ../configs/firstorder_vox_mobile_256.yaml \
+ --ratio 0.4 \
+ --relative \
+ --adapt_scale \
+ --mobile_net
+```
+
+Currently, we use mobilenet combined with pruning to compress models, see the comparison below:
+
+| | Size(M) | reconstruction loss |
+| ---------- | ------- | ------------------- |
+| Original | 229 | 0.041781392 |
+| Compressed | 10.1 | 0.047878753 |
+
+**Training:** First, set mode in configs/firstorder_vox_mobile_256.yaml as kp_detector, train the compressed kp_detector model, and immobilize the original generator model. Then set mode in configs/firstorder_vox_mobile_256.yaml as generator,train the compressed generator model, and immobilize the original kp_detector model. Finally, set mode as both and modify kp_weight_path and gen_weight_path in the config to the path of trained model to train together。
+
+```
+export CUDA_VISIBLE_DEVICES=0
+python tools/main.py --config-file configs/firstorder_vox_mobile_256.yaml
+```
+
+
+
+### 4. Deployment
+
+#### 4.1 Export
+
+Use the `tools/fom_export.py` script to export the configuration file used when the model has been deployed with the config name of `firstorder_vox_mobile_256.yml`. The export script of the model is as follows.
+
+```
+# Export FOM Model
+
+python tools/export_model.py \
+ --config-file configs/firstorder_vox_mobile_256.yaml \
+ --load /root/.cache/ppgan/vox_mobile.pdparams \
+ --inputs_size "1,3,256,256;1,3,256,256;1,10,2;1,10,2,2" \
+ --export_model output_inference/
+```
+
+The prediction models will be exported to the directory of `output_inference/fom_dy2st/` as `model.pdiparams`, `model.pdiparams.info`, `model.pdmodel`。
+
+- [Pre-training Model](https://paddlegan.bj.bcebos.com/applications/first_order_model/paddle_lite/inference/lite.zip)
+
+#### 4.2 Deployment of PaddleLite
+
+- [Deployment of FOM model with Paddle Lite](https://github.com/PaddlePaddle/PaddleGAN/tree/develop/deploy/lite)
+
+- [FOM-Lite-Demo](https://paddlegan.bj.bcebos.com/applications/first_order_model/paddle_lite/apk/fom_demo.zip)。For more details, please refer to [Paddle-Lite](https://github.com/PaddlePaddle/Paddle-Lite) .
+ Current problems: (a).Paddle Lite performs slightly worse than Paddle Inference,under optimization (b).Run Generator in a single thread, if the number of frames is too large, it will run at the small core rather than the large core.
-## Reference
+## References
```
@InProceedings{Siarohin_2019_NeurIPS,
diff --git a/docs/en_US/tutorials/mpr_net.md b/docs/en_US/tutorials/mpr_net.md
new file mode 100644
index 0000000000000000000000000000000000000000..40d096f8c38e7e809cb63f053bccdf24e5d73f0c
--- /dev/null
+++ b/docs/en_US/tutorials/mpr_net.md
@@ -0,0 +1,124 @@
+# MPR_Net
+
+## 1 Introduction
+
+[MPR_Net](https://arxiv.org/abs/2102.02808) is an image restoration method published in CVPR2021. Image restoration tasks demand a complex balance between spatial details and high-level contextualized information while recovering images. MPR_Net propose a novel synergistic design that can optimally balance these competing goals. The main proposal is a multi-stage architecture, that progressively learns restoration functions for the degraded inputs, thereby breaking down the overall recovery process into more manageable steps. Specifically, the model first learns the contextualized features using encoder-decoder architectures and later combines them with a high-resolution branch that retains local information. At each stage, MPR_Net introduce a novel per-pixel adaptive design that leverages in-situ supervised attention to reweight the local features. A key ingredient in such a multi-stage architecture is the information exchange between different stages. To this end, MPR_Net propose a two-faceted approach where the information is not only exchanged sequentially from early to late stages, but lateral connections between feature processing blocks also exist to avoid any loss of information. The resulting tightly interlinked multi-stage architecture, named as MPRNet, delivers strong performance gains on ten datasets across a range of tasks including image deraining, deblurring, and denoising.
+
+## 2 How to use
+
+### 2.1 Quick start
+
+After installing PaddleGAN, you can run python code as follows to generate the restorated image. Where the `task` is the type of restoration method, you can chose in `Deblurring`、`Denoising` and `Deraining`, and `PATH_OF_IMAGE`is your image path.
+
+```python
+from ppgan.apps import MPRPredictor
+predictor = MPRPredictor(task='Deblurring')
+predictor.run(PATH_OF_IMAGE)
+```
+
+Or run such a command to get the same result:
+
+```sh
+python applications/tools/mprnet.py --input_image ${PATH_OF_IMAGE} --task Deblurring
+```
+Where the `task` is the type of restoration method, you can chose in `Deblurring`、`Denoising` and `Deraining`, and `PATH_OF_IMAGE`is your image path.
+
+### 2.1 Prepare dataset
+
+The Deblurring training datasets is GoPro. The GoPro datasets used for deblurring consists of 3214 blurred images with a size of 1,280×720. These images are divided into 2103 training images and 1111 test images. It can be downloaded from [here](https://drive.google.com/file/d/1H0PIXvJH4c40pk7ou6nAwoxuR4Qh_Sa2/view?usp=sharing).
+After downloading, decompress it to the data directory. After decompression, the structure of `GoProdataset` is as following:
+
+```sh
+GoPro
+├── train
+│ ├── input
+│ └── target
+└── test
+ ├── input
+ └── target
+
+```
+
+The Denoising training datasets is SIDD, an image denoising datasets, containing 30,000 noisy images from 10 different lighting conditions, which can be downloaded from [training datasets](https://www.eecs.yorku.ca/~kamel/sidd/dataset.php) and [Test datasets](https://drive.google.com/drive/folders/1S44fHXaVxAYW3KLNxK41NYCnyX9S79su).
+After downloading, decompress it to the data directory. After decompression, the structure of `SIDDdataset` is as following:
+
+```sh
+SIDD
+├── train
+│ ├── input
+│ └── target
+└── val
+ ├── input
+ └── target
+
+```
+
+Deraining training datasets is Synthetic Rain Datasets, which consists of 13,712 clean rain image pairs collected from multiple datasets (Rain14000, Rain1800, Rain800, Rain12), which can be downloaded from [training datasets](https://drive.google.com/drive/folders/1Hnnlc5kI0v9_BtfMytC2LR5VpLAFZtVe) and [Test datasets](https://drive.google.com/drive/folders/1PDWggNh8ylevFmrjo-JEvlmqsDlWWvZs).
+After downloading, decompress it to the data directory. After decompression, the structure of `Synthetic_Rain_Datasets` is as following:
+
+```sh
+Synthetic_Rain_Datasets
+├── train
+│ ├── input
+│ └── target
+└── test
+ ├── Test100
+ ├── Rain100H
+ ├── Rain100L
+ ├── Test1200
+ └── Test2800
+
+```
+
+### 2.2 Training
+ An example is training to deblur. If you want to train for other tasks, you can replace the config file.
+
+ ```sh
+ python -u tools/main.py --config-file configs/mprnet_deblurring.yaml
+ ```
+
+### 2.3 Test
+
+test model:
+```sh
+python tools/main.py --config-file configs/mprnet_deblurring.yaml --evaluate-only --load ${PATH_OF_WEIGHT}
+```
+
+## 3 Results
+Deblurring
+| model | dataset | PSNR/SSIM |
+|---|---|---|
+| MPRNet | GoPro | 33.4360/0.9410 |
+
+Denoising
+| model | dataset | PSNR/SSIM |
+|---|---|---|
+| MPRNet | SIDD | 43.6100 / 0.9586 |
+
+Deraining
+| model | dataset | PSNR/SSIM |
+|---|---|---|
+| MPRNet | Rain100L | 36.2848 / 0.9651 |
+
+## 4 Download
+
+| model | link |
+|---|---|
+| MPR_Deblurring | [MPR_Deblurring](https://paddlegan.bj.bcebos.com/models/MPR_Deblurring.pdparams) |
+| MPR_Denoising | [MPR_Denoising](https://paddlegan.bj.bcebos.com/models/MPR_Denoising.pdparams) |
+| MPR_Deraining | [MPR_Deraining](https://paddlegan.bj.bcebos.com/models/MPR_Deraining.pdparams) |
+
+
+
+# References
+
+- [Multi-Stage Progressive Image Restoration](https://arxiv.org/abs/2102.02808)
+
+ ```
+ @inproceedings{Kim2020U-GAT-IT:,
+ title={Multi-Stage Progressive Image Restoration},
+ author={Syed Waqas Zamir and Aditya Arora and Salman Khan and Munawar Hayat and Fahad Shahbaz Khan and Ming-Hsuan Yang and Ling Shao},
+ booktitle={CVPR},
+ year={2021}
+ }
+ ```
diff --git a/docs/en_US/tutorials/nafnet.md b/docs/en_US/tutorials/nafnet.md
new file mode 100644
index 0000000000000000000000000000000000000000..9bb9a2dd0c2c10cd84265a2d580854038ba0f80c
--- /dev/null
+++ b/docs/en_US/tutorials/nafnet.md
@@ -0,0 +1,87 @@
+English | [Chinese](../../zh_CN/tutorials/nafnet.md)
+
+## NAFNet:Simple Baselines for Image Restoration
+
+## 1、Introduction
+
+NAFNet proposes an ultra-simple baseline scheme, Baseline, which is not only computationally efficient but also outperforms the previous SOTA scheme; the resulting Baseline is further simplified to give NAFNet: the non-linear activation units are removed and the performance is further improved. The proposed solution achieves new SOTA performance for both SIDD noise reduction and GoPro deblurring tasks with a significant reduction in computational effort. The network design and features are shown in the figure below, using a UNet with skip connections as the overall architecture, modifying the Transformer module in the Restormer block and eliminating the activation function, adopting a simpler and more efficient simplegate design, and applying a simpler channel attention mechanism.
+
+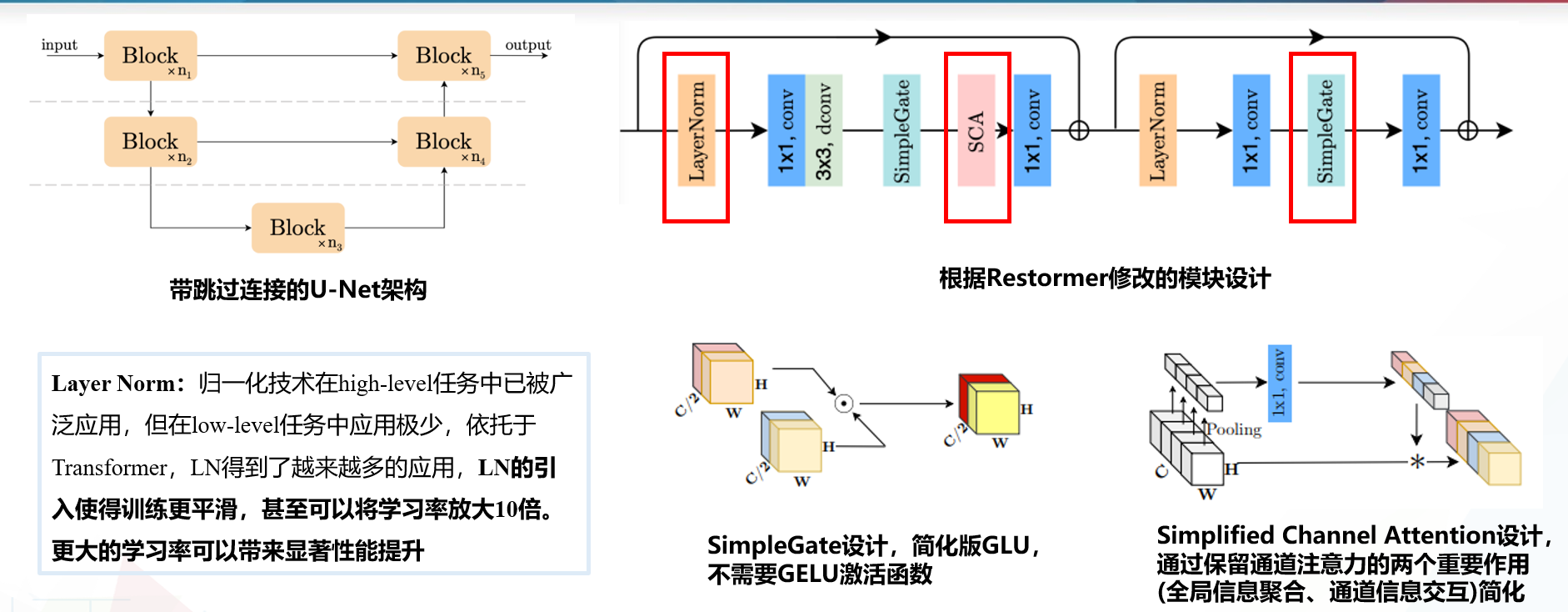
+
+For a more detailed introduction to the model, please refer to the original paper [Simple Baselines for Image Restoration](https://arxiv.org/pdf/2204.04676), PaddleGAN currently provides the weight of the denoising task.
+
+## 2 How to use
+
+### 2.1 Quick start
+
+After installing PaddleGAN, you can run a command as follows to generate the restorated image.
+
+```sh
+python applications/tools/nafnet_denoising.py --images_path ${PATH_OF_IMAGE}
+```
+Where `PATH_OF_IMAGE` is the path of the image you need to denoise, or the path of the folder where the images is located. If you need to use your own model weights, run the following command, where `PATH_OF_MODEL` is the path to the model weights.
+
+```sh
+python applications/tools/nafnet_denoising.py --images_path ${PATH_OF_IMAGE} --weight_path ${PATH_OF_MODEL}
+```
+
+### 2.2 Prepare dataset
+
+The Denoising training datasets is SIDD, an image denoising datasets, containing 30,000 noisy images from 10 different lighting conditions, which can be downloaded from [training datasets](https://www.eecs.yorku.ca/~kamel/sidd/dataset.php) and [Test datasets](https://drive.google.com/drive/folders/1S44fHXaVxAYW3KLNxK41NYCnyX9S79su).
+After downloading, decompress it to the data directory. After decompression, the structure of `SIDDdataset` is as following:
+
+```sh
+SIDD
+├── train
+│ ├── input
+│ └── target
+└── val
+ ├── input
+ └── target
+
+```
+Users can also use the [SIDD data](https://aistudio.baidu.com/aistudio/datasetdetail/149460) on AI studio, but need to rename the folders `input_crops` and `gt_crops` to `input` and ` target`
+
+### 2.3 Training
+An example is training to denoising. If you want to train for other tasks,If you want to train other tasks, you can change the dataset and modify the config file.
+
+```sh
+python -u tools/main.py --config-file configs/nafnet_denoising.yaml
+```
+
+### 2.4 Test
+
+test model:
+```sh
+python tools/main.py --config-file configs/nafnet_denoising.yaml --evaluate-only --load ${PATH_OF_WEIGHT}
+```
+
+## 3 Results
+Denoising
+| model | dataset | PSNR/SSIM |
+|---|---|---|
+| NAFNet | SIDD Val | 43.1468 / 0.9563 |
+
+## 4 Download
+
+| model | link |
+|---|---|
+| NAFNet| [NAFNet_Denoising](https://paddlegan.bj.bcebos.com/models/NAFNet_Denoising.pdparams) |
+
+# References
+
+- [Simple Baselines for Image Restoration](https://arxiv.org/pdf/2204.04676)
+
+```
+@article{chen_simple_nodate,
+ title = {Simple {Baselines} for {Image} {Restoration}},
+ abstract = {Although there have been significant advances in the field of image restoration recently, the system complexity of the state-of-the-art (SOTA) methods is increasing as well, which may hinder the convenient analysis and comparison of methods. In this paper, we propose a simple baseline that exceeds the SOTA methods and is computationally efficient. To further simplify the baseline, we reveal that the nonlinear activation functions, e.g. Sigmoid, ReLU, GELU, Softmax, etc. are not necessary: they could be replaced by multiplication or removed. Thus, we derive a Nonlinear Activation Free Network, namely NAFNet, from the baseline. SOTA results are achieved on various challenging benchmarks, e.g. 33.69 dB PSNR on GoPro (for image deblurring), exceeding the previous SOTA 0.38 dB with only 8.4\% of its computational costs; 40.30 dB PSNR on SIDD (for image denoising), exceeding the previous SOTA 0.28 dB with less than half of its computational costs. The code and the pretrained models will be released at github.com/megvii-research/NAFNet.},
+ language = {en},
+ author = {Chen, Liangyu and Chu, Xiaojie and Zhang, Xiangyu and Sun, Jian},
+ pages = {17}
+}
+```
+
+
+
+
diff --git a/docs/en_US/tutorials/pix2pix_cyclegan.md b/docs/en_US/tutorials/pix2pix_cyclegan.md
index 818ea8d5e7ce148e51d46583a04356450bb7c0da..445df4dcb6ffb119d159023fd1c42f0621f4a3b4 100644
--- a/docs/en_US/tutorials/pix2pix_cyclegan.md
+++ b/docs/en_US/tutorials/pix2pix_cyclegan.md
@@ -18,7 +18,7 @@
```
You can download from wget, download facades from wget for example:
```
- wget https://people.eecs.berkeley.edu/~taesung_park/CycleGAN/datasets/facades.zip --no-check-certificate
+ wget http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/facades.tar.gz --no-check-certificate
```
### 1.2.2 Train/Test
@@ -43,6 +43,7 @@
| 模型 | 数据集 | 下载地址 |
|---|---|---|
| Pix2Pix_cityscapes | cityscapes | [Pix2Pix_cityscapes](https://paddlegan.bj.bcebos.com/models/Pix2Pix_cityscapes.pdparams)
+| Pix2Pix_facedes | facades | [Pix2Pix_facades](https://paddlegan.bj.bcebos.com/models/Pixel2Pixel_facades.pdparams)
@@ -71,7 +72,7 @@
```
You can download from wget, download facades from wget for example:
```
- wget http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/facades.tar.gz --no-check-certificate
+ wget https://people.eecs.berkeley.edu/~taesung_park/CycleGAN/datasets/facades.zip --no-check-certificate
```
### 2.2.2 Train/Test
diff --git a/docs/en_US/tutorials/pixel2style2pixel.md b/docs/en_US/tutorials/pixel2style2pixel.md
index 2f37f9eb4d06b74c08365685da94d6186684a6fb..56ced0d14cf5fb93484a8f2146a6324575a76627 100644
--- a/docs/en_US/tutorials/pixel2style2pixel.md
+++ b/docs/en_US/tutorials/pixel2style2pixel.md
@@ -27,7 +27,7 @@ The user could use the following command to generate and select the local image
```
cd applications/
-python -u tools/styleganv2.py \
+python -u tools/pixel2style2pixel.py \
--input_image \
--output_path \
--weight_path \
diff --git a/docs/en_US/tutorials/prenet.md b/docs/en_US/tutorials/prenet.md
new file mode 100644
index 0000000000000000000000000000000000000000..b68e8ca6c8732cea990d6b8fdb5e4023183a11ab
--- /dev/null
+++ b/docs/en_US/tutorials/prenet.md
@@ -0,0 +1,101 @@
+# PReNet
+
+## 1 Introduction
+"Progressive Image Deraining Networks: A Better and Simpler Baseline" provides a better and simpler baseline deraining network by considering network architecture, input and output, and loss functions.
+
+
+

+
+

+
+

+
+

+
+
+
+

+
+

+
+

+
+

+
+
+
+
+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+
+
+

+
+
+
+

+
+

+
+

+
+

+
+
+
+

+
+

+
+

+
| CUDA | python3.8 | python3.7 | python3.6 | | 10.1 | install python -m pip install https://paddle-wheel.bj.bcebos.com/2.0.0-rc0-gpu-cuda10.1-cudnn7-mkl_gcc8.2%2Fpaddlepaddle_gpu-2.0.0rc0.post101-cp38-cp38-linux_x86_64.whl
-
| install python -m pip install https://paddle-wheel.bj.bcebos.com/2.0.0-rc0-gpu-cuda10.1-cudnn7-mkl_gcc8.2%2Fpaddlepaddle_gpu-2.0.0rc0.post101-cp37-cp37m-linux_x86_64.whl
-
| install python -m pip install https://paddle-wheel.bj.bcebos.com/2.0.0-rc0-gpu-cuda10.1-cudnn7-mkl_gcc8.2%2Fpaddlepaddle_gpu-2.0.0rc0.post101-cp36-cp36m-linux_x86_64.whl
-
| |
| 10.0 | install python -m pip install https://paddle-wheel.bj.bcebos.com/2.0.0-rc0-gpu-cuda10-cudnn7-mkl%2Fpaddlepaddle_gpu-2.0.0rc0.post100-cp38-cp38-linux_x86_64.whl
-
| install python -m pip install https://paddle-wheel.bj.bcebos.com/2.0.0-rc0-gpu-cuda10-cudnn7-mkl%2Fpaddlepaddle_gpu-2.0.0rc0.post100-cp37-cp37m-linux_x86_64.whl
-
| install python -m pip install https://paddle-wheel.bj.bcebos.com/2.0.0-rc0-gpu-cuda10-cudnn7-mkl%2Fpaddlepaddle_gpu-2.0.0rc0.post100-cp36-cp36m-linux_x86_64.whl
-
| |
| 9.0 | install python -m pip install https://paddle-wheel.bj.bcebos.com/2.0.0-rc0-gpu-cuda9-cudnn7-mkl%2Fpaddlepaddle_gpu-2.0.0rc0.post90-cp38-cp38-linux_x86_64.whl
-
| install python -m pip install https://paddle-wheel.bj.bcebos.com/2.0.0-rc0-gpu-cuda9-cudnn7-mkl%2Fpaddlepaddle_gpu-2.0.0rc0.post90-cp37-cp37m-linux_x86_64.whl
-
| install python -m pip install https://paddle-wheel.bj.bcebos.com/2.0.0-rc0-gpu-cuda9-cudnn7-mkl%2Fpaddlepaddle_gpu-2.0.0rc0.post90-cp36-cp36m-linux_x86_64.whl
-
|
+更多安装方式例如conda或源码编译安装方法,请参考[PaddlePaddle安装文档](https://www.paddlepaddle.org.cn/documentation/docs/zh/install/index_cn.html)。
-支持更多系统的安装教程请前往[paddlepaddle官网](https://www.paddlepaddle.org.cn/install/quick)
+请确保您的PaddlePaddle安装成功并且版本不低于需求版本。使用以下命令进行验证。
-### 2. 安装PaddleGAN
+```
+# 在您的Python解释器中确认PaddlePaddle安装成功
+>>> import paddle
+>>> paddle.utils.run_check()
-##### 2.1 通过Pip安裝
+# 确认PaddlePaddle版本
+python -c "import paddle; print(paddle.__version__)"
+```
+
+## 安装PaddleGAN
+
+### 通过PIP安裝(只支持Python3)
+
+* 安装:
```
-# only support Python3
python3 -m pip install --upgrade ppgan
```
-
-下载示例和配置文件:
+* 下载示例和配置文件:
```
git clone https://github.com/PaddlePaddle/PaddleGAN
cd PaddleGAN
```
-
-##### 2.2通过源码安装
+### 通过源码安装
```
git clone https://github.com/PaddlePaddle/PaddleGAN
cd PaddleGAN
pip install -v -e . # or "python setup.py develop"
-```
-
-按照上述方法安装成功后,本地的修改也会自动同步到ppgan中
+# 安装其他依赖
+pip install -r requirements.txt
+```
+## 其他第三方工具安装
-### 4. 其他可能用到的工具安装
-
-#### 4.1 ffmpeg
-
-如果需要使用ppgan处理视频相关的任务,则需要安装ffmpeg。这里推荐您使用[conda](https://docs.conda.io/en/latest/miniconda.html)安装:
+* 涉及视频的任务都需安装**ffmpeg**,这里推荐使用[conda](https://docs.conda.io/en/latest/miniconda.html)安装:
```
conda install x264=='1!152.20180717' ffmpeg=4.0.2 -c conda-forge
```
-#### 4.2 Visual DL
-
-如果需要使用[飞桨VisualDL](https://github.com/PaddlePaddle/VisualDL)对训练过程进行可视化监控,请安装`VisualDL`(使用方法请参考[这里](./get_started.md)):
-
+* 如需使用可视化工具监控训练过程,请安装[飞桨VisualDL](https://github.com/PaddlePaddle/VisualDL):
```
python -m pip install visualdl -i https://mirror.baidu.com/pypi/simple
```
+*注意:VisualDL目前只维护Python3以上的安装版本
diff --git a/docs/zh_CN/tutorials/animegan.md b/docs/zh_CN/tutorials/animegan.md
index bc3d5aa950bd2a0f229b29d2fb319fd9c8f2d6c5..3c86beca5873d0dbf495d74ff0e0bbd188c8c12f 100644
--- a/docs/zh_CN/tutorials/animegan.md
+++ b/docs/zh_CN/tutorials/animegan.md
@@ -70,7 +70,7 @@ animedataset
1. 预热模型完成后,训练风格迁移模型:
**注意:** 必须先修改在`configs/animeganv2.yaml`中的`pretrain_ckpt`参数,确保指向正确的 **预热模型权重路径**
- 设置`batch size=4`,`learning rate=0.00002`,在一个 GTX2060S GPU上训练30个epoch即可获得较好的效果,其他超参数请参考`configs/animeganv2.yaml`。
+ 设置`batch size=4`,`learning rate=0.0002`,在一个 GTX2060S GPU上训练30个epoch即可获得较好的效果,其他超参数请参考`configs/animeganv2.yaml`。
```sh
python tools/main.py --config-file configs/animeganv2.yaml
diff --git a/docs/zh_CN/tutorials/aotgan.md b/docs/zh_CN/tutorials/aotgan.md
new file mode 100644
index 0000000000000000000000000000000000000000..716d613b8b469324ace96379ef6caeef1ec6c4aa
--- /dev/null
+++ b/docs/zh_CN/tutorials/aotgan.md
@@ -0,0 +1,101 @@
+# AOT GAN
+
+## 1. 简介
+
+本应用的 AOT GAN 模型出自论文《Aggregated Contextual Transformations for High-Resolution Image Inpainting》,其通过聚合不同膨胀率的空洞卷积学习到的图片特征,刷出了inpainting任务的新SOTA。模型推理效果如下:
+
+
+
+**论文:** [Aggregated Contextual Transformations for High-Resolution Image Inpainting](https://paperswithcode.com/paper/aggregated-contextual-transformations-for)
+
+**参考repo:** [https://github.com/megvii-research/NAFNet](https://github.com/megvii-research/NAFNet)
+
+## 2.快速体验
+
+预训练模型权重文件 g.pdparams 可以从如下地址下载: (https://paddlegan.bj.bcebos.com/models/AotGan_g.pdparams)
+
+输入一张 512x512 尺寸的图片和擦除 mask 给模型,输出一张补全(inpainting)的图片。预测代码如下:
+
+```
+python applications/tools/aotgan.py \
+ --input_image_path data/aotgan/armani1.jpg \
+ --input_mask_path data/aotgan/armani1.png \
+ --weight_path test/aotgan/g.pdparams \
+ --output_path output_dir/armani_pred.jpg \
+ --config-file configs/aotgan.yaml
+```
+
+**参数说明:**
+* input_image_path:输入图片路径
+* input_mask_path:输入擦除 mask 路径
+* weight_path:训练完成的模型权重存储路径,为 statedict 格式(.pdparams)的 Paddle 模型行权重文件
+* output_path:预测生成图片的存储路径
+* config-file:存储参数设定的yaml文件存储路径,与训练过程使用同一个yaml文件,预测参数由 predict 下字段设定
+
+AI Studio 快速体验项目:(https://aistudio.baidu.com/aistudio/datasetdetail/165081)
+
+## 3.训练
+
+**数据准备:**
+
+* 训练用的图片解压到项目路径下的 data/aotgan/train_img 文件夹内,可包含多层目录,dataloader会递归读取每层目录下的图片。训练用的mask图片解压到项目路径下的 data/aotgan/train_mask 文件夹内。
+* 验证用的图片和mask图片相应的放到项目路径下的 data/aotgan/val_img 文件夹和 data/aotgan/val_mask 文件夹内。
+
+数据集目录结构如下:
+
+```
+└─data
+ └─aotgan
+ ├─train_img
+ ├─train_mask
+ ├─val_img
+ └─val_mask
+```
+
+* 训练预训练模型的权重使用了 Place365Standard 数据集的训练集图片,以及 NVIDIA Irregular Mask Dataset 数据集的测试集掩码图片。Place365Standard 的训练集为 160万张长或宽最小为 512 像素的图片。NVIDIA Irregular Mask Dataset 的测试集为 12000 张尺寸为 512 x 512 的不规则掩码图片。数据集下载链接:[Place365Standard](http://places2.csail.mit.edu/download.html)、[NVIDIA Irregular Mask Dataset](https://nv-adlr.github.io/publication/partialconv-inpainting)
+
+### 3.1 gpu 单卡训练
+
+`python -u tools/main.py --config-file configs/aotgan.yaml`
+
+* config-file:训练使用的超参设置 yamal 文件的存储路径
+
+### 3.2 gpu 多卡训练
+
+```
+!python -m paddle.distributed.launch \
+ tools/main.py \
+ --config-file configs/photopen.yaml \
+ -o dataset.train.batch_size=6
+```
+
+* config-file:训练使用的超参设置 yamal 文件的存储路径
+* -o dataset.train.batch_size=6:-o 设置参数覆盖 yaml 文件中的值,这里调整了 batch_size 参数
+
+### 3.3 继续训练
+
+```
+python -u tools/main.py \
+ --config-file configs/aotgan.yaml \
+ --resume output_dir/[path_to_checkpoint]/iter_[iternumber]_checkpoint.pdparams
+```
+
+* config-file:训练使用的超参设置 yamal 文件的存储路径
+* resume:指定读取的 checkpoint 路径
+
+### 3.4 实验结果展示
+
+在Places365模型的验证集上的指标如下
+
+| mask | PSNR | SSIM | download |
+| ---- | ---- | ---- | ---- |
+| 20-30% | 26.04001 | 0.89011 | [download](https://paddlegan.bj.bcebos.com/models/AotGan_g.pdparams) |
+
+## 4. 参考链接与文献
+@inproceedings{yan2021agg,
+ author = {Zeng, Yanhong and Fu, Jianlong and Chao, Hongyang and Guo, Baining},
+ title = {Aggregated Contextual Transformations for High-Resolution Image Inpainting},
+ booktitle = {Arxiv},
+ pages={-},
+ year = {2020}
+}
diff --git a/docs/zh_CN/tutorials/face_enhancement.md b/docs/zh_CN/tutorials/face_enhancement.md
new file mode 100644
index 0000000000000000000000000000000000000000..fb14b6130d1b3a7734aca5e5d87e7a2bc5d1efb9
--- /dev/null
+++ b/docs/zh_CN/tutorials/face_enhancement.md
@@ -0,0 +1,43 @@
+# 人脸增强
+
+## 1. 人脸增强简介
+
+从严重退化的人脸图像中恢复出人脸是一个非常具有挑战性的问题。由于问题的严重性和复杂的未知退化,直接训练深度神经网络通常无法得到可接受的结果。现有的基于生成对抗网络 (GAN) 的方法可以产生更好的结果,但往往会产生过度平滑的恢复。这里我们提供[GPEN](https://arxiv.org/abs/2105.06070)模型来进行人脸增强。GPEN模型首先学习用于生成高质量人脸图像的GAN并将其嵌入到U形DNN作为先验解码器,然后使用一组合成的低质量人脸图像对GAN先验嵌入DNN进行微调。 GAN 模块的设计是为了确保输入到 GAN 的隐码和噪声可以分别从 DNN 的深层和浅层特征中生成,控制重建图像的全局人脸结构、局部人脸细节和背景。所提出的 GAN 先验嵌入网络 (GPEN) 易于实现,并且可以生成视觉上逼真的结果。实验表明,GPEN 在数量和质量上都比最先进的 BFR 方法取得了显着优越的结果,特别是对于野外严重退化的人脸图像的恢复。
+
+## 使用方法
+
+### 人脸增强
+
+用户使用如下代码进行人脸增强,选择本地图像作为输入:
+
+```python
+import paddle
+from ppgan.faceutils.face_enhancement import FaceEnhancement
+
+faceenhancer = FaceEnhancement()
+img = faceenhancer.enhance_from_image(img)
+```
+
+注意:请将图片转为float类型输入,目前不支持int8类型
+
+### 训练
+
+[详见](../../zh_CN/tutorials/gpen.md)
+
+## 人脸增强结果展示
+
+
+
+## 参考文献
+
+```
+@inproceedings{inproceedings,
+author = {Yang, Tao and Ren, Peiran and Xie, Xuansong and Zhang, Lei},
+year = {2021},
+month = {06},
+pages = {672-681},
+title = {GAN Prior Embedded Network for Blind Face Restoration in the Wild},
+doi = {10.1109/CVPR46437.2021.00073}
+}
+
+```
diff --git a/docs/zh_CN/tutorials/face_parse.md b/docs/zh_CN/tutorials/face_parse.md
index 24c1a622f644f065cdaf12cd1ab6e6544064d44b..931a76d6548a929b381cf74daf93917137fb83ce 100644
--- a/docs/zh_CN/tutorials/face_parse.md
+++ b/docs/zh_CN/tutorials/face_parse.md
@@ -10,7 +10,7 @@
运行如下命令,可以完成人脸解析任务,程序运行成功后,会在`output`文件夹生成解析后的图片文件。具体命令如下所示:
```
cd applications
-python face_parse.py --input_image ../docs/imgs/face.png
+python tools/face_parse.py --input_image ../docs/imgs/face.png
```
**参数:**
diff --git a/docs/zh_CN/tutorials/gfpgan.md b/docs/zh_CN/tutorials/gfpgan.md
new file mode 100644
index 0000000000000000000000000000000000000000..1da5317fe303368307e75aedc894b28d9fc174d9
--- /dev/null
+++ b/docs/zh_CN/tutorials/gfpgan.md
@@ -0,0 +1,198 @@
+## GFPGAN 盲脸复原模型
+
+
+## 1、介绍
+GFP-GAN利用丰富和多样化的先验封装在预先训练的面部GAN用于盲人面部恢复。
+### GFPGAN的整体结构:
+
+
+
+GFP-GAN由降解去除物组成
+模块(U-Net)和预先训练的面部GAN(如StyleGAN2)作为先验。他们之间有隐藏的密码
+映射和几个通道分割空间特征变换(CS-SFT)层。
+
+通过处理特征,它在保持高保真度的同时实现了真实的结果。
+
+要了解更详细的模型介绍,并参考回购,您可以查看以下AI Studio项目
+[基于PaddleGAN复现GFPGAN](https://aistudio.baidu.com/aistudio/projectdetail/4421649)
+
+在这个实验中,我们训练
+我们的模型和Adam优化器共进行了210k次迭代。
+
+GFPGAN的回收实验结果如下:
+
+
+Model | LPIPS | FID | PSNR
+--- |:---:|:---:|:---:|
+GFPGAN | 0.3817 | 36.8068 | 65.0461
+
+## 2、准备工作
+
+### 2.1 数据集准备
+
+GFPGAN模型训练集是经典的FFHQ人脸数据集,
+总共有7万张高分辨率1024 x 1024的人脸图片,
+测试集为CELEBA-HQ数据集,共有2000张高分辨率人脸图片。生成方式与训练时相同。
+For details, please refer to **Dataset URL:** [FFHQ](https://github.com/NVlabs/ffhq-dataset), [CELEBA-HQ](https://github.com/tkarras/progressive_growing_of_gans).
+The specific download links are given below:
+
+**原始数据集地址:**
+
+**FFHQ :** https://drive.google.com/drive/folders/1tZUcXDBeOibC6jcMCtgRRz67pzrAHeHL?usp=drive_open
+
+**CELEBA-HQ:** https://drive.google.com/drive/folders/0B4qLcYyJmiz0TXY1NG02bzZVRGs?resourcekey=0-arAVTUfW9KRhN-irJchVKQ&usp=sharing
+
+数据集结构如下
+
+```
+|-- data/GFPGAN
+ |-- train
+ |-- 00000.png
+ |-- 00001.png
+ |-- ......
+ |-- 00999.png
+ |-- ......
+ |-- 69999.png
+ |-- lq
+ |-- 2000张jpg图片
+ |-- gt
+ |-- 2000张jpg图片
+```
+
+请在configs/gfpgan_ffhq1024. data中修改数据集train和test的dataroot参数。Yaml配置文件到您的训练集和测试集路径。
+
+### 2.2 模型准备
+**模型参数文件和训练日志下载地址:**
+
+https://paddlegan.bj.bcebos.com/models/GFPGAN.pdparams
+
+从链接下载模型参数和测试图像,并将它们放在项目根目录中的data/文件夹中。具体文件结构如下:
+
+params是一个dict(python中的一种类型),可以通过paddlepaddle加载。它包含key (net_g,net_g_ema),您可以使用其中任何一个来进行推断
+
+## 3、开始使用
+模型训练
+
+在控制台中输入以下代码开始训练:
+
+ ```bash
+ python tools/main.py -c configs/gfpgan_ffhq1024.yaml
+ ```
+
+该模型支持单卡训练和多卡训练。
+也可以使用如下命令进行多卡训练
+
+```bash
+!CUDA_VISIBLE_DEVICES=0,1,2,3
+!python -m paddle.distributed.launch tools/main.py \
+ --config-file configs/gpfgan_ffhq1024.yaml
+```
+
+模型训练需要使用paddle2.3及以上版本,等待paddle实现elementwise_pow的二阶算子相关函数。paddle2.2.2版本可以正常运行,但由于某些损失函数会计算出错误的梯度,无法成功训练模型。如果在培训过程中报错,则暂时不支持培训。您可以跳过训练部分,直接使用提供的模型参数进行测试。模型评估和测试可以使用paddle2.2.2及以上版本。
+
+### 3.2 模型评估
+
+当评估模型时,在控制台中输入以下代码,使用上面提到的下载的模型参数:
+
+ ```shell
+python tools/main.py -c configs/gfpgan_ffhq1024.yaml --load GFPGAN.pdparams --evaluate-only
+ ```
+
+当评估模型时,在控制台中输入以下代码,使用下载的模型。如果您想在您自己提供的模型上进行测试,请修改之后的路径 --load .
+
+
+
+### 3.3 模型预测
+
+#### 3.3.1 导出模型
+
+在训练之后,您需要使用' ' tools/export_model.py ' '从训练的模型中提取生成器的权重(仅包括生成器)
+输入以下命令提取生成器的模型:
+
+```bash
+python -u tools/export_model.py --config-file configs/gfpgan_ffhq1024.yaml \
+ --load GFPGAN.pdparams \
+ --inputs_size 1,3,512,512
+```
+
+
+#### 3.3.2 加载一张图片
+
+你可以使用我们在ppgan/faceutils/face_enhancement/gfpgan_enhance.py中的工具来快速推断一张图片
+
+```python
+%env PYTHONPATH=.:$PYTHONPATH
+%env CUDA_VISIBLE_DEVICES=0
+import paddle
+import cv2
+import numpy as np
+import sys
+from ppgan.faceutils.face_enhancement.gfpgan_enhance import gfp_FaceEnhancement
+# 图片路径可以用自己的
+img_path='test/2.png'
+img = cv2.imread(img_path, cv2.IMREAD_COLOR)
+# 这是原来的模糊图片
+cv2.imwrite('test/outlq.png',img)
+img=np.array(img).astype('float32')
+faceenhancer = gfp_FaceEnhancement()
+img = faceenhancer.enhance_from_image(img)
+# 这是生成的清晰图片
+cv2.imwrite('test/out_gfpgan.png',img)
+```
+
+
+
+
+
+
+
+## 4. Tipc
+
+### 4.1 导出推理模型
+
+```bash
+python -u tools/export_model.py --config-file configs/gfpgan_ffhq1024.yaml \
+ --load GFPGAN.pdparams \
+ --inputs_size 1,3,512,512
+```
+
+### 4.2 使用paddleInference推理
+
+```bash
+%cd /home/aistudio/work/PaddleGAN
+# %env PYTHONPATH=.:$PYTHONPATH
+# %env CUDA_VISIBLE_DEVICES=0
+!python -u tools/inference.py --config-file configs/gfpgan_ffhq1024.yaml \
+ --model_path GFPGAN.pdparams \
+ --model_type gfpgan \
+ --device gpu \
+ -o validate=None
+```
+
+
+### 4.3 一键TIPC
+
+调用足部测试基础训练预测函数的' lite_train_lite_infer '模式,执行:
+
+```bash
+%cd /home/aistudio/work/PaddleGAN
+!bash test_tipc/prepare.sh \
+ test_tipc/configs/GFPGAN/train_infer_python.txt \
+ lite_train_lite_infer
+!bash test_tipc/test_train_inference_python.sh \
+ test_tipc/configs/GFPGAN/train_infer_python.txt \
+ lite_train_lite_infer
+```
+
+
+
+## 5、References
+
+```
+@InProceedings{wang2021gfpgan,
+ author = {Xintao Wang and Yu Li and Honglun Zhang and Ying Shan},
+ title = {Towards Real-World Blind Face Restoration with Generative Facial Prior},
+ booktitle={The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
+ year = {2021}
+}
+```
diff --git a/docs/zh_CN/tutorials/gpen.md b/docs/zh_CN/tutorials/gpen.md
new file mode 100644
index 0000000000000000000000000000000000000000..e303e6c6db7280a8779a711193a9f820dea2b70e
--- /dev/null
+++ b/docs/zh_CN/tutorials/gpen.md
@@ -0,0 +1,205 @@
+[English](../../en_US/tutorials/gpen.md) | 中文
+
+## GPEN 盲人脸修复模型
+
+
+## 1、简介
+
+GPEN模型是一个盲人脸修复模型。作者将前人提出的 StyleGAN V2 的解码器嵌入模型,作为GPEN的解码器;用DNN重新构建了一种简单的编码器,为解码器提供输入。这样模型在保留了 StyleGAN V2 解码器优秀的性能的基础上,将模型的功能由图像风格转换变为了盲人脸修复。模型的总体结构如下图所示:
+
+
+
+对模型更详细的介绍,和参考repo可查看以下AI Studio项目[链接]([GPEN盲人脸修复模型复现 - 飞桨AI Studio (baidu.com)](https://aistudio.baidu.com/aistudio/projectdetail/3936241?contributionType=1))的最新版本。
+
+
+
+
+## 2、准备工作
+
+### 2.1 数据集准备
+
+GPEN模型训练集是经典的FFHQ人脸数据集,共70000张1024 x 1024高分辨率的清晰人脸图片,测试集是CELEBA-HQ数据集,共2000张高分辨率人脸图片。详细信息可以参考**数据集网址:** [FFHQ](https://github.com/NVlabs/ffhq-dataset) ,[CELEBA-HQ](https://github.com/tkarras/progressive_growing_of_gans) 。以下给出了具体的下载链接:
+
+**原数据集下载地址:**
+
+**FFHQ :** https://drive.google.com/drive/folders/1tZUcXDBeOibC6jcMCtgRRz67pzrAHeHL?usp=drive_open
+
+**CELEBA-HQ:** https://drive.google.com/drive/folders/0B4qLcYyJmiz0TXY1NG02bzZVRGs?resourcekey=0-arAVTUfW9KRhN-irJchVKQ&usp=sharing
+
+
+
+由于FFHQ原数据集过大,也可以从以下链接下载256分辨率的FFHQ数据集:
+
+https://paddlegan.bj.bcebos.com/datasets/images256x256.tar
+
+
+
+**下载后,文件参考组织形式如下**
+
+```
+|-- data/GPEN
+ |-- ffhq/images256x256/
+ |-- 00000
+ |-- 00000.png
+ |-- 00001.png
+ |-- ......
+ |-- 00999.png
+ |-- 01000
+ |-- ......
+ |-- ......
+ |-- 69000
+ |-- ......
+ |-- 69999.png
+ |-- test
+ |-- 2000张png图片
+```
+
+请修改configs/gpen_256_ffhq.yaml配置文件中dataset的train和test的dataroot参数为你的训练集和测试集路径。
+
+
+
+### 2.2 模型准备
+
+**模型参数文件及训练日志下载地址:**
+
+链接:https://paddlegan.bj.bcebos.com/models/gpen.zip
+
+
+从链接中下载模型参数和测试图片,并放到项目根目录下的data/文件夹下,具体文件结构如下所示:
+
+**文件结构**
+
+
+```
+data/gpen/weights
+ |-- model_ir_se50.pdparams #计算id_loss需要加载的facenet的模型参数文件
+ |-- weight_pretrain.pdparams #256分辨率的包含生成器和判别器的模型参数文件,其中只有生成器的参数是训练好的参数,参 #数文件的格式与3.1训练过程中保存的参数文件格式相同。3.2、3.3.1、4.1也需要用到该参数文件
+data/gpen/lite_data
+```
+
+
+
+## 3、开始使用
+
+### 3.1 模型训练
+
+在控制台输入以下代码,开始训练:
+
+ ```shell
+ python tools/main.py -c configs/gpen_256_ffhq.yaml
+ ```
+
+模型只支持单卡训练。
+
+模型训练需使用paddle2.3及以上版本,且需等paddle实现elementwise_pow 的二阶算子相关功能,使用paddle2.2.2版本能正常运行,但因部分损失函数会求出错误梯度,导致模型无法训练成功。如训练时报错则暂不支持进行训练,可跳过训练部分,直接使用提供的模型参数进行测试。模型评估和测试使用paddle2.2.2及以上版本即可。
+
+
+
+### 3.2 模型评估
+
+对模型进行评估时,在控制台输入以下代码,下面代码中使用上面提到的下载的模型参数:
+
+ ```shell
+python tools/main.py -c configs/gpen_256_ffhq.yaml -o dataset.test.amount=2000 --load data/gpen/weights/weight_pretrain.pdparams --evaluate-only
+ ```
+
+如果要在自己提供的模型上进行测试,请修改 --load 后面的路径。
+
+
+
+### 3.3 模型预测
+
+#### 3.3.1 导出生成器权重
+
+训练结束后,需要使用 ``tools/extract_weight.py`` 来从训练模型(包含了生成器和判别器)中提取生成器的权重来给`applications/tools/gpen.py`进行推理,以实现GPEN模型的各种应用。输入以下命令来提取生成器的权重:
+
+```bash
+python tools/extract_weight.py data/gpen/weights/weight_pretrain.pdparams --net-name g_ema --output data/gpen/weights/g_ema.pdparams
+```
+
+
+
+#### 3.3.2 对单张图像进行处理
+
+提取完生成器的权重后,输入以下命令可对--test_img路径下图片进行测试。修改--seed参数,可生成不同的退化图像,展示出更丰富的效果。可修改--test_img后的路径为你想测试的任意图片。如--weight_path参数后不提供权重,则会自动下载训练好的模型权重进行测试。
+
+```bash
+python applications/tools/gpen.py --test_img data/gpen/lite_data/15006.png --seed=100 --weight_path data/gpen/weights/g_ema.pdparams --model_type gpen-ffhq-256
+```
+
+以下是样例图片和对应的修复图像,从左到右依次是退化图像、生成的图像和原始清晰图像:
+
+
+
+
+
+
+输出示例如下:
+
+```
+result saved in : output_dir/gpen_predict.png
+ FID: 92.11730631094356
+ PSNR:19.014782083825743
+```
+
+
+
+## 4. Tipc
+
+### 4.1 导出inference模型
+
+```bash
+python tools/export_model.py -c configs/gpen_256_ffhq.yaml --inputs_size=1,3,256,256 --load data/gpen/weights/weight_pretrain.pdparams
+```
+
+上述命令将生成预测所需的模型结构文件`gpenmodel_g_ema.pdmodel`和模型权重文件`gpenmodel_g_ema.pdiparams`以及`gpenmodel_g_ema.pdiparams.info`文件,均存放在`inference_model/`目录下。也可以修改--load 后的参数为你想测试的模型参数文件。
+
+
+
+### 4.2 使用预测引擎推理
+
+```bash
+python tools/inference.py --model_type GPEN --seed 100 -c configs/gpen_256_ffhq.yaml -o dataset.test.dataroot="./data/gpen/lite_data/" --output_path test_tipc/output/ --model_path inference_model/gpenmodel_g_ema
+```
+
+推理结束会默认保存下模型生成的修复图像在test_tipc/output/GPEN目录下,并载test_tipc/output/GPEN/metric.txt中输出测试得到的FID值。
+
+
+默认输出如下:
+
+```
+Metric fid: 187.0158
+```
+
+注:由于对高清图片进行退化的操作具有一定的随机性,所以每次测试的结果都会有所不同。为了保证测试结果一致,在这里我固定了随机种子,使每次测试时对图片都进行相同的退化操作。
+
+
+
+### 4.3 调用脚本两步完成训推一体测试
+
+测试基本训练预测功能的`lite_train_lite_infer`模式,运行:
+
+```shell
+# 修正脚本文件格式
+sed -i 's/\r//' test_tipc/prepare.sh
+sed -i 's/\r//' test_tipc/test_train_inference_python.sh
+sed -i 's/\r//' test_tipc/common_func.sh
+# 准备数据
+bash test_tipc/prepare.sh ./test_tipc/configs/GPEN/train_infer_python.txt 'lite_train_lite_infer'
+# 运行测试
+bash test_tipc/test_train_inference_python.sh ./test_tipc/configs/GPEN/train_infer_python.txt 'lite_train_lite_infer'
+```
+
+
+
+## 5、参考文献
+
+```
+@misc{2021GAN,
+ title={GAN Prior Embedded Network for Blind Face Restoration in the Wild},
+ author={ Yang, T. and Ren, P. and Xie, X. and Zhang, L. },
+ year={2021},
+ archivePrefix={CVPR},
+ primaryClass={cs.CV}
+}
+```
diff --git a/docs/zh_CN/tutorials/invdn.md b/docs/zh_CN/tutorials/invdn.md
new file mode 100644
index 0000000000000000000000000000000000000000..f2cb70f6c96d00207c8cb51cad76e845733d9b8f
--- /dev/null
+++ b/docs/zh_CN/tutorials/invdn.md
@@ -0,0 +1,117 @@
+[English](../../en_US/tutorials/invdn.md) | 中文
+
+# 可逆去噪网络(InvDN):真实噪声移除的一个轻量级方案
+
+**Invertible Denoising Network: A Light Solution for Real Noise Removal** (CVPR 2021) 论文复现
+
+官方源码:[https://github.com/Yang-Liu1082/InvDN](https://github.com/Yang-Liu1082/InvDN)
+
+论文地址:[https://arxiv.org/abs/2104.10546](https://arxiv.org/abs/2104.10546)
+
+## 1、简介
+
+InvDN利用可逆网络把噪声图片分成低解析度干净图片和高频潜在表示, 其中高频潜在表示中含有噪声信息和内容信息。由于可逆网络是无损的, 如果我们能够将高频表示中的噪声信息分离, 那么就可以将其和低解析度干净图片一起重构成原分辨率的干净图片。但实际上去除高频信息中的噪声是很困难的, 本文通过直接将带有噪声的高频潜在表示替换为在还原过程中从先验分布中采样的另一个表示,进而结合低解析度干净图片重构回原分辨率干净图片。本文所实现网络是轻量级的, 且效果较好。
+
+
+
+## 2 如何使用
+
+### 2.1 快速体验
+
+安装`PaddleGAN`之后进入`PaddleGAN`文件夹下,运行如下命令即生成修复后的图像`./output_dir/Denoising/image_name.png`
+
+```sh
+python applications/tools/invdn_denoising.py --images_path ${PATH_OF_IMAGE}
+```
+其中`PATH_OF_IMAGE`为你需要去噪的图像路径,或图像所在文件夹的路径。
+
+- 注意,作者原代码中,测试时使用了蒙特卡洛自集成(Monte Carlo self-ensemble)以提高性能,但是会拖慢速度。用户可以自由选择是否使用 `--disable_mc` 参数来关闭蒙特卡洛自集成以提高速度。($test$ 时默认开启蒙特卡洛自集成,而 $train$ 和 $valid$ 时默认关闭蒙特卡洛自集成。)
+
+### 2.2 数据准备
+
+#### **训练数据**
+
+本文所使用的数据集为SIDD,其中训练集为 [SIDD-Medium](https://www.eecs.yorku.ca/~kamel/sidd/dataset.php)。按照论文要求,需要将数据集处理为 $512 \times 512$ 的 patches。此外,本文训练时需要产生低分辨率版本的GT图像,其尺寸为 $128 \times 128$。将低分辨率图像记作LQ。
+
+已经处理好的数据,放在了 [Ai Studio](https://aistudio.baidu.com/aistudio/datasetdetail/172084) 里。
+
+训练数据放在:`data/SIDD_Medium_Srgb_Patches_512/train/` 下。
+
+#### **测试数据**
+
+验证集为 [SIDD_valid](https://www.eecs.yorku.ca/~kamel/sidd/dataset.php)。官网下载的验证集为 `./ValidationNoisyBlocksSrgb.mat 和 ./ValidationGtBlocksSrgb.mat`,建议转换为 $.png$ 格式更为方便。
+
+已经转换好的数据,放在了 [Ai Studio](https://aistudio.baidu.com/aistudio/datasetdetail/172069) 里。
+
+验证集数据放在:`data/SIDD_Valid_Srgb_Patches_256/valid/` 下。
+
+- 经过处理之后,`PaddleGAN/data` 文件夹下的文件结构为
+```sh
+data
+├─ SIDD_Medium_Srgb_Patches_512
+│ └─ train
+│ ├─ GT
+│ │ 0_0.PNG
+│ │ ...
+│ ├─ LQ
+│ │ 0_0.PNG
+│ │ ...
+│ └─ Noisy
+│ 0_0.PNG
+│ ...
+│
+└─ SIDD_Valid_Srgb_Patches_256
+ └─ valid
+ ├─ GT
+ │ 0_0.PNG
+ │ ...
+ └─ Noisy
+ 0_0.PNG
+ ...
+```
+
+### 2.3 训练
+
+运行以下命令来快速开始训练:
+```sh
+python -u tools/main.py --config-file configs/invdn_denoising.yaml
+```
+- TIPS:
+在复现时,为了保证总 $epoch$ 数目和论文配置相同,我们需要确保 $ total\_batchsize*iter == 1gpus*14bs*600000iters$。同时 $batchsize$ 改变时也要确保 $batchsize/learning\_rate == 14/0.0002$ 。
+例如,在使用单机四卡时,将单卡 $batchsize$ 设置为14,此时实际的总 $batchsize$ 应为14*4,需要将总 $iters$ 设置为为150000,且学习率扩大到8e-4。
+
+### 2.4 测试
+
+运行以下命令来快速开始测试:
+```sh
+python tools/main.py --config-file configs/invdn_denoising.yaml --evaluate-only --load ${PATH_OF_WEIGHT}
+```
+
+## 3 结果展示
+
+去噪
+| 模型 | 数据集 | PSNR/SSIM |
+|---|---|---|
+| InvDN | SIDD | 39.29 / 0.956 |
+
+
+## 4 模型下载
+
+| 模型 | 下载地址 |
+|---|---|
+| InvDN| [InvDN_Denoising](https://paddlegan.bj.bcebos.com/models/InvDN_Denoising.pdparams) |
+
+
+
+# 参考文献
+
+- [https://arxiv.org/abs/2104.10546](https://arxiv.org/abs/2104.10546)
+
+```
+@article{liu2021invertible,
+ title={Invertible Denoising Network: A Light Solution for Real Noise Removal},
+ author={Liu, Yang and Qin, Zhenyue and Anwar, Saeed and Ji, Pan and Kim, Dongwoo and Caldwell, Sabrina and Gedeon, Tom},
+ journal={arXiv preprint arXiv:2104.10546},
+ year={2021}
+}
+```
diff --git a/docs/zh_CN/tutorials/lap_style.md b/docs/zh_CN/tutorials/lap_style.md
new file mode 100644
index 0000000000000000000000000000000000000000..7744ebb2a47cabf21d7778665ed7c48587775665
--- /dev/null
+++ b/docs/zh_CN/tutorials/lap_style.md
@@ -0,0 +1,116 @@
+
+# LapStyle
+
+ **LapStyle--拉普拉斯金字塔风格化网络**,是一种能够生成高质量风格化图的快速前馈风格化网络,能渐进地生成复杂的纹理迁移效果,同时能够在**512分辨率**下达到**100fps**的速度。可实现多种不同艺术风格的快速迁移,在艺术图像生成、滤镜等领域有广泛的应用。
+
+本文档提供CVPR2021论文"Drafting and Revision: Laplacian Pyramid Network for Fast High-Quality Artistic Style Transfer"的官方代码。
+
+## 1. 论文介绍
+
+艺术风格迁移的目的是将一个实例图像的艺术风格迁移到一个内容图像。目前,基于优化的方法已经取得了很好的合成质量,但昂贵的时间成本限制了其实际应用。
+
+同时,前馈方法仍然不能合成复杂风格,特别是存在全局和局部模式时。受绘制草图和修改细节这一常见绘画过程的启发,[论文](https://arxiv.org/pdf/2104.05376.pdf) 提出了一种新的前馈方法拉普拉斯金字塔网络(LapStyle)。
+
+LapStyle首先通过绘图网络(Drafting Network)传输低分辨率的全局风格模式。然后通过修正网络(Revision Network)对局部细节进行高分辨率的修正,它根据拉普拉斯滤波提取的图像纹理和草图产生图像残差。通过叠加具有多个拉普拉斯金字塔级别的修订网络,可以很容易地生成更高分辨率的细节。最终的样式化图像是通过聚合所有金字塔级别的输出得到的。论文还引入了一个补丁鉴别器,以更好地对抗的学习局部风格。实验表明,该方法能实时合成高质量的风格化图像,并能正确生成整体风格模式。
+
+
+
+## 2. 快速体验
+
+PaddleGAN为大家提供了四种不同艺术风格的预训练模型,风格预览如下:
+
+| 原图 | StarryNew | Stars | Ocean | Circuit |
+| :----------------------------------------------------------: | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
+|  |
|  |
|  |
|  |
|  |
+
+4个风格图像下载地址如下:
+| [StarryNew](https://user-images.githubusercontent.com/79366697/118655415-1ec8c000-b81c-11eb-8002-90bf8d477860.png) | [Stars](https://user-images.githubusercontent.com/79366697/118655423-20928380-b81c-11eb-92bd-0deeb320ff14.png) | [Ocean](https://user-images.githubusercontent.com/79366697/118655407-1c666600-b81c-11eb-83a6-300ee1952415.png) | [Circuit](https://user-images.githubusercontent.com/79366697/118655399-196b7580-b81c-11eb-8bc5-d5ece80c18ba.jpg)|
+
+只需运行下面的代码即可迁移至指定风格:
+
+```
+python applications/tools/lapstyle.py --content_img_path ${PATH_OF_CONTENT_IMG} --style_image_path ${PATH_OF_STYLE_IMG}
+```
+### **参数**
+
+- `--content_img_path (str)`: 输入的内容图像路径。
+- `--style_image_path (str)`: 输入的风格图像路径。
+- `--output_path (str)`: 输出的图像路径,默认为`output_dir`。
+- `--weight_path (str)`: 模型权重路径,设置`None`时会自行下载预训练模型,默认为`None`。
+- `--style (str)`: 生成图像风格,当`weight_path`为`None`时,可以在`starrynew`, `circuit`, `ocean` 和 `stars`中选择,默认为`starrynew`。
+
+## 3. 模型训练
+
+配置文件参数详情:[Config文件使用说明](../config_doc.md)
+
+### 3.1 数据准备
+
+为了训练LapStyle,我们使用COCO数据集作为内容图像数据集。您可以从[starrynew](https://user-images.githubusercontent.com/79366697/118655415-1ec8c000-b81c-11eb-8002-90bf8d477860.png),[ocean](https://user-images.githubusercontent.com/79366697/118655407-1c666600-b81c-11eb-83a6-300ee1952415.png),[stars](https://user-images.githubusercontent.com/79366697/118655423-20928380-b81c-11eb-92bd-0deeb320ff14.png)或[circuit](https://user-images.githubusercontent.com/79366697/118655399-196b7580-b81c-11eb-8bc5-d5ece80c18ba.jpg)中选择一张风格图片,也可以任意选择您喜欢的图片作为风格图片。在开始训练与测试之前,记得修改配置文件的数据路径。
+
+### 3.2 训练
+
+示例以COCO数据为例。如果您想使用自己的数据集,可以在配置文件中修改数据集为您自己的数据集。
+
+
|
+
+4个风格图像下载地址如下:
+| [StarryNew](https://user-images.githubusercontent.com/79366697/118655415-1ec8c000-b81c-11eb-8002-90bf8d477860.png) | [Stars](https://user-images.githubusercontent.com/79366697/118655423-20928380-b81c-11eb-92bd-0deeb320ff14.png) | [Ocean](https://user-images.githubusercontent.com/79366697/118655407-1c666600-b81c-11eb-83a6-300ee1952415.png) | [Circuit](https://user-images.githubusercontent.com/79366697/118655399-196b7580-b81c-11eb-8bc5-d5ece80c18ba.jpg)|
+
+只需运行下面的代码即可迁移至指定风格:
+
+```
+python applications/tools/lapstyle.py --content_img_path ${PATH_OF_CONTENT_IMG} --style_image_path ${PATH_OF_STYLE_IMG}
+```
+### **参数**
+
+- `--content_img_path (str)`: 输入的内容图像路径。
+- `--style_image_path (str)`: 输入的风格图像路径。
+- `--output_path (str)`: 输出的图像路径,默认为`output_dir`。
+- `--weight_path (str)`: 模型权重路径,设置`None`时会自行下载预训练模型,默认为`None`。
+- `--style (str)`: 生成图像风格,当`weight_path`为`None`时,可以在`starrynew`, `circuit`, `ocean` 和 `stars`中选择,默认为`starrynew`。
+
+## 3. 模型训练
+
+配置文件参数详情:[Config文件使用说明](../config_doc.md)
+
+### 3.1 数据准备
+
+为了训练LapStyle,我们使用COCO数据集作为内容图像数据集。您可以从[starrynew](https://user-images.githubusercontent.com/79366697/118655415-1ec8c000-b81c-11eb-8002-90bf8d477860.png),[ocean](https://user-images.githubusercontent.com/79366697/118655407-1c666600-b81c-11eb-83a6-300ee1952415.png),[stars](https://user-images.githubusercontent.com/79366697/118655423-20928380-b81c-11eb-92bd-0deeb320ff14.png)或[circuit](https://user-images.githubusercontent.com/79366697/118655399-196b7580-b81c-11eb-8bc5-d5ece80c18ba.jpg)中选择一张风格图片,也可以任意选择您喜欢的图片作为风格图片。在开始训练与测试之前,记得修改配置文件的数据路径。
+
+### 3.2 训练
+
+示例以COCO数据为例。如果您想使用自己的数据集,可以在配置文件中修改数据集为您自己的数据集。
+
+
+

+
+

+
 |
|  |
+
+### 2. 模型训练
+#### **数据集:**
+
+- fashion 可以参考[这里](https://vision.cs.ubc.ca/datasets/fashion/)
+- VoxCeleb 可以参考[这里](https://github.com/AliaksandrSiarohin/video-preprocessing). 将数据按照需求处理为想要的大小,即可开始训练,这里我们处理了256和512两种分辨率大小,结果对比如下:
+
-**参数说明:**
-- driving_video: 驱动视频,视频中人物的表情动作作为待迁移的对象
-- source_image: 原始图片,视频中人物的表情动作将迁移到该原始图片中的人物上
-- relative: 指示程序中使用视频和图片中人物关键点的相对坐标还是绝对坐标,建议使用相对坐标,若使用绝对坐标,会导致迁移后人物扭曲变形
-- adapt_scale: 根据关键点凸包自适应运动尺度
+#### **参数说明:**
+- dataset_name.yaml: 需要配置自己的yaml文件及参数
+
+- GPU单卡训练:
+```
+export CUDA_VISIBLE_DEVICES=0
+python tools/main.py --config-file configs/dataset_name.yaml
+```
+- GPU多卡训练:
+需要将 “/ppgan/modules/first_order.py”中的nn.BatchNorm 改为nn.SyncBatchNorm
+```
+export CUDA_VISIBLE_DEVICES=0,1,2,3
+python -m paddle.distributed.launch \
+ tools/main.py \
+ --config-file configs/dataset_name.yaml \
+
+```
+
+**例如:**
+- GPU单卡训练:
+```
+export CUDA_VISIBLE_DEVICES=0
+python tools/main.py --config-file configs/firstorder_fashion.yaml
+```
+- GPU多卡训练:
+```
+export CUDA_VISIBLE_DEVICES=0,1,2,3
+python -m paddle.distributed.launch \
+ tools/main.py \
+ --config-file configs/firstorder_fashion.yaml \
+```
## 生成结果展示
-
+
|
+
+### 2. 模型训练
+#### **数据集:**
+
+- fashion 可以参考[这里](https://vision.cs.ubc.ca/datasets/fashion/)
+- VoxCeleb 可以参考[这里](https://github.com/AliaksandrSiarohin/video-preprocessing). 将数据按照需求处理为想要的大小,即可开始训练,这里我们处理了256和512两种分辨率大小,结果对比如下:
+
-**参数说明:**
-- driving_video: 驱动视频,视频中人物的表情动作作为待迁移的对象
-- source_image: 原始图片,视频中人物的表情动作将迁移到该原始图片中的人物上
-- relative: 指示程序中使用视频和图片中人物关键点的相对坐标还是绝对坐标,建议使用相对坐标,若使用绝对坐标,会导致迁移后人物扭曲变形
-- adapt_scale: 根据关键点凸包自适应运动尺度
+#### **参数说明:**
+- dataset_name.yaml: 需要配置自己的yaml文件及参数
+
+- GPU单卡训练:
+```
+export CUDA_VISIBLE_DEVICES=0
+python tools/main.py --config-file configs/dataset_name.yaml
+```
+- GPU多卡训练:
+需要将 “/ppgan/modules/first_order.py”中的nn.BatchNorm 改为nn.SyncBatchNorm
+```
+export CUDA_VISIBLE_DEVICES=0,1,2,3
+python -m paddle.distributed.launch \
+ tools/main.py \
+ --config-file configs/dataset_name.yaml \
+
+```
+
+**例如:**
+- GPU单卡训练:
+```
+export CUDA_VISIBLE_DEVICES=0
+python tools/main.py --config-file configs/firstorder_fashion.yaml
+```
+- GPU多卡训练:
+```
+export CUDA_VISIBLE_DEVICES=0,1,2,3
+python -m paddle.distributed.launch \
+ tools/main.py \
+ --config-file configs/firstorder_fashion.yaml \
+```
## 生成结果展示
-
+
+

+
+
+
+
+
+
+
 +
+- [RCAN遥感影像超分辨率重建 Ai studio 项目在线体验](https://aistudio.baidu.com/aistudio/projectdetail/3508912)
+
diff --git a/docs/zh_CN/tutorials/singan.md b/docs/zh_CN/tutorials/singan.md
new file mode 100755
index 0000000000000000000000000000000000000000..1656a55a3362253db5036850be3f2efe253ec25a
--- /dev/null
+++ b/docs/zh_CN/tutorials/singan.md
@@ -0,0 +1,147 @@
+# SinGAN
+
+## 简介
+
+SinGAN是一种新的可以从单个自然图像中学习的无条件生成模型。该模型包含一个全卷积生成对抗网络的金字塔结构,每个生成对抗网络负责学习不同在不同比例的图像上的块分布。这允许生成任意大小和纵横比的新样本,具有显著的可变性,但同时保持训练图像的全局结构和精细纹理。与以往单一图像生成方案相比,该方法不局限于纹理图像,也没有条件(即从噪声中生成样本)。
+
+## 使用方法
+
+### 配置说明
+
+我们为SinGAN提供了4个配置文件:
+
+- `singan_universal.yaml`
+- `singan_sr.yaml`
+- `singan_animation.yaml`
+- `singan_finetune.yaml`
+
+其中`singan_universal.yaml`对所有任务都适用配置,`singan_sr.yaml`是官方建议的用于超分任务的配置,`singan_animation.yaml`是官方建议的用于“静图转动”任务的配置。本文档展示的结果均由`singan_universal.yaml`训练而来。对于手绘转照片任务,使用`singan_universal.yaml`训练后再用`singan_finetune.yaml`微调会得到更好的结果。
+
+### 训练
+
+启动训练:
+
+```bash
+python tools/main.py -c configs/singan_universal.yaml \
+ -o model.train_image=训练图片.png
+```
+
+为“手绘转照片”任务微调:
+
+```bash
+python tools/main.py -c configs/singan_finetune.yaml \
+ -o model.train_image=训练图片.png \
+ --load 已经训练好的模型.pdparams
+```
+
+### 测试
+运行下面的命令,可以随机生成一张图片。需要注意的是,`训练图片.png`应当位于`data/singan`目录下,或者手动调整配置文件中`dataset.test.dataroot`的值。此外,这个目录中只能包含`训练图片.png`这一张图片。
+```bash
+python tools/main.py -c configs/singan_universal.yaml \
+ -o model.train_image=训练图片.png \
+ --load 已经训练好的模型.pdparams \
+ --evaluate-only
+```
+
+### 导出生成器权重
+
+训练结束后,需要使用 ``tools/extract_weight.py`` 来从训练模型(包含了生成器和判别器)中提取生成器的权重来给`applications/tools/singan.py`进行推理,以实现SinGAN的各种应用。
+
+```bash
+python tools/extract_weight.py 训练过程中保存的权重文件.pdparams --net-name netG --output 生成器权重文件.pdparams
+```
+
+### 推理及结果展示
+
+*注意:您可以下面的命令中的`--weight_path 生成器权重文件.pdparams`可以换成`--pretrained_model `来体验训练好的模型,其中``可以是`trees`、`stone`、`mountains`、`birds`和`lightning`。*
+
+#### 随机采样
+
+```bash
+python applications/tools/singan.py \
+ --weight_path 生成器权重文件.pdparams \
+ --mode random_sample \
+ --scale_v 1 \ # vertical scale
+ --scale_h 1 \ # horizontal scale
+ --n_row 2 \
+ --n_col 2
+```
+
+|训练图片|随机采样结果|
+| ---- | ---- |
+|||
+
+#### 图像编辑&风格和谐化
+
+```bash
+python applications/tools/singan.py \
+ --weight_path 生成器权重文件.pdparams \
+ --mode editing \ # or harmonization
+ --ref_image 编辑后的图片.png \
+ --mask_image 编辑区域标注图片.png \
+ --generate_start_scale 2
+```
+
+
+|训练图片|编辑图片|编辑区域标注|SinGAN生成|
+|----|----|----|----|
+|||||
+
+#### 超分
+
+```bash
+python applications/tools/singan.py \
+ --weight_path 生成器权重文件.pdparams \
+ --mode sr \
+ --ref_image 待超分的图片亦即用于训练的图片.png \
+ --sr_factor 4
+```
+|训练图片|超分结果|
+| ---- | ---- |
+|||
+
+
+#### 静图转动
+
+```bash
+python applications/tools/singan.py \
+ --weight_path 生成器权重文件.pdparams \
+ --mode animation \
+ --animation_alpha 0.6 \ # this parameter determines how close the frames of the sequence remain to the training image
+ --animation_beta 0.7 \ # this parameter controls the smoothness and rate of change in the generated clip
+ --animation_frames 20 \ # frames of animation
+ --animation_duration 0.1 # duration of each frame
+```
+
+|训练图片|动画效果|
+| ---- | ---- |
+|||
+
+
+#### 手绘转照片
+```bash
+python applications/tools/singan.py \
+ --weight_path 生成器权重文件.pdparams \
+ --mode paint2image \
+ --ref_image 手绘图片.png \
+ --generate_start_scale 2
+```
+|训练图片|手绘图片|SinGAN生成|SinGAN微调后生成|
+|----|----|----|----|
+|||||
+
+
+
+## 参考文献
+
+```
+@misc{shaham2019singan,
+ title={SinGAN: Learning a Generative Model from a Single Natural Image},
+ author={Tamar Rott Shaham and Tali Dekel and Tomer Michaeli},
+ year={2019},
+ eprint={1905.01164},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+}
+```
+
diff --git a/docs/zh_CN/tutorials/single_image_super_resolution.md b/docs/zh_CN/tutorials/single_image_super_resolution.md
new file mode 100644
index 0000000000000000000000000000000000000000..b4e43acf675624cf5dac74e27eef949a205a5479
--- /dev/null
+++ b/docs/zh_CN/tutorials/single_image_super_resolution.md
@@ -0,0 +1,199 @@
+# 1 单张图像超分
+
+## 1.1 原理介绍
+
+ 超分是放大和改善图像细节的过程。它通常将低分辨率图像作为输入,将同一图像放大到更高分辨率作为输出。这里我们提供了四种超分辨率模型,即[RealSR](https://openaccess.thecvf.com/content_CVPRW_2020/papers/w31/Ji_Real-World_Super-Resolution_via_Kernel_Estimation_and_Noise_Injection_CVPRW_2020_paper.pdf), [ESRGAN](https://arxiv.org/abs/1809.00219v2), [LESRCNN](https://arxiv.org/abs/2007.04344),[PAN](https://arxiv.org/pdf/2010.01073.pdf).
+ [RealSR](https://openaccess.thecvf.com/content_CVPRW_2020/papers/w31/Ji_Real-World_Super-Resolution_via_Kernel_Estimation_and_Noise_Injection_CVPRW_2020_paper.pdf)通过估计各种模糊内核以及实际噪声分布,为现实世界的图像设计一种新颖的真实图片降采样框架。基于该降采样框架,可以获取与真实世界图像共享同一域的低分辨率图像。RealSR是一个旨在提高感知度的真实世界超分辨率模型。对合成噪声数据和真实世界图像进行的大量实验表明,RealSR模型能够有效降低了噪声并提高了视觉质量。
+ [ESRGAN](https://arxiv.org/abs/1809.00219v2)是增强型SRGAN,为了进一步提高SRGAN的视觉质量,ESRGAN在SRGAN的基础上改进了SRGAN的三个关键组件。此外,ESRGAN还引入了未经批量归一化的剩余密集块(RRDB)作为基本的网络构建单元,让鉴别器预测相对真实性而不是绝对值,并利用激活前的特征改善感知损失。得益于这些改进,提出的ESRGAN实现了比SRGAN更好的视觉质量和更逼真、更自然的纹理,并在PIRM2018-SR挑战赛中获得第一名。
+ 考虑到CNNs在SISR的应用上往往会消耗大量的计算量和存储空间来训练SR模型。轻量级增强SR-CNN([LESRCNN](https://arxiv.org/abs/2007.04344))被提出。大量实验表明,LESRCNN在定性和定量评价方面优于现有的SISR算法。
+ 之后[PAN](https://arxiv.org/pdf/2010.01073.pdf)设计了一种用于图像超分辨率(SR)的轻量级卷积神经网络。
+
+
+
+## 1.2 如何使用
+
+### 1.2.1 数据准备
+
+ 常用的图像超分数据集如下:
+ | name | 数据集 | 数据描述 | 下载 |
+ |---|---|---|---|
+ | 2K Resolution | [DIV2K](https://data.vision.ee.ethz.ch/cvl/DIV2K/) | proposed in [NTIRE17](https://data.vision.ee.ethz.ch/cvl/ntire17//) (800 train and 100 validation) | [official website](https://data.vision.ee.ethz.ch/cvl/DIV2K/) |
+ | Classical SR Testing | Set5 | Set5 test dataset | [Google Drive](https://drive.google.com/drive/folders/1B3DJGQKB6eNdwuQIhdskA64qUuVKLZ9u) / [Baidu Drive](https://pan.baidu.com/s/1q_1ERCMqALH0xFwjLM0pTg#list/path=%2Fsharelink2016187762-785433459861126%2Fclassical_SR_datasets&parentPath=%2Fsharelink2016187762-785433459861126) |
+ | Classical SR Testing | Set14 | Set14 test dataset | [Google Drive](https://drive.google.com/drive/folders/1B3DJGQKB6eNdwuQIhdskA64qUuVKLZ9u) / [Baidu Drive](https://pan.baidu.com/s/1q_1ERCMqALH0xFwjLM0pTg#list/path=%2Fsharelink2016187762-785433459861126%2Fclassical_SR_datasets&parentPath=%2Fsharelink2016187762-785433459861126) |
+
+ 数据集DIV2K, Set5 和 Set14 的组成形式如下:
+ ```
+ PaddleGAN
+ ├── data
+ ├── DIV2K
+ ├── DIV2K_train_HR
+ ├── DIV2K_train_LR_bicubic
+ | ├──X2
+ | ├──X3
+ | └──X4
+ ├── DIV2K_valid_HR
+ ├── DIV2K_valid_LR_bicubic
+ Set5
+ ├── GTmod12
+ ├── LRbicx2
+ ├── LRbicx3
+ ├── LRbicx4
+ └── original
+ Set14
+ ├── GTmod12
+ ├── LRbicx2
+ ├── LRbicx3
+ ├── LRbicx4
+ └── original
+ ...
+ ```
+ 使用以下命令处理DIV2K数据集:
+ ```
+ python data/process_div2k_data.py --data-root data/DIV2K
+ ```
+ 程序完成后,检查DIV2K目录中是否有``DIV2K_train_HR_sub``、``X2_sub``、``X3_sub``和``X4_sub``目录
+ ```
+ PaddleGAN
+ ├── data
+ ├── DIV2K
+ ├── DIV2K_train_HR
+ ├── DIV2K_train_HR_sub
+ ├── DIV2K_train_LR_bicubic
+ | ├──X2
+ | ├──X2_sub
+ | ├──X3
+ | ├──X3_sub
+ | ├──sX4
+ | └──X4_sub
+ ├── DIV2K_valid_HR
+ ├── DIV2K_valid_LR_bicubic
+ ...
+ ```
+
+#### Realsr df2k model的数据准备
+
+ 从 [NTIRE 2020 RWSR](https://competitions.codalab.org/competitions/22220#participate) 下载数据集并解压到您的路径下。
+ 将 Corrupted-tr-x.zip 和 Corrupted-tr-y.zip 解压到 ``PaddleGAN/data/ntire20`` 目录下。
+
+ 运行如下命令:
+ ```
+ python ./data/realsr_preprocess/create_bicubic_dataset.py --dataset df2k --artifacts tdsr
+ python ./data/realsr_preprocess/collect_noise.py --dataset df2k --artifacts tdsr
+ ```
+
+### 1.2.2 训练/测试
+
+ 示例以df2k数据集和RealSR模型为例。如果您想使用自己的数据集,可以在配置文件中修改数据集为您自己的数据集。如果您想使用其他模型,可以通过替换配置文件。
+
+ 训练模型:
+ ```
+ python -u tools/main.py --config-file configs/realsr_bicubic_noise_x4_df2k.yaml
+ ```
+
+ 测试模型:
+ ```
+ python tools/main.py --config-file configs/realsr_bicubic_noise_x4_df2k.yaml --evaluate-only --load ${PATH_OF_WEIGHT}
+ ```
+
+## 1.3 实验结果展示
+实验数值结果是在 RGB 通道上进行评估,并在评估之前裁剪每个边界的尺度像素。
+
+度量指标为 PSNR / SSIM.
+
+| 模型 | Set5 | Set14 | DIV2K |
+|---|---|---|---|
+| realsr_df2k | 28.4385 / 0.8106 | 24.7424 / 0.6678 | 26.7306 / 0.7512 |
+| realsr_dped | 20.2421 / 0.6158 | 19.3775 / 0.5259 | 20.5976 / 0.6051 |
+| realsr_merge | 24.8315 / 0.7030 | 23.0393 / 0.5986 | 24.8510 / 0.6856 |
+| lesrcnn_x4 | 31.9476 / 0.8909 | 28.4110 / 0.7770 | 30.231 / 0.8326 |
+| esrgan_psnr_x4 | 32.5512 / 0.8991 | 28.8114 / 0.7871 | 30.7565 / 0.8449 |
+| esrgan_x4 | 28.7647 / 0.8187 | 25.0065 / 0.6762 | 26.9013 / 0.7542 |
+| pan_x4 | 30.4574 / 0.8643 | 26.7204 / 0.7434 | 28.9187 / 0.8176 |
+| drns_x4 | 32.6684 / 0.8999 | 28.9037 / 0.7885 | - |
+
+PAN指标对比
+
+paddle模型使用DIV2K数据集训练,torch模型使用df2k和DIV2K数据集训练。
+
+| 框架 | Set5 | Set14 |
+|---|---|---|
+| paddle | 30.4574 / 0.8643 | 26.7204 / 0.7434 |
+| torch | 30.2183 / 0.8643 | 26.8035 / 0.7445 |
+
+
+
+
+## 1.4 模型下载
+| 模型 | 数据集 | 下载地址 |
+|---|---|---|
+| realsr_df2k | df2k | [realsr_df2k](https://paddlegan.bj.bcebos.com/models/realsr_df2k.pdparams)
+| realsr_dped | dped | [realsr_dped](https://paddlegan.bj.bcebos.com/models/realsr_dped.pdparams)
+| realsr_merge | DIV2K | [realsr_merge](https://paddlegan.bj.bcebos.com/models/realsr_merge.pdparams)
+| lesrcnn_x4 | DIV2K | [lesrcnn_x4](https://paddlegan.bj.bcebos.com/models/lesrcnn_x4.pdparams)
+| esrgan_psnr_x4 | DIV2K | [esrgan_psnr_x4](https://paddlegan.bj.bcebos.com/models/esrgan_psnr_x4.pdparams)
+| esrgan_x4 | DIV2K | [esrgan_x4](https://paddlegan.bj.bcebos.com/models/esrgan_x4.pdparams)
+| pan_x4 | DIV2K | [pan_x4](https://paddlegan.bj.bcebos.com/models/pan_x4.pdparams)
+| drns_x4 | DIV2K | [drns_x4](https://paddlegan.bj.bcebos.com/models/DRNSx4.pdparams)
+
+
+# 参考文献
+
+- 1. [Real-World Super-Resolution via Kernel Estimation and Noise Injection](https://openaccess.thecvf.com/content_CVPRW_2020/papers/w31/Ji_Real-World_Super-Resolution_via_Kernel_Estimation_and_Noise_Injection_CVPRW_2020_paper.pdf)
+
+ ```
+ @inproceedings{ji2020real,
+ title={Real-World Super-Resolution via Kernel Estimation and Noise Injection},
+ author={Ji, Xiaozhong and Cao, Yun and Tai, Ying and Wang, Chengjie and Li, Jilin and Huang, Feiyue},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops},
+ pages={466--467},
+ year={2020}
+ }
+ ```
+
+- 2. [ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks](https://arxiv.org/abs/1809.00219v2)
+
+ ```
+ @inproceedings{wang2018esrgan,
+ title={Esrgan: Enhanced super-resolution generative adversarial networks},
+ author={Wang, Xintao and Yu, Ke and Wu, Shixiang and Gu, Jinjin and Liu, Yihao and Dong, Chao and Qiao, Yu and Change Loy, Chen},
+ booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
+ pages={0--0},
+ year={2018}
+ }
+ ```
+
+- 3. [Lightweight image super-resolution with enhanced CNN](https://arxiv.org/abs/2007.04344)
+
+ ```
+ @article{tian2020lightweight,
+ title={Lightweight image super-resolution with enhanced CNN},
+ author={Tian, Chunwei and Zhuge, Ruibin and Wu, Zhihao and Xu, Yong and Zuo, Wangmeng and Chen, Chen and Lin, Chia-Wen},
+ journal={Knowledge-Based Systems},
+ volume={205},
+ pages={106235},
+ year={2020},
+ publisher={Elsevier}
+ }
+ ```
+- 4. [Efficient Image Super-Resolution Using Pixel Attention](https://arxiv.org/pdf/2010.01073.pdf)
+
+ ```
+ @inproceedings{Hengyuan2020Efficient,
+ title={Efficient Image Super-Resolution Using Pixel Attention},
+ author={Hengyuan Zhao and Xiangtao Kong and Jingwen He and Yu Qiao and Chao Dong},
+ booktitle={Computer Vision – ECCV 2020 Workshops},
+ volume={12537},
+ pages={56-72},
+ year={2020}
+ }
+ ```
+ - 5. [Closed-loop Matters: Dual Regression Networks for Single Image Super-Resolution](https://arxiv.org/pdf/2003.07018.pdf)
+
+ ```
+ @inproceedings{guo2020closed,
+ title={Closed-loop Matters: Dual Regression Networks for Single Image Super-Resolution},
+ author={Guo, Yong and Chen, Jian and Wang, Jingdong and Chen, Qi and Cao, Jiezhang and Deng, Zeshuai and Xu, Yanwu and Tan, Mingkui},
+ booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
+ year={2020}
+ }
+ ```
diff --git a/docs/zh_CN/tutorials/starganv2.md b/docs/zh_CN/tutorials/starganv2.md
new file mode 100644
index 0000000000000000000000000000000000000000..7960fb92fd8903ba4111f03a125cd854c5d8e26e
--- /dev/null
+++ b/docs/zh_CN/tutorials/starganv2.md
@@ -0,0 +1,74 @@
+# StarGAN V2
+
+## 1 原理介绍
+
+ [StarGAN V2](https://arxiv.org/pdf/1912.01865.pdf)是发布在CVPR2020上的一个图像转换模型。
+ 一个好的图像到图像转换模型应该学习不同视觉域之间的映射,同时满足以下属性:1)生成图像的多样性和 2)多个域的可扩展性。 现有方法只解决了其中一个问题,领域的多样性有限或对所有领域用多个模型。 StarGAN V2是一个单一的框架,可以同时解决这两个问题,并在基线上显示出显着改善的结果。 CelebAHQ 和新的动物面孔数据集 (AFHQ) 上的实验验证了StarGAN V2在视觉质量、多样性和可扩展性方面的优势。
+
+## 2 如何使用
+
+### 2.1 数据准备
+
+ StarGAN V2使用的CelebAHQ数据集可以从[这里](https://www.dropbox.com/s/f7pvjij2xlpff59/celeba_hq.zip?dl=0)下载,使用的AFHQ数据集可以从[这里](https://www.dropbox.com/s/t9l9o3vsx2jai3z/afhq.zip?dl=0)下载。将数据集下载解压后放到``PaddleGAN/data``文件夹下 。
+
+ 数据的组成形式为:
+
+ ```
+ ├── data
+ ├── afhq
+ | ├── train
+ | | ├── cat
+ | | ├── dog
+ | | └── wild
+ | └── val
+ | ├── cat
+ | ├── dog
+ | └── wild
+ └── celeba_hq
+ ├── train
+ | ├── female
+ | └── male
+ └── val
+ ├── female
+ └── male
+
+ ```
+
+### 2.2 训练/测试
+
+ 示例以AFHQ数据集为例。如果您想使用CelebAHQ数据集,可以在换一下配置文件。
+
+ 训练模型:
+ ```
+ python -u tools/main.py --config-file configs/starganv2_afhq.yaml
+ ```
+
+ 测试模型:
+ ```
+ python tools/main.py --config-file configs/starganv2_afhq.yaml --evaluate-only --load ${PATH_OF_WEIGHT}
+ ```
+
+## 3 结果展示
+
+
+
+## 4 模型下载
+| 模型 | 数据集 | 下载地址 |
+|---|---|---|
+| starganv2_afhq | AFHQ | [starganv2_afhq](https://paddlegan.bj.bcebos.com/models/starganv2_afhq.pdparams)
+
+
+
+
+# 参考文献
+
+- 1. [StarGAN v2: Diverse Image Synthesis for Multiple Domains](https://arxiv.org/abs/1912.01865)
+
+ ```
+ @inproceedings{choi2020starganv2,
+ title={StarGAN v2: Diverse Image Synthesis for Multiple Domains},
+ author={Yunjey Choi and Youngjung Uh and Jaejun Yoo and Jung-Woo Ha},
+ booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
+ year={2020}
+ }
+ ```
diff --git a/docs/zh_CN/tutorials/styleganv2.md b/docs/zh_CN/tutorials/styleganv2.md
index 7ebab5e1ff14af2fdca8769515b40736491a6029..7140bc5240953e9e838b1586def9d14b75ff4719 100644
--- a/docs/zh_CN/tutorials/styleganv2.md
+++ b/docs/zh_CN/tutorials/styleganv2.md
@@ -54,9 +54,56 @@ python -u tools/styleganv2.py \
- n_col: 采样的图片的列数
- cpu: 是否使用cpu推理,若不使用,请在命令中去除
-### 训练(TODO)
+### 训练
+
+#### 准备数据集
+你可以从[这里](https://drive.google.com/drive/folders/1u2xu7bSrWxrbUxk-dT-UvEJq8IjdmNTP)下载对应的数据集
+
+为了方便,我们提供了[images256x256.tar](https://paddlegan.bj.bcebos.com/datasets/images256x256.tar)
+
+目前的配置文件默认数据集的结构如下:
+ ```
+ PaddleGAN
+ ├── data
+ ├── ffhq
+ ├──images1024x1024
+ ├── 00000.png
+ ├── 00001.png
+ ├── 00002.png
+ ├── 00003.png
+ ├── 00004.png
+ ├──images256x256
+ ├── 00000.png
+ ├── 00001.png
+ ├── 00002.png
+ ├── 00003.png
+ ├── 00004.png
+ ├──custom_data
+ ├── img0.png
+ ├── img1.png
+ ├── img2.png
+ ├── img3.png
+ ├── img4.png
+ ...
+ ```
+
+启动训练
+```
+python tools/main.py -c configs/stylegan_v2_256_ffhq.yaml
+```
+
+### 推理
+
+训练结束后,需要使用 ``tools/extract_weight.py`` 来提取对应的权重给``applications/tools/styleganv2.py``来进行推理.
+```
+python tools/extract_weight.py output_dir/YOUR_TRAINED_WEIGHT.pdparams --net-name gen_ema --output YOUR_WEIGHT_PATH.pdparams
+```
+
+```
+python tools/styleganv2.py --output_path stylegan01 --weight_path YOUR_WEIGHT_PATH.pdparams --size 256
+```
-未来还将添加训练脚本方便用户训练出更多类型的 StyleGAN V2 图像生成器。
+注意: ``--size`` 这个参数要和配置文件中的参数保持一致.
## 生成结果展示
diff --git a/docs/zh_CN/tutorials/styleganv2clip.md b/docs/zh_CN/tutorials/styleganv2clip.md
new file mode 100644
index 0000000000000000000000000000000000000000..733b90ea06d0057aa7dac44fad227c72b07a60a1
--- /dev/null
+++ b/docs/zh_CN/tutorials/styleganv2clip.md
@@ -0,0 +1,167 @@
+# StyleCLIP: 文本驱动的图像处理
+## 1. 简介
+
+StyleGAN V2 的任务是使用风格向量进行image generation,而Clip guided Editing 则是利用CLIP (Contrastive Language-Image Pre-training ) 多模态预训练模型计算文本输入对应的风格向量变化,用文字表述来对图像进行编辑操纵风格向量进而操纵生成图像的属性。相比于Editing 模块,StyleCLIP不受预先统计的标注属性限制,可以通过语言描述自由控制图像编辑。
+
+原论文中使用 Pixel2Style2Pixel 的 升级模型 Encode4Editing 计算要编辑的代表图像的风格向量,为尽量利用PaddleGAN提供的预训练模型本次复现中仍使用Pixel2Style2Pixel计算得到风格向量进行实验,重构效果略有下降,期待PaddleGAN跟进e4e相关工作。
+
+
+## 2. 复现
+
+StyleCLIP 模型 需要使用简介中对应提到的几个预训练模型,
+本次复现使用PPGAN 提供的 在FFHQ数据集上进行预训练的StyleGAN V2 模型作为生成器,并使用Pixel2Style2Pixel模型将待编辑图像转换为对应风格向量。
+
+CLIP模型依赖Paddle-CLIP实现。
+pSp模型包含人脸检测步骤,依赖dlib框架。
+除本repo外还需要安装 Paddle-CLIP 和 dlib 依赖。
+
+整体安装方法如下。
+```
+pip install -e .
+pip install paddleclip
+pip install dlib-bin
+```
+
+### 编辑结果展示
+
+风格向量对应的图像:
+
+
+- [RCAN遥感影像超分辨率重建 Ai studio 项目在线体验](https://aistudio.baidu.com/aistudio/projectdetail/3508912)
+
diff --git a/docs/zh_CN/tutorials/singan.md b/docs/zh_CN/tutorials/singan.md
new file mode 100755
index 0000000000000000000000000000000000000000..1656a55a3362253db5036850be3f2efe253ec25a
--- /dev/null
+++ b/docs/zh_CN/tutorials/singan.md
@@ -0,0 +1,147 @@
+# SinGAN
+
+## 简介
+
+SinGAN是一种新的可以从单个自然图像中学习的无条件生成模型。该模型包含一个全卷积生成对抗网络的金字塔结构,每个生成对抗网络负责学习不同在不同比例的图像上的块分布。这允许生成任意大小和纵横比的新样本,具有显著的可变性,但同时保持训练图像的全局结构和精细纹理。与以往单一图像生成方案相比,该方法不局限于纹理图像,也没有条件(即从噪声中生成样本)。
+
+## 使用方法
+
+### 配置说明
+
+我们为SinGAN提供了4个配置文件:
+
+- `singan_universal.yaml`
+- `singan_sr.yaml`
+- `singan_animation.yaml`
+- `singan_finetune.yaml`
+
+其中`singan_universal.yaml`对所有任务都适用配置,`singan_sr.yaml`是官方建议的用于超分任务的配置,`singan_animation.yaml`是官方建议的用于“静图转动”任务的配置。本文档展示的结果均由`singan_universal.yaml`训练而来。对于手绘转照片任务,使用`singan_universal.yaml`训练后再用`singan_finetune.yaml`微调会得到更好的结果。
+
+### 训练
+
+启动训练:
+
+```bash
+python tools/main.py -c configs/singan_universal.yaml \
+ -o model.train_image=训练图片.png
+```
+
+为“手绘转照片”任务微调:
+
+```bash
+python tools/main.py -c configs/singan_finetune.yaml \
+ -o model.train_image=训练图片.png \
+ --load 已经训练好的模型.pdparams
+```
+
+### 测试
+运行下面的命令,可以随机生成一张图片。需要注意的是,`训练图片.png`应当位于`data/singan`目录下,或者手动调整配置文件中`dataset.test.dataroot`的值。此外,这个目录中只能包含`训练图片.png`这一张图片。
+```bash
+python tools/main.py -c configs/singan_universal.yaml \
+ -o model.train_image=训练图片.png \
+ --load 已经训练好的模型.pdparams \
+ --evaluate-only
+```
+
+### 导出生成器权重
+
+训练结束后,需要使用 ``tools/extract_weight.py`` 来从训练模型(包含了生成器和判别器)中提取生成器的权重来给`applications/tools/singan.py`进行推理,以实现SinGAN的各种应用。
+
+```bash
+python tools/extract_weight.py 训练过程中保存的权重文件.pdparams --net-name netG --output 生成器权重文件.pdparams
+```
+
+### 推理及结果展示
+
+*注意:您可以下面的命令中的`--weight_path 生成器权重文件.pdparams`可以换成`--pretrained_model `来体验训练好的模型,其中``可以是`trees`、`stone`、`mountains`、`birds`和`lightning`。*
+
+#### 随机采样
+
+```bash
+python applications/tools/singan.py \
+ --weight_path 生成器权重文件.pdparams \
+ --mode random_sample \
+ --scale_v 1 \ # vertical scale
+ --scale_h 1 \ # horizontal scale
+ --n_row 2 \
+ --n_col 2
+```
+
+|训练图片|随机采样结果|
+| ---- | ---- |
+|||
+
+#### 图像编辑&风格和谐化
+
+```bash
+python applications/tools/singan.py \
+ --weight_path 生成器权重文件.pdparams \
+ --mode editing \ # or harmonization
+ --ref_image 编辑后的图片.png \
+ --mask_image 编辑区域标注图片.png \
+ --generate_start_scale 2
+```
+
+
+|训练图片|编辑图片|编辑区域标注|SinGAN生成|
+|----|----|----|----|
+|||||
+
+#### 超分
+
+```bash
+python applications/tools/singan.py \
+ --weight_path 生成器权重文件.pdparams \
+ --mode sr \
+ --ref_image 待超分的图片亦即用于训练的图片.png \
+ --sr_factor 4
+```
+|训练图片|超分结果|
+| ---- | ---- |
+|||
+
+
+#### 静图转动
+
+```bash
+python applications/tools/singan.py \
+ --weight_path 生成器权重文件.pdparams \
+ --mode animation \
+ --animation_alpha 0.6 \ # this parameter determines how close the frames of the sequence remain to the training image
+ --animation_beta 0.7 \ # this parameter controls the smoothness and rate of change in the generated clip
+ --animation_frames 20 \ # frames of animation
+ --animation_duration 0.1 # duration of each frame
+```
+
+|训练图片|动画效果|
+| ---- | ---- |
+|||
+
+
+#### 手绘转照片
+```bash
+python applications/tools/singan.py \
+ --weight_path 生成器权重文件.pdparams \
+ --mode paint2image \
+ --ref_image 手绘图片.png \
+ --generate_start_scale 2
+```
+|训练图片|手绘图片|SinGAN生成|SinGAN微调后生成|
+|----|----|----|----|
+|||||
+
+
+
+## 参考文献
+
+```
+@misc{shaham2019singan,
+ title={SinGAN: Learning a Generative Model from a Single Natural Image},
+ author={Tamar Rott Shaham and Tali Dekel and Tomer Michaeli},
+ year={2019},
+ eprint={1905.01164},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+}
+```
+
diff --git a/docs/zh_CN/tutorials/single_image_super_resolution.md b/docs/zh_CN/tutorials/single_image_super_resolution.md
new file mode 100644
index 0000000000000000000000000000000000000000..b4e43acf675624cf5dac74e27eef949a205a5479
--- /dev/null
+++ b/docs/zh_CN/tutorials/single_image_super_resolution.md
@@ -0,0 +1,199 @@
+# 1 单张图像超分
+
+## 1.1 原理介绍
+
+ 超分是放大和改善图像细节的过程。它通常将低分辨率图像作为输入,将同一图像放大到更高分辨率作为输出。这里我们提供了四种超分辨率模型,即[RealSR](https://openaccess.thecvf.com/content_CVPRW_2020/papers/w31/Ji_Real-World_Super-Resolution_via_Kernel_Estimation_and_Noise_Injection_CVPRW_2020_paper.pdf), [ESRGAN](https://arxiv.org/abs/1809.00219v2), [LESRCNN](https://arxiv.org/abs/2007.04344),[PAN](https://arxiv.org/pdf/2010.01073.pdf).
+ [RealSR](https://openaccess.thecvf.com/content_CVPRW_2020/papers/w31/Ji_Real-World_Super-Resolution_via_Kernel_Estimation_and_Noise_Injection_CVPRW_2020_paper.pdf)通过估计各种模糊内核以及实际噪声分布,为现实世界的图像设计一种新颖的真实图片降采样框架。基于该降采样框架,可以获取与真实世界图像共享同一域的低分辨率图像。RealSR是一个旨在提高感知度的真实世界超分辨率模型。对合成噪声数据和真实世界图像进行的大量实验表明,RealSR模型能够有效降低了噪声并提高了视觉质量。
+ [ESRGAN](https://arxiv.org/abs/1809.00219v2)是增强型SRGAN,为了进一步提高SRGAN的视觉质量,ESRGAN在SRGAN的基础上改进了SRGAN的三个关键组件。此外,ESRGAN还引入了未经批量归一化的剩余密集块(RRDB)作为基本的网络构建单元,让鉴别器预测相对真实性而不是绝对值,并利用激活前的特征改善感知损失。得益于这些改进,提出的ESRGAN实现了比SRGAN更好的视觉质量和更逼真、更自然的纹理,并在PIRM2018-SR挑战赛中获得第一名。
+ 考虑到CNNs在SISR的应用上往往会消耗大量的计算量和存储空间来训练SR模型。轻量级增强SR-CNN([LESRCNN](https://arxiv.org/abs/2007.04344))被提出。大量实验表明,LESRCNN在定性和定量评价方面优于现有的SISR算法。
+ 之后[PAN](https://arxiv.org/pdf/2010.01073.pdf)设计了一种用于图像超分辨率(SR)的轻量级卷积神经网络。
+
+
+
+## 1.2 如何使用
+
+### 1.2.1 数据准备
+
+ 常用的图像超分数据集如下:
+ | name | 数据集 | 数据描述 | 下载 |
+ |---|---|---|---|
+ | 2K Resolution | [DIV2K](https://data.vision.ee.ethz.ch/cvl/DIV2K/) | proposed in [NTIRE17](https://data.vision.ee.ethz.ch/cvl/ntire17//) (800 train and 100 validation) | [official website](https://data.vision.ee.ethz.ch/cvl/DIV2K/) |
+ | Classical SR Testing | Set5 | Set5 test dataset | [Google Drive](https://drive.google.com/drive/folders/1B3DJGQKB6eNdwuQIhdskA64qUuVKLZ9u) / [Baidu Drive](https://pan.baidu.com/s/1q_1ERCMqALH0xFwjLM0pTg#list/path=%2Fsharelink2016187762-785433459861126%2Fclassical_SR_datasets&parentPath=%2Fsharelink2016187762-785433459861126) |
+ | Classical SR Testing | Set14 | Set14 test dataset | [Google Drive](https://drive.google.com/drive/folders/1B3DJGQKB6eNdwuQIhdskA64qUuVKLZ9u) / [Baidu Drive](https://pan.baidu.com/s/1q_1ERCMqALH0xFwjLM0pTg#list/path=%2Fsharelink2016187762-785433459861126%2Fclassical_SR_datasets&parentPath=%2Fsharelink2016187762-785433459861126) |
+
+ 数据集DIV2K, Set5 和 Set14 的组成形式如下:
+ ```
+ PaddleGAN
+ ├── data
+ ├── DIV2K
+ ├── DIV2K_train_HR
+ ├── DIV2K_train_LR_bicubic
+ | ├──X2
+ | ├──X3
+ | └──X4
+ ├── DIV2K_valid_HR
+ ├── DIV2K_valid_LR_bicubic
+ Set5
+ ├── GTmod12
+ ├── LRbicx2
+ ├── LRbicx3
+ ├── LRbicx4
+ └── original
+ Set14
+ ├── GTmod12
+ ├── LRbicx2
+ ├── LRbicx3
+ ├── LRbicx4
+ └── original
+ ...
+ ```
+ 使用以下命令处理DIV2K数据集:
+ ```
+ python data/process_div2k_data.py --data-root data/DIV2K
+ ```
+ 程序完成后,检查DIV2K目录中是否有``DIV2K_train_HR_sub``、``X2_sub``、``X3_sub``和``X4_sub``目录
+ ```
+ PaddleGAN
+ ├── data
+ ├── DIV2K
+ ├── DIV2K_train_HR
+ ├── DIV2K_train_HR_sub
+ ├── DIV2K_train_LR_bicubic
+ | ├──X2
+ | ├──X2_sub
+ | ├──X3
+ | ├──X3_sub
+ | ├──sX4
+ | └──X4_sub
+ ├── DIV2K_valid_HR
+ ├── DIV2K_valid_LR_bicubic
+ ...
+ ```
+
+#### Realsr df2k model的数据准备
+
+ 从 [NTIRE 2020 RWSR](https://competitions.codalab.org/competitions/22220#participate) 下载数据集并解压到您的路径下。
+ 将 Corrupted-tr-x.zip 和 Corrupted-tr-y.zip 解压到 ``PaddleGAN/data/ntire20`` 目录下。
+
+ 运行如下命令:
+ ```
+ python ./data/realsr_preprocess/create_bicubic_dataset.py --dataset df2k --artifacts tdsr
+ python ./data/realsr_preprocess/collect_noise.py --dataset df2k --artifacts tdsr
+ ```
+
+### 1.2.2 训练/测试
+
+ 示例以df2k数据集和RealSR模型为例。如果您想使用自己的数据集,可以在配置文件中修改数据集为您自己的数据集。如果您想使用其他模型,可以通过替换配置文件。
+
+ 训练模型:
+ ```
+ python -u tools/main.py --config-file configs/realsr_bicubic_noise_x4_df2k.yaml
+ ```
+
+ 测试模型:
+ ```
+ python tools/main.py --config-file configs/realsr_bicubic_noise_x4_df2k.yaml --evaluate-only --load ${PATH_OF_WEIGHT}
+ ```
+
+## 1.3 实验结果展示
+实验数值结果是在 RGB 通道上进行评估,并在评估之前裁剪每个边界的尺度像素。
+
+度量指标为 PSNR / SSIM.
+
+| 模型 | Set5 | Set14 | DIV2K |
+|---|---|---|---|
+| realsr_df2k | 28.4385 / 0.8106 | 24.7424 / 0.6678 | 26.7306 / 0.7512 |
+| realsr_dped | 20.2421 / 0.6158 | 19.3775 / 0.5259 | 20.5976 / 0.6051 |
+| realsr_merge | 24.8315 / 0.7030 | 23.0393 / 0.5986 | 24.8510 / 0.6856 |
+| lesrcnn_x4 | 31.9476 / 0.8909 | 28.4110 / 0.7770 | 30.231 / 0.8326 |
+| esrgan_psnr_x4 | 32.5512 / 0.8991 | 28.8114 / 0.7871 | 30.7565 / 0.8449 |
+| esrgan_x4 | 28.7647 / 0.8187 | 25.0065 / 0.6762 | 26.9013 / 0.7542 |
+| pan_x4 | 30.4574 / 0.8643 | 26.7204 / 0.7434 | 28.9187 / 0.8176 |
+| drns_x4 | 32.6684 / 0.8999 | 28.9037 / 0.7885 | - |
+
+PAN指标对比
+
+paddle模型使用DIV2K数据集训练,torch模型使用df2k和DIV2K数据集训练。
+
+| 框架 | Set5 | Set14 |
+|---|---|---|
+| paddle | 30.4574 / 0.8643 | 26.7204 / 0.7434 |
+| torch | 30.2183 / 0.8643 | 26.8035 / 0.7445 |
+
+
+
+
+## 1.4 模型下载
+| 模型 | 数据集 | 下载地址 |
+|---|---|---|
+| realsr_df2k | df2k | [realsr_df2k](https://paddlegan.bj.bcebos.com/models/realsr_df2k.pdparams)
+| realsr_dped | dped | [realsr_dped](https://paddlegan.bj.bcebos.com/models/realsr_dped.pdparams)
+| realsr_merge | DIV2K | [realsr_merge](https://paddlegan.bj.bcebos.com/models/realsr_merge.pdparams)
+| lesrcnn_x4 | DIV2K | [lesrcnn_x4](https://paddlegan.bj.bcebos.com/models/lesrcnn_x4.pdparams)
+| esrgan_psnr_x4 | DIV2K | [esrgan_psnr_x4](https://paddlegan.bj.bcebos.com/models/esrgan_psnr_x4.pdparams)
+| esrgan_x4 | DIV2K | [esrgan_x4](https://paddlegan.bj.bcebos.com/models/esrgan_x4.pdparams)
+| pan_x4 | DIV2K | [pan_x4](https://paddlegan.bj.bcebos.com/models/pan_x4.pdparams)
+| drns_x4 | DIV2K | [drns_x4](https://paddlegan.bj.bcebos.com/models/DRNSx4.pdparams)
+
+
+# 参考文献
+
+- 1. [Real-World Super-Resolution via Kernel Estimation and Noise Injection](https://openaccess.thecvf.com/content_CVPRW_2020/papers/w31/Ji_Real-World_Super-Resolution_via_Kernel_Estimation_and_Noise_Injection_CVPRW_2020_paper.pdf)
+
+ ```
+ @inproceedings{ji2020real,
+ title={Real-World Super-Resolution via Kernel Estimation and Noise Injection},
+ author={Ji, Xiaozhong and Cao, Yun and Tai, Ying and Wang, Chengjie and Li, Jilin and Huang, Feiyue},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops},
+ pages={466--467},
+ year={2020}
+ }
+ ```
+
+- 2. [ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks](https://arxiv.org/abs/1809.00219v2)
+
+ ```
+ @inproceedings{wang2018esrgan,
+ title={Esrgan: Enhanced super-resolution generative adversarial networks},
+ author={Wang, Xintao and Yu, Ke and Wu, Shixiang and Gu, Jinjin and Liu, Yihao and Dong, Chao and Qiao, Yu and Change Loy, Chen},
+ booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
+ pages={0--0},
+ year={2018}
+ }
+ ```
+
+- 3. [Lightweight image super-resolution with enhanced CNN](https://arxiv.org/abs/2007.04344)
+
+ ```
+ @article{tian2020lightweight,
+ title={Lightweight image super-resolution with enhanced CNN},
+ author={Tian, Chunwei and Zhuge, Ruibin and Wu, Zhihao and Xu, Yong and Zuo, Wangmeng and Chen, Chen and Lin, Chia-Wen},
+ journal={Knowledge-Based Systems},
+ volume={205},
+ pages={106235},
+ year={2020},
+ publisher={Elsevier}
+ }
+ ```
+- 4. [Efficient Image Super-Resolution Using Pixel Attention](https://arxiv.org/pdf/2010.01073.pdf)
+
+ ```
+ @inproceedings{Hengyuan2020Efficient,
+ title={Efficient Image Super-Resolution Using Pixel Attention},
+ author={Hengyuan Zhao and Xiangtao Kong and Jingwen He and Yu Qiao and Chao Dong},
+ booktitle={Computer Vision – ECCV 2020 Workshops},
+ volume={12537},
+ pages={56-72},
+ year={2020}
+ }
+ ```
+ - 5. [Closed-loop Matters: Dual Regression Networks for Single Image Super-Resolution](https://arxiv.org/pdf/2003.07018.pdf)
+
+ ```
+ @inproceedings{guo2020closed,
+ title={Closed-loop Matters: Dual Regression Networks for Single Image Super-Resolution},
+ author={Guo, Yong and Chen, Jian and Wang, Jingdong and Chen, Qi and Cao, Jiezhang and Deng, Zeshuai and Xu, Yanwu and Tan, Mingkui},
+ booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
+ year={2020}
+ }
+ ```
diff --git a/docs/zh_CN/tutorials/starganv2.md b/docs/zh_CN/tutorials/starganv2.md
new file mode 100644
index 0000000000000000000000000000000000000000..7960fb92fd8903ba4111f03a125cd854c5d8e26e
--- /dev/null
+++ b/docs/zh_CN/tutorials/starganv2.md
@@ -0,0 +1,74 @@
+# StarGAN V2
+
+## 1 原理介绍
+
+ [StarGAN V2](https://arxiv.org/pdf/1912.01865.pdf)是发布在CVPR2020上的一个图像转换模型。
+ 一个好的图像到图像转换模型应该学习不同视觉域之间的映射,同时满足以下属性:1)生成图像的多样性和 2)多个域的可扩展性。 现有方法只解决了其中一个问题,领域的多样性有限或对所有领域用多个模型。 StarGAN V2是一个单一的框架,可以同时解决这两个问题,并在基线上显示出显着改善的结果。 CelebAHQ 和新的动物面孔数据集 (AFHQ) 上的实验验证了StarGAN V2在视觉质量、多样性和可扩展性方面的优势。
+
+## 2 如何使用
+
+### 2.1 数据准备
+
+ StarGAN V2使用的CelebAHQ数据集可以从[这里](https://www.dropbox.com/s/f7pvjij2xlpff59/celeba_hq.zip?dl=0)下载,使用的AFHQ数据集可以从[这里](https://www.dropbox.com/s/t9l9o3vsx2jai3z/afhq.zip?dl=0)下载。将数据集下载解压后放到``PaddleGAN/data``文件夹下 。
+
+ 数据的组成形式为:
+
+ ```
+ ├── data
+ ├── afhq
+ | ├── train
+ | | ├── cat
+ | | ├── dog
+ | | └── wild
+ | └── val
+ | ├── cat
+ | ├── dog
+ | └── wild
+ └── celeba_hq
+ ├── train
+ | ├── female
+ | └── male
+ └── val
+ ├── female
+ └── male
+
+ ```
+
+### 2.2 训练/测试
+
+ 示例以AFHQ数据集为例。如果您想使用CelebAHQ数据集,可以在换一下配置文件。
+
+ 训练模型:
+ ```
+ python -u tools/main.py --config-file configs/starganv2_afhq.yaml
+ ```
+
+ 测试模型:
+ ```
+ python tools/main.py --config-file configs/starganv2_afhq.yaml --evaluate-only --load ${PATH_OF_WEIGHT}
+ ```
+
+## 3 结果展示
+
+
+
+## 4 模型下载
+| 模型 | 数据集 | 下载地址 |
+|---|---|---|
+| starganv2_afhq | AFHQ | [starganv2_afhq](https://paddlegan.bj.bcebos.com/models/starganv2_afhq.pdparams)
+
+
+
+
+# 参考文献
+
+- 1. [StarGAN v2: Diverse Image Synthesis for Multiple Domains](https://arxiv.org/abs/1912.01865)
+
+ ```
+ @inproceedings{choi2020starganv2,
+ title={StarGAN v2: Diverse Image Synthesis for Multiple Domains},
+ author={Yunjey Choi and Youngjung Uh and Jaejun Yoo and Jung-Woo Ha},
+ booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
+ year={2020}
+ }
+ ```
diff --git a/docs/zh_CN/tutorials/styleganv2.md b/docs/zh_CN/tutorials/styleganv2.md
index 7ebab5e1ff14af2fdca8769515b40736491a6029..7140bc5240953e9e838b1586def9d14b75ff4719 100644
--- a/docs/zh_CN/tutorials/styleganv2.md
+++ b/docs/zh_CN/tutorials/styleganv2.md
@@ -54,9 +54,56 @@ python -u tools/styleganv2.py \
- n_col: 采样的图片的列数
- cpu: 是否使用cpu推理,若不使用,请在命令中去除
-### 训练(TODO)
+### 训练
+
+#### 准备数据集
+你可以从[这里](https://drive.google.com/drive/folders/1u2xu7bSrWxrbUxk-dT-UvEJq8IjdmNTP)下载对应的数据集
+
+为了方便,我们提供了[images256x256.tar](https://paddlegan.bj.bcebos.com/datasets/images256x256.tar)
+
+目前的配置文件默认数据集的结构如下:
+ ```
+ PaddleGAN
+ ├── data
+ ├── ffhq
+ ├──images1024x1024
+ ├── 00000.png
+ ├── 00001.png
+ ├── 00002.png
+ ├── 00003.png
+ ├── 00004.png
+ ├──images256x256
+ ├── 00000.png
+ ├── 00001.png
+ ├── 00002.png
+ ├── 00003.png
+ ├── 00004.png
+ ├──custom_data
+ ├── img0.png
+ ├── img1.png
+ ├── img2.png
+ ├── img3.png
+ ├── img4.png
+ ...
+ ```
+
+启动训练
+```
+python tools/main.py -c configs/stylegan_v2_256_ffhq.yaml
+```
+
+### 推理
+
+训练结束后,需要使用 ``tools/extract_weight.py`` 来提取对应的权重给``applications/tools/styleganv2.py``来进行推理.
+```
+python tools/extract_weight.py output_dir/YOUR_TRAINED_WEIGHT.pdparams --net-name gen_ema --output YOUR_WEIGHT_PATH.pdparams
+```
+
+```
+python tools/styleganv2.py --output_path stylegan01 --weight_path YOUR_WEIGHT_PATH.pdparams --size 256
+```
-未来还将添加训练脚本方便用户训练出更多类型的 StyleGAN V2 图像生成器。
+注意: ``--size`` 这个参数要和配置文件中的参数保持一致.
## 生成结果展示
diff --git a/docs/zh_CN/tutorials/styleganv2clip.md b/docs/zh_CN/tutorials/styleganv2clip.md
new file mode 100644
index 0000000000000000000000000000000000000000..733b90ea06d0057aa7dac44fad227c72b07a60a1
--- /dev/null
+++ b/docs/zh_CN/tutorials/styleganv2clip.md
@@ -0,0 +1,167 @@
+# StyleCLIP: 文本驱动的图像处理
+## 1. 简介
+
+StyleGAN V2 的任务是使用风格向量进行image generation,而Clip guided Editing 则是利用CLIP (Contrastive Language-Image Pre-training ) 多模态预训练模型计算文本输入对应的风格向量变化,用文字表述来对图像进行编辑操纵风格向量进而操纵生成图像的属性。相比于Editing 模块,StyleCLIP不受预先统计的标注属性限制,可以通过语言描述自由控制图像编辑。
+
+原论文中使用 Pixel2Style2Pixel 的 升级模型 Encode4Editing 计算要编辑的代表图像的风格向量,为尽量利用PaddleGAN提供的预训练模型本次复现中仍使用Pixel2Style2Pixel计算得到风格向量进行实验,重构效果略有下降,期待PaddleGAN跟进e4e相关工作。
+
+
+## 2. 复现
+
+StyleCLIP 模型 需要使用简介中对应提到的几个预训练模型,
+本次复现使用PPGAN 提供的 在FFHQ数据集上进行预训练的StyleGAN V2 模型作为生成器,并使用Pixel2Style2Pixel模型将待编辑图像转换为对应风格向量。
+
+CLIP模型依赖Paddle-CLIP实现。
+pSp模型包含人脸检测步骤,依赖dlib框架。
+除本repo外还需要安装 Paddle-CLIP 和 dlib 依赖。
+
+整体安装方法如下。
+```
+pip install -e .
+pip install paddleclip
+pip install dlib-bin
+```
+
+### 编辑结果展示
+
+风格向量对应的图像:
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+

+
+

+
+
+
训练预测 | 更多
训练方式 | 模型压缩 | 其他预测部署 |
+| :--- | :--- | :----: | :--------: | :---- | :---- | :---- |
+| Pix2Pix |Pix2Pix | 生成 | 支持 | 多机多卡 | | |
+| CycleGAN |CycleGAN | 生成 | 支持 | 多机多卡 | | |
+| StyleGAN2 |StyleGAN2 | 生成 | 支持 | 多机多卡 | | |
+| FOMM |FOMM | 生成 | 支持 | 多机多卡 | | |
+| BasicVSR |BasicVSR | 超分 | 支持 | 多机多卡 | | |
+|PP-MSVSR|PP-MSVSR | 超分|
+|SinGAN|SinGAN | 生成| 支持 |
+
+
+
+
+## 3. 一键测试工具使用
+### 目录介绍
+
+```shell
+test_tipc/
+├── configs/ # 配置文件目录
+ ├── basicvsr_reds.yaml # 测试basicvsr模型训练的yaml文件
+ ├── cyclegan_horse2zebra.yaml # 测试cyclegan模型训练的yaml文件
+ ├── firstorder_vox_256.yaml # 测试fomm模型训练的yaml文件
+ ├── pix2pix_facedes.yaml # 测试pix2pix模型训练的yaml文件
+ ├── stylegan_v2_256_ffhq.yaml # 测试stylegan模型训练的yaml文件
+
+ ├── ...
+├── results/ # 预先保存的预测结果,用于和实际预测结果进行精读比对
+ ├── python_basicvsr_results_fp32.txt # 预存的basicvsr模型python预测fp32精度的结果
+ ├── python_cyclegan_results_fp32.txt # 预存的cyclegan模型python预测fp32精度的结果
+ ├── python_pix2pix_results_fp32.txt # 预存的pix2pix模型python预测的fp32精度的结果
+ ├── python_stylegan2_results_fp32.txt # 预存的stylegan2模型python预测的fp32精度的结果
+ ├── ...
+├── prepare.sh # 完成test_*.sh运行所需要的数据和模型下载
+├── test_train_inference_python.sh # 测试python训练预测的主程序
+├── compare_results.py # 用于对比log中的预测结果与results中的预存结果精度误差是否在限定范围内
+└── readme.md # 使用文档
+```
+
+### 测试流程
+使用本工具,可以测试不同功能的支持情况,以及预测结果是否对齐,测试流程如下:
+
+
+
+1. 运行prepare.sh准备测试所需数据和模型;
+2. 运行要测试的功能对应的测试脚本`test_*.sh`,产出log,由log可以看到不同配置是否运行成功;
+3. 用`compare_results.py`对比log中的预测结果和预存在results目录下的结果,判断预测精度是否符合预期(在误差范围内)。
+
+其中,有4个测试主程序,功能如下:
+- `test_train_inference_python.sh`:测试基于Python的模型训练、评估、推理等基本功能。
+
+
+
+#### 更多教程
+各功能测试中涉及混合精度、裁剪、量化等训练相关,及mkldnn、Tensorrt等多种预测相关参数配置,请点击下方相应链接了解更多细节和使用教程:
+- [test_train_inference_python 使用](docs/test_train_inference_python.md) 测试基于Python的模型训练、推理等基本功能。
+- [test_inference_cpp 使用](docs/test_inference_cpp.md) 测试基于C++的模型推理功能。
diff --git a/test_tipc/benchmark_train.sh b/test_tipc/benchmark_train.sh
new file mode 100644
index 0000000000000000000000000000000000000000..d5e225d1238d6775d95ec3c6df4eceaddbb62d27
--- /dev/null
+++ b/test_tipc/benchmark_train.sh
@@ -0,0 +1,256 @@
+#!/bin/bash
+source test_tipc/common_func.sh
+
+# set env
+python=python
+export model_branch=`git symbolic-ref HEAD 2>/dev/null | cut -d"/" -f 3`
+export model_commit=$(git log|head -n1|awk '{print $2}')
+export str_tmp=$(echo `pip list|grep paddlepaddle-gpu|awk -F ' ' '{print $2}'`)
+export frame_version=${str_tmp%%.post*}
+export frame_commit=$(echo `${python} -c "import paddle;print(paddle.version.commit)"`)
+
+# run benchmark sh
+# Usage:
+# bash run_benchmark_train.sh config.txt params
+# or
+# bash run_benchmark_train.sh config.txt
+
+function func_parser_params(){
+ strs=$1
+ IFS="="
+ array=(${strs})
+ tmp=${array[1]}
+ echo ${tmp}
+}
+
+function func_sed_params(){
+ filename=$1
+ line=$2
+ param_value=$3
+ params=`sed -n "${line}p" $filename`
+ IFS=":"
+ array=(${params})
+ key=${array[0]}
+ value=${array[1]}
+ new_params="${key}:${param_value}"
+ IFS=";"
+ cmd="sed -i '${line}s/.*/${new_params}/' '${filename}'"
+ eval $cmd
+}
+
+function set_gpu_id(){
+ string=$1
+ _str=${string:1:6}
+ IFS="C"
+ arr=(${_str})
+ M=${arr[0]}
+ P=${arr[1]}
+ gn=`expr $P - 1`
+ gpu_num=`expr $gn / $M`
+ seq=`seq -s "," 0 $gpu_num`
+ echo $seq
+}
+
+function get_repo_name(){
+ IFS=";"
+ cur_dir=$(pwd)
+ IFS="/"
+ arr=(${cur_dir})
+ echo ${arr[-1]}
+}
+
+FILENAME=$1
+# copy FILENAME as new
+new_filename="./test_tipc/benchmark_train.txt"
+cmd=`yes|cp $FILENAME $new_filename`
+FILENAME=$new_filename
+# MODE must be one of ['benchmark_train']
+MODE=$2
+PARAMS=$3
+
+IFS=$'\n'
+# parser params from train_benchmark.txt
+dataline=`cat $FILENAME`
+# parser params
+IFS=$'\n'
+lines=(${dataline})
+model_name=$(func_parser_value "${lines[1]}")
+
+# 获取benchmark_params所在的行数
+line_num=`grep -n "train_benchmark_params" $FILENAME | cut -d ":" -f 1`
+# for train log parser
+batch_size=$(func_parser_value "${lines[line_num]}")
+line_num=`expr $line_num + 1`
+fp_items=$(func_parser_value "${lines[line_num]}")
+line_num=`expr $line_num + 1`
+epoch=$(func_parser_value "${lines[line_num]}")
+
+line_num=`expr $line_num + 1`
+profile_option_key=$(func_parser_key "${lines[line_num]}")
+profile_option_params=$(func_parser_value "${lines[line_num]}")
+profile_option="${profile_option_key}:${profile_option_params}"
+
+line_num=`expr $line_num + 1`
+flags_value=$(func_parser_value "${lines[line_num]}")
+# set flags
+IFS=";"
+flags_list=(${flags_value})
+for _flag in ${flags_list[*]}; do
+ cmd="export ${_flag}"
+ eval $cmd
+done
+
+# set log_name
+repo_name=$(get_repo_name )
+SAVE_LOG=${BENCHMARK_LOG_DIR:-$(pwd)} # */benchmark_log
+mkdir -p "${SAVE_LOG}/benchmark_log/"
+status_log="${SAVE_LOG}/benchmark_log/results.log"
+
+# The number of lines in which train params can be replaced.
+line_python=3
+line_gpuid=4
+line_precision=6
+line_epoch=7
+line_batchsize=9
+line_profile=13
+line_eval_py=24
+line_export_py=30
+
+func_sed_params "$FILENAME" "${line_eval_py}" "null"
+func_sed_params "$FILENAME" "${line_export_py}" "null"
+func_sed_params "$FILENAME" "${line_python}" "$python"
+
+# if params
+if [ ! -n "$PARAMS" ] ;then
+ # PARAMS input is not a word.
+ IFS="|"
+ batch_size_list=(${batch_size})
+ fp_items_list=(${fp_items})
+ device_num_list=(N1C4)
+ run_mode="DP"
+else
+ # parser params from input: modeltype_bs${bs_item}_${fp_item}_${run_mode}_${device_num}
+ IFS="_"
+ params_list=(${PARAMS})
+ model_type=${params_list[0]}
+ batch_size=${params_list[1]}
+ batch_size=`echo ${batch_size} | tr -cd "[0-9]" `
+ precision=${params_list[2]}
+ run_mode=${params_list[3]}
+ device_num=${params_list[4]}
+ IFS=";"
+
+ if [ ${precision} = "null" ];then
+ precision="fp32"
+ fi
+
+ fp_items_list=($precision)
+ batch_size_list=($batch_size)
+ device_num_list=($device_num)
+fi
+
+# for log name
+to_static=""
+# parse "to_static" options and modify trainer into "to_static_trainer"
+if [[ ${model_type} = "dynamicTostatic" ]];then
+ to_static="d2sT_"
+ sed -i 's/trainer:norm_train/trainer:to_static_train/g' $FILENAME
+fi
+
+IFS="|"
+for batch_size in ${batch_size_list[*]}; do
+ for precision in ${fp_items_list[*]}; do
+ for device_num in ${device_num_list[*]}; do
+ # sed batchsize and precision
+ func_sed_params "$FILENAME" "${line_precision}" "$precision"
+ func_sed_params "$FILENAME" "${line_batchsize}" "$MODE=$batch_size"
+ func_sed_params "$FILENAME" "${line_epoch}" "$MODE=$epoch"
+ gpu_id=$(set_gpu_id $device_num)
+
+ if [ ${#gpu_id} -le 1 ];then
+ log_path="$SAVE_LOG/profiling_log"
+ mkdir -p $log_path
+ log_name="${repo_name}_${model_name}_bs${batch_size}_${precision}_${run_mode}_${device_num}_${to_static}profiling"
+ func_sed_params "$FILENAME" "${line_gpuid}" "0" # sed used gpu_id
+ # set profile_option params
+ tmp=`sed -i "${line_profile}s/.*/${profile_option}/" "${FILENAME}"`
+
+ # run test_train_inference_python.sh
+ cmd="bash test_tipc/test_train_inference_python.sh ${FILENAME} benchmark_train > ${log_path}/${log_name} 2>&1 "
+ echo $cmd
+ eval $cmd
+ eval "cat ${log_path}/${log_name}"
+
+ # without profile
+ log_path="$SAVE_LOG/train_log"
+ speed_log_path="$SAVE_LOG/index"
+ mkdir -p $log_path
+ mkdir -p $speed_log_path
+ log_name="${repo_name}_${model_name}_bs${batch_size}_${precision}_${run_mode}_${device_num}_${to_static}log"
+ speed_log_name="${repo_name}_${model_name}_bs${batch_size}_${precision}_${run_mode}_${device_num}_${to_static}speed"
+ func_sed_params "$FILENAME" "${line_profile}" "null" # sed profile_id as null
+ cmd="bash test_tipc/test_train_inference_python.sh ${FILENAME} benchmark_train > ${log_path}/${log_name} 2>&1 "
+ echo $cmd
+ job_bt=`date '+%Y%m%d%H%M%S'`
+ eval $cmd
+ job_et=`date '+%Y%m%d%H%M%S'`
+ export model_run_time=$((${job_et}-${job_bt}))
+ eval "cat ${log_path}/${log_name}"
+
+ # parser log
+ _model_name="${model_name}_bs${batch_size}_${precision}_${run_mode}"
+ cmd="${python} ${BENCHMARK_ROOT}/scripts/analysis.py --filename ${log_path}/${log_name} \
+ --speed_log_file '${speed_log_path}/${speed_log_name}' \
+ --model_name ${_model_name} \
+ --base_batch_size ${batch_size} \
+ --run_mode ${run_mode} \
+ --fp_item ${precision} \
+ --keyword ips: \
+ --skip_steps 2 \
+ --device_num ${device_num} \
+ --speed_unit samples/s \
+ --convergence_key loss: "
+ echo $cmd
+ eval $cmd
+ last_status=${PIPESTATUS[0]}
+ status_check $last_status "${cmd}" "${status_log}"
+ else
+ IFS=";"
+ unset_env=`unset CUDA_VISIBLE_DEVICES`
+ log_path="$SAVE_LOG/train_log"
+ speed_log_path="$SAVE_LOG/index"
+ mkdir -p $log_path
+ mkdir -p $speed_log_path
+ log_name="${repo_name}_${model_name}_bs${batch_size}_${precision}_${run_mode}_${device_num}_${to_static}log"
+ speed_log_name="${repo_name}_${model_name}_bs${batch_size}_${precision}_${run_mode}_${device_num}_${to_static}speed"
+ func_sed_params "$FILENAME" "${line_gpuid}" "$gpu_id" # sed used gpu_id
+ func_sed_params "$FILENAME" "${line_profile}" "null" # sed --profile_option as null
+ cmd="bash test_tipc/test_train_inference_python.sh ${FILENAME} benchmark_train > ${log_path}/${log_name} 2>&1 "
+ echo $cmd
+ job_bt=`date '+%Y%m%d%H%M%S'`
+ eval $cmd
+ job_et=`date '+%Y%m%d%H%M%S'`
+ export model_run_time=$((${job_et}-${job_bt}))
+ eval "cat ${log_path}/${log_name}"
+ # parser log
+ _model_name="${model_name}_bs${batch_size}_${precision}_${run_mode}"
+
+ cmd="${python} ${BENCHMARK_ROOT}/scripts/analysis.py --filename ${log_path}/${log_name} \
+ --speed_log_file '${speed_log_path}/${speed_log_name}' \
+ --model_name ${_model_name} \
+ --base_batch_size ${batch_size} \
+ --run_mode ${run_mode} \
+ --fp_item ${precision} \
+ --keyword ips: \
+ --skip_steps 2 \
+ --device_num ${device_num} \
+ --speed_unit images/s \
+ --convergence_key loss: "
+ echo $cmd
+ eval $cmd
+ last_status=${PIPESTATUS[0]}
+ status_check $last_status "${cmd}" "${status_log}"
+ fi
+ done
+ done
+done
diff --git a/test_tipc/common_func.sh b/test_tipc/common_func.sh
new file mode 100644
index 0000000000000000000000000000000000000000..7e349f0e2ff079f715a3ad1211fd6cd7432c0283
--- /dev/null
+++ b/test_tipc/common_func.sh
@@ -0,0 +1,66 @@
+#!/bin/bash
+
+function func_parser_key(){
+ strs=$1
+ IFS=":"
+ array=(${strs})
+ tmp=${array[0]}
+ echo ${tmp}
+}
+
+function func_parser_value(){
+ strs=$1
+ IFS=":"
+ array=(${strs})
+ tmp=${array[1]}
+ echo ${tmp}
+}
+
+function func_set_params(){
+ key=$1
+ value=$2
+ if [ ${key}x = "null"x ];then
+ echo " "
+ elif [[ ${value} = "null" ]] || [[ ${value} = " " ]] || [ ${#value} -le 0 ];then
+ echo " "
+ else
+ echo "${key}=${value}"
+ fi
+}
+
+function func_parser_params(){
+ strs=$1
+ IFS=":"
+ array=(${strs})
+ key=${array[0]}
+ tmp=${array[1]}
+ IFS="|"
+ res=""
+ for _params in ${tmp[*]}; do
+ IFS="="
+ array=(${_params})
+ mode=${array[0]}
+ value=${array[1]}
+ if [[ ${mode} = ${MODE} ]]; then
+ IFS="|"
+ #echo $(func_set_params "${mode}" "${value}")
+ echo $value
+ break
+ fi
+ IFS="|"
+ done
+ echo ${res}
+}
+
+function status_check(){
+ last_status=$1 # the exit code
+ run_command=$2
+ run_log=$3
+ model_name=$4
+ log_path=$5
+ if [ $last_status -eq 0 ]; then
+ echo -e "\033[33m Run successfully with command - ${model_name} - ${run_command} - ${log_path} \033[0m" | tee -a ${run_log}
+ else
+ echo -e "\033[33m Run failed with command - ${model_name} - ${run_command} - ${log_path} \033[0m" | tee -a ${run_log}
+ fi
+}
diff --git a/test_tipc/compare_results.py b/test_tipc/compare_results.py
new file mode 100644
index 0000000000000000000000000000000000000000..1d19197e89bccdb6b0beaf84bc2b83cc22ef5c48
--- /dev/null
+++ b/test_tipc/compare_results.py
@@ -0,0 +1,55 @@
+import numpy as np
+import os
+import subprocess
+import json
+import argparse
+import glob
+
+
+def init_args():
+ parser = argparse.ArgumentParser()
+ # params for testing assert allclose
+ parser.add_argument("--atol", type=float, default=1e-3)
+ parser.add_argument("--rtol", type=float, default=1e-3)
+ parser.add_argument("--gt_file", type=str, default="")
+ parser.add_argument("--log_file", type=str, default="")
+ parser.add_argument("--precision", type=str, default="fp32")
+ return parser
+
+def parse_args():
+ parser = init_args()
+ return parser.parse_args()
+
+def load_from_file(gt_file):
+ if not os.path.exists(gt_file):
+ raise ValueError("The log file {} does not exists!".format(gt_file))
+ with open(gt_file, 'r') as f:
+ data = f.readlines()
+ f.close()
+ parser_gt = {}
+ for line in data:
+ metric_name, result = line.strip("\n").split(":")
+ parser_gt[metric_name] = float(result)
+ return parser_gt
+
+if __name__ == "__main__":
+ # Usage:
+ # python3.7 test_tipc/compare_results.py --gt_file=./test_tipc/results/*.txt --log_file=./test_tipc/output/*/*.txt
+
+ args = parse_args()
+
+ gt_collection = load_from_file(args.gt_file)
+ pre_collection = load_from_file(args.log_file)
+
+ for metric in pre_collection.keys():
+ try:
+ np.testing.assert_allclose(
+ np.array(pre_collection[metric]), np.array(gt_collection[metric]), atol=args.atol, rtol=args.rtol)
+ print(
+ "Assert allclose passed! The results of {} are consistent!".
+ format(metric))
+ except Exception as E:
+ print(E)
+ raise ValueError(
+ "The results of {} are inconsistent!".
+ format(metric))
\ No newline at end of file
diff --git a/test_tipc/configs/CycleGAN/train_infer_python.txt b/test_tipc/configs/CycleGAN/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..cd27a2218cd1c4b2e577e6b4f33f6df2b99264d9
--- /dev/null
+++ b/test_tipc/configs/CycleGAN/train_infer_python.txt
@@ -0,0 +1,59 @@
+===========================train_params===========================
+model_name:CycleGAN
+python:python3.7
+gpu_list:0|0,1
+##
+auto_cast:null
+epochs:lite_train_lite_infer=1|lite_train_whole_infer=1|whole_train_whole_infer=200
+output_dir:./output/
+dataset.train.batch_size:lite_train_lite_infer=1|whole_train_whole_infer=1
+pretrained_model:null
+train_model_name:cyclegan_horse2zebra*/*checkpoint.pdparams
+train_infer_img_dir:./data/horse2zebra/test
+null:null
+##
+trainer:norm_train
+norm_train:tools/main.py -c configs/cyclegan_horse2zebra.yaml --seed 123 -o log_config.interval=1 snapshot_config.interval=1
+pact_train:null
+fpgm_train:null
+distill_train:null
+to_static_train:model.to_static=True
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+--output_dir:./output/
+load:null
+norm_export:tools/export_model.py -c configs/cyclegan_horse2zebra.yaml --inputs_size="-1,3,-1,-1;-1,3,-1,-1" --model_name inference --load
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+inference_dir:inference
+train_model:./inference/cyclegan_horse2zebra/cycleganmodel_netG_A
+infer_export:null
+infer_quant:False
+inference:tools/inference.py --model_type cyclegan --seed 123 -c configs/cyclegan_horse2zebra.yaml --output_path test_tipc/output/
+--device:gpu
+null:null
+null:null
+null:null
+null:null
+null:null
+--model_path:
+null:null
+null:null
+--benchmark:True
+null:null
+===========================train_benchmark_params==========================
+batch_size:1
+fp_items:fp32
+epoch:1
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,256,256]}]
\ No newline at end of file
diff --git a/test_tipc/configs/FOMM/train_infer_python.txt b/test_tipc/configs/FOMM/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..50b522f249102eeb668deedc364171279004b88d
--- /dev/null
+++ b/test_tipc/configs/FOMM/train_infer_python.txt
@@ -0,0 +1,59 @@
+===========================train_params===========================
+model_name:FOMM
+python:python3.7
+gpu_list:0
+##
+auto_cast:null
+epochs:lite_train_lite_infer=1|lite_train_whole_infer=1|whole_train_whole_infer=100
+output_dir:./output/
+dataset.train.batch_size:lite_train_lite_infer=8|whole_train_whole_infer=8
+pretrained_model:null
+train_model_name:firstorder_vox_256*/*checkpoint.pdparams
+train_infer_img_dir:./data/firstorder_vox_256/test
+null:null
+##
+trainer:norm_train
+norm_train:tools/main.py -c configs/firstorder_vox_256.yaml --seed 123 -o log_config.interval=1 snapshot_config.interval=1 dataset.train.num_repeats=1 dataset.train.id_sampling=False
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+--output_dir:./output/
+load:null
+norm_export:tools/export_model.py -c configs/firstorder_vox_256.yaml --inputs_size="1,3,256,256;1,3,256,256;1,10,2;1,10,2,2" --load
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+inference_dir:fom_dy2st
+train_model:./inference/fom_dy2st/
+infer_export:null
+infer_quant:False
+inference:tools/fom_infer.py --driving_path data/first_order/Voxceleb/test --output_path test_tipc/output/fom/
+--device:gpu
+null:null
+null:null
+null:null
+null:null
+null:null
+--model_path:
+null:null
+null:null
+--benchmark:True
+null:null
+===========================train_benchmark_params==========================
+batch_size:16
+fp_items:fp32
+epoch:15
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:FLAGS_cudnn_exhaustive_search=1
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,256,256]}]
diff --git a/test_tipc/configs/GFPGAN/train_infer_python.txt b/test_tipc/configs/GFPGAN/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..e38a7eac883ed608afc613730a03090f4ee7fe1f
--- /dev/null
+++ b/test_tipc/configs/GFPGAN/train_infer_python.txt
@@ -0,0 +1,51 @@
+===========================train_params===========================
+model_name:GFPGAN
+python:python3.7
+gpu_list:0
+##
+auto_cast:null
+total_iters:lite_train_lite_infer=10
+output_dir:./output/
+dataset.train.batch_size:lite_train_lite_infer=3
+pretrained_model:null
+train_model_name:gfpgan_ffhq1024*/*checkpoint.pdparams
+train_infer_img_dir:null
+null:null
+##
+trainer:norm_train
+norm_train:tools/main.py -c configs/gfpgan_ffhq1024.yaml --seed 123 -o log_config.interval=1 snapshot_config.interval=10
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+--output_dir:./output/
+load:null
+norm_export:tools/export_model.py -c configs/gfpgan_ffhq1024.yaml --inputs_size="1,3,512,512" --model_name inference --load
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+inference_dir:inference
+train_model:./inference/stylegan2/stylegan2model_gen
+infer_export:null
+infer_quant:False
+inference:tools/inference.py --model_type gfpgan --seed 123 -c configs/gfpgan_ffhq1024.yaml --output_path test_tipc/output/ -o validate=None
+--device:gpu
+null:null
+null:null
+null:null
+null:null
+null:null
+--model_path:
+null:null
+null:null
+--benchmark:False
+null:null
diff --git a/test_tipc/configs/Pix2pix/train_infer_python.txt b/test_tipc/configs/Pix2pix/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..e1aed5ebb886a926b60a1635c6e3df758200708d
--- /dev/null
+++ b/test_tipc/configs/Pix2pix/train_infer_python.txt
@@ -0,0 +1,59 @@
+===========================train_params===========================
+model_name:Pix2pix
+python:python3.7
+gpu_list:0
+##
+auto_cast:null
+epochs:lite_train_lite_infer=10|lite_train_whole_infer=10|whole_train_whole_infer=200
+output_dir:./output/
+dataset.train.batch_size:lite_train_lite_infer=1|whole_train_whole_infer=1
+pretrained_model:null
+train_model_name:pix2pix_facades*/*checkpoint.pdparams
+train_infer_img_dir:./data/facades/test
+null:null
+##
+trainer:norm_train
+norm_train:tools/main.py -c configs/pix2pix_facades.yaml --seed 123 -o log_config.interval=1
+pact_train:null
+fpgm_train:null
+distill_train:null
+to_static_train:model.to_static=True
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+--output_dir:./output/
+load:null
+norm_export:tools/export_model.py -c configs/pix2pix_facades.yaml --inputs_size="-1,3,-1,-1" --model_name inference --load
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+inference_dir:inference
+train_model:./inference/pix2pix_facade/pix2pixmodel_netG
+infer_export:null
+infer_quant:False
+inference:tools/inference.py --model_type pix2pix --seed 123 -c configs/pix2pix_facades.yaml --output_path test_tipc/output/
+--device:cpu
+null:null
+null:null
+null:null
+null:null
+null:null
+--model_path:
+null:null
+null:null
+--benchmark:True
+null:null
+===========================train_benchmark_params==========================
+batch_size:1
+fp_items:fp32
+epoch:10
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,256,256]}]
diff --git a/test_tipc/configs/StyleGANv2/train_infer_python.txt b/test_tipc/configs/StyleGANv2/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..182214ecdb9ae42da47fdc4898f1f96984df736a
--- /dev/null
+++ b/test_tipc/configs/StyleGANv2/train_infer_python.txt
@@ -0,0 +1,59 @@
+===========================train_params===========================
+model_name:StyleGANv2
+python:python3.7
+gpu_list:0
+##
+auto_cast:null
+total_iters:lite_train_lite_infer=10|lite_train_whole_infer=10|whole_train_whole_infer=800
+output_dir:./output/
+dataset.train.batch_size:lite_train_lite_infer=3|whole_train_whole_infer=3
+pretrained_model:null
+train_model_name:stylegan_v2_256_ffhq*/*checkpoint.pdparams
+train_infer_img_dir:null
+null:null
+##
+trainer:norm_train
+norm_train:tools/main.py -c configs/stylegan_v2_256_ffhq.yaml --seed 123 -o log_config.interval=1 snapshot_config.interval=10
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+--output_dir:./output/
+load:null
+norm_export:tools/export_model.py -c configs/stylegan_v2_256_ffhq.yaml --inputs_size="1,1,512;1,1" --model_name inference --load
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+inference_dir:inference
+train_model:./inference/stylegan2/stylegan2model_gen
+infer_export:null
+infer_quant:False
+inference:tools/inference.py --model_type stylegan2 --seed 123 -c configs/stylegan_v2_256_ffhq.yaml --output_path test_tipc/output/
+--device:gpu
+null:null
+null:null
+null:null
+null:null
+null:null
+--model_path:
+null:null
+null:null
+--benchmark:True
+null:null
+===========================train_benchmark_params==========================
+batch_size:8
+fp_items:fp32
+epoch:100
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:FLAGS_cudnn_exhaustive_search=1
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[1, 512]}, {float32,[1]}]
diff --git a/test_tipc/configs/aotgan/train_infer_python.txt b/test_tipc/configs/aotgan/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..a5d82f988862ff58f4a41196609f3dc52b017fd6
--- /dev/null
+++ b/test_tipc/configs/aotgan/train_infer_python.txt
@@ -0,0 +1,51 @@
+===========================train_params===========================
+model_name:aotgan
+python:python3.7
+gpu_list:0
+##
+auto_cast:null
+epochs:lite_train_lite_infer=10|lite_train_whole_infer=10|whole_train_whole_infer=200
+output_dir:./output/
+dataset.train.batch_size:lite_train_lite_infer=1|whole_train_whole_infer=1
+pretrained_model:null
+train_model_name:aotgan*/*checkpoint.pdparams
+train_infer_img_dir:./data/aotgan
+null:null
+##
+trainer:norm_train
+norm_train:tools/main.py -c configs/aotgan.yaml --seed 123 -o log_config.interval=1 snapshot_config.interval=1
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+--output_dir:./output/
+load:null
+norm_export:tools/export_model.py -c configs/aotgan.yaml --inputs_size="-1,4,-1,-1" --model_name inference --load
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+inference_dir:inference
+train_model:./inference/aotgan/aotganmodel_netG
+infer_export:null
+infer_quant:False
+inference:tools/inference.py --model_type aotgan --seed 123 -c configs/aotgan.yaml --output_path test_tipc/output/
+--device:cpu
+null:null
+null:null
+null:null
+null:null
+null:null
+--model_path:
+null:null
+null:null
+--benchmark:True
+null:null
diff --git a/test_tipc/configs/basicvsr/train_infer_python.txt b/test_tipc/configs/basicvsr/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..484aecbad64f3ba038ad5c0d3271f132248fcf57
--- /dev/null
+++ b/test_tipc/configs/basicvsr/train_infer_python.txt
@@ -0,0 +1,59 @@
+===========================train_params===========================
+model_name:basicvsr
+python:python3.7
+gpu_list:0
+##
+auto_cast:null
+total_iters:lite_train_lite_infer=10|lite_train_whole_infer=10|whole_train_whole_infer=200
+output_dir:./output/
+dataset.train.batch_size:lite_train_lite_infer=1|whole_train_whole_infer=1
+pretrained_model:null
+train_model_name:basicvsr_reds*/*checkpoint.pdparams
+train_infer_img_dir:./data/basicvsr_reds/test
+null:null
+##
+trainer:norm_train
+norm_train:tools/main.py -c configs/basicvsr_reds.yaml --seed 123 -o log_config.interval=1 snapshot_config.interval=5
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+--output_dir:./output/
+load:null
+norm_export:tools/export_model.py -c configs/basicvsr_reds.yaml --inputs_size="1,6,3,180,320" --model_name inference --load
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+inference_dir:inference
+train_model:./inference/basicvsr/basicvsrmodel_generator
+infer_export:null
+infer_quant:False
+inference:tools/inference.py --model_type basicvsr -c configs/basicvsr_reds.yaml --seed 123 -o dataset.test.num_frames=6 --output_path test_tipc/output/
+--device:gpu
+null:null
+null:null
+null:null
+null:null
+null:null
+--model_path:
+null:null
+null:null
+--benchmark:True
+null:null
+===========================train_benchmark_params==========================
+batch_size:2|4
+fp_items:fp32
+total_iters:50
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:FLAGS_cudnn_exhaustive_search=1
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[6,3,180,320]}]
diff --git a/test_tipc/configs/edvr/train_infer_python.txt b/test_tipc/configs/edvr/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..9379f9c4e4c1cdffa0c31f1aef09b13c7971aadf
--- /dev/null
+++ b/test_tipc/configs/edvr/train_infer_python.txt
@@ -0,0 +1,57 @@
+===========================train_params===========================
+model_name:edvr
+python:python3.7
+gpu_list:0
+##
+auto_cast:null
+total_iters:lite_train_lite_infer=100
+output_dir:./output/
+dataset.train.batch_size:lite_train_lite_infer=4
+pretrained_model:null
+train_model_name:edvr_m_wo_tsa*/*checkpoint.pdparams
+train_infer_img_dir:./data/basicvsr_reds/test
+null:null
+##
+trainer:norm_train
+norm_train:tools/main.py -c configs/edvr_m_wo_tsa.yaml --seed 123 -o log_config.interval=5 snapshot_config.interval=25
+pact_train:null
+fpgm_train:null
+distill_train:null
+to_static_train:model.to_static=True
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+--output_dir:./output/
+load:null
+norm_export:tools/export_model.py -c configs/edvr_m_wo_tsa.yaml --inputs_size="1,5,3,180,320" --model_name inference --load
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+inference_dir:inference
+train_model:./inference/edvr/edvrmodel_generator
+infer_export:null
+infer_quant:False
+inference:tools/inference.py --model_type edvr -c configs/edvr_m_wo_tsa.yaml --seed 123 -o dataset.test.num_frames=5 --output_path test_tipc/output/
+--device:gpu
+null:null
+null:null
+null:null
+null:null
+null:null
+--model_path:
+null:null
+null:null
+--benchmark:True
+null:null
+===========================train_benchmark_params==========================
+batch_size:64
+fp_items:fp32|fp16
+total_iters:100
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:FLAGS_cudnn_exhaustive_search=0
diff --git a/test_tipc/configs/edvr/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/edvr/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..a9ed70507c734dfeae8b54c00c2183309da6f343
--- /dev/null
+++ b/test_tipc/configs/edvr/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,26 @@
+===========================train_params===========================
+model_name:edvr
+python:python3.7
+gpu_list:0
+##
+auto_cast:null
+total_iters:lite_train_lite_infer=100
+output_dir:./output/
+dataset.train.batch_size:lite_train_lite_infer=4
+pretrained_model:null
+train_model_name:basicvsr_reds*/*checkpoint.pdparams
+train_infer_img_dir:./data/basicvsr_reds/test
+null:null
+##
+trainer:amp_train
+amp_train:tools/main.py --amp --amp_level O2 -c configs/edvr_m_wo_tsa.yaml --seed 123 -o log_config.interval=5
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
diff --git a/test_tipc/configs/esrgan/train_infer_python.txt b/test_tipc/configs/esrgan/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..c70b93d27a3437b1bfdeb6b27dc807b82c1c4340
--- /dev/null
+++ b/test_tipc/configs/esrgan/train_infer_python.txt
@@ -0,0 +1,57 @@
+===========================train_params===========================
+model_name:esrgan
+python:python3.7
+gpu_list:0
+##
+auto_cast:null
+total_iters:lite_train_lite_infer=100
+output_dir:./output/
+dataset.train.batch_size:lite_train_lite_infer=2
+pretrained_model:null
+train_model_name:esrgan_psnr_x4_div2k*/*checkpoint.pdparams
+train_infer_img_dir:null
+null:null
+##
+trainer:norm_train
+norm_train:tools/main.py -c configs/esrgan_psnr_x4_div2k.yaml --seed 123 -o log_config.interval=10 snapshot_config.interval=25
+pact_train:null
+fpgm_train:null
+distill_train:null
+to_static_train:model.to_static=True
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+--output_dir:./output/
+load:null
+norm_export:tools/export_model.py -c configs/esrgan_psnr_x4_div2k.yaml --inputs_size="1,3,128,128" --model_name inference --load
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+inference_dir:inference
+train_model:./inference/esrgan/esrganmodel_generator
+infer_export:null
+infer_quant:False
+inference:tools/inference.py --model_type esrgan -c configs/esrgan_psnr_x4_div2k.yaml --seed 123 --output_path test_tipc/output/
+--device:gpu
+null:null
+null:null
+null:null
+null:null
+null:null
+--model_path:
+null:null
+null:null
+--benchmark:True
+null:null
+===========================train_benchmark_params==========================
+batch_size:32|64
+fp_items:fp32
+total_iters:500
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:FLAGS_cudnn_exhaustive_search=0
diff --git a/test_tipc/configs/invdn/train_infer_python.txt b/test_tipc/configs/invdn/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..78df03128754596ae4db64596a7ed6854463a9a1
--- /dev/null
+++ b/test_tipc/configs/invdn/train_infer_python.txt
@@ -0,0 +1,51 @@
+===========================train_params===========================
+model_name:invdn
+python:python3.7
+gpu_list:0
+##
+auto_cast:null
+total_iters:lite_train_lite_infer=10
+output_dir:./output/
+snapshot_config.interval:lite_train_lite_infer=10
+pretrained_model:null
+train_model_name:invdn*/*checkpoint.pdparams
+train_infer_img_dir:null
+null:null
+##
+trainer:norm_train
+norm_train:tools/main.py -c configs/invdn_denoising.yaml --seed 100 -o log_config.interval=1
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+--output_dir:./output/
+load:null
+norm_export:tools/export_model.py -c configs/invdn_denoising.yaml --inputs_size=1,3,256,256 --model_name inference --load
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+inference_dir:inference
+train_model:./inference/invdn/invdnmodel_generator
+infer_export:null
+infer_quant:False
+inference:tools/inference.py --model_type invdn --seed 100 -c configs/invdn_denoising.yaml --output_path test_tipc/output/
+--device:gpu
+null:null
+null:null
+null:null
+null:null
+null:null
+--model_path:
+null:null
+null:null
+--benchmark:True
+null:null
diff --git a/test_tipc/configs/msvsr/model_linux_gpu_normal_normal_infer_cpp_linux_gpu_cpu.txt b/test_tipc/configs/msvsr/model_linux_gpu_normal_normal_infer_cpp_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..d96065b549fa5d3e33812b4eb5292321c1114a65
--- /dev/null
+++ b/test_tipc/configs/msvsr/model_linux_gpu_normal_normal_infer_cpp_linux_gpu_cpu.txt
@@ -0,0 +1,12 @@
+===========================cpp_infer_params===========================
+model_name:msvsr
+inference:./deploy/cpp_infer/build/vsr
+--infer_model_path:./inference/msvsr/multistagevsrmodel_generator.pdmodel
+--infer_param_path:./inference/msvsr/multistagevsrmodel_generator.pdiparams
+--video_path:./data/low_res.mp4
+--output_dir:./test_tipc/output/msvsr
+--frame_num:2
+--device:GPU
+--gpu_id:1
+--use_mkldnn:True
+--cpu_threads:1
diff --git a/test_tipc/configs/msvsr/train_infer_python.txt b/test_tipc/configs/msvsr/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..21539838a2bb69ea55df4b9b070d96d42d2294c6
--- /dev/null
+++ b/test_tipc/configs/msvsr/train_infer_python.txt
@@ -0,0 +1,59 @@
+===========================train_params===========================
+model_name:msvsr
+python:python3.7
+gpu_list:0
+##
+auto_cast:null
+total_iters:lite_train_lite_infer=10|lite_train_whole_infer=10|whole_train_whole_infer=200
+output_dir:./output/
+dataset.train.batch_size:lite_train_lite_infer=1|whole_train_whole_infer=1
+pretrained_model:null
+train_model_name:msvsr_reds*/*checkpoint.pdparams
+train_infer_img_dir:./data/msvsr_reds/test
+null:null
+##
+trainer:norm_train
+norm_train:tools/main.py -c configs/msvsr_reds.yaml --seed 123 -o log_config.interval=1 snapshot_config.interval=5 dataset.train.dataset.num_frames=15
+pact_train:null
+fpgm_train:null
+distill_train:null
+to_static_train:model.to_static=True
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+--output_dir:./output/
+load:null
+norm_export:tools/export_model.py -c configs/msvsr_reds.yaml --inputs_size="1,2,3,180,320" --model_name inference --load
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+inference_dir:inference
+train_model:./inference/msvsr/multistagevsrmodel_generator
+infer_export:null
+infer_quant:False
+inference:tools/inference.py --model_type msvsr -c configs/msvsr_reds.yaml --seed 123 -o dataset.test.num_frames=2 --output_path test_tipc/output/
+--device:cpu
+null:null
+null:null
+null:null
+null:null
+null:null
+--model_path:
+null:null
+null:null
+--benchmark:True
+null:null
+===========================train_benchmark_params==========================
+batch_size:2|4
+fp_items:fp32|fp16
+total_iters:60
+--profiler_options:batch_range=[10,20];state=GPU;tracer_option=Default;profile_path=model.profile
+flags:FLAGS_cudnn_exhaustive_search=0
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[2,3,180,320]}]
diff --git a/test_tipc/configs/msvsr/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/msvsr/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..2de77fb11980d56441a266ad001016032f8d4fa0
--- /dev/null
+++ b/test_tipc/configs/msvsr/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:msvsr
+python:python3.7
+gpu_list:0
+##
+auto_cast:null
+total_iters:lite_train_lite_infer=10|lite_train_whole_infer=10|whole_train_whole_infer=200
+output_dir:./output/
+dataset.train.batch_size:lite_train_lite_infer=1|whole_train_whole_infer=1
+pretrained_model:null
+train_model_name:msvsr_reds*/*checkpoint.pdparams
+train_infer_img_dir:./data/msvsr_reds/test
+null:null
+##
+trainer:amp_train
+amp_train:tools/main.py --amp --amp_level O1 -c configs/msvsr_reds.yaml --seed 123 -o dataset.train.num_workers=0 log_config.interval=1 snapshot_config.interval=5 dataset.train.dataset.num_frames=2
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+--output_dir:./output/
+load:null
+norm_export:tools/export_model.py -c configs/msvsr_reds.yaml --inputs_size="1,2,3,180,320" --model_name inference --load
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+inference_dir:inference
+train_model:./inference/msvsr/multistagevsrmodel_generator
+infer_export:null
+infer_quant:False
+inference:tools/inference.py --model_type msvsr -c configs/msvsr_reds.yaml --seed 123 -o dataset.test.num_frames=2 --output_path test_tipc/output/
+--device:cpu
+null:null
+null:null
+null:null
+null:null
+null:null
+--model_path:
+null:null
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[2,3,180,320]}]
diff --git a/test_tipc/configs/nafnet/train_infer_python.txt b/test_tipc/configs/nafnet/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..8cd3ddc16ebbe1ef62067831c8ca8770589f7a5a
--- /dev/null
+++ b/test_tipc/configs/nafnet/train_infer_python.txt
@@ -0,0 +1,51 @@
+===========================train_params===========================
+model_name:nafnet
+python:python3.7
+gpu_list:0
+##
+auto_cast:null
+total_iters:lite_train_lite_infer=10
+output_dir:./output/
+snapshot_config.interval:lite_train_lite_infer=10
+pretrained_model:null
+train_model_name:nafnet*/*checkpoint.pdparams
+train_infer_img_dir:null
+null:null
+##
+trainer:norm_train
+norm_train:tools/main.py -c configs/nafnet_denoising.yaml --seed 100 -o log_config.interval=1
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+--output_dir:./output/
+load:null
+norm_export:tools/export_model.py -c configs/nafnet_denoising.yaml --inputs_size=1,3,256,256 --model_name inference --load
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+inference_dir:inference
+train_model:./inference/nafnet/nafnetmodel_generator
+infer_export:null
+infer_quant:False
+inference:tools/inference.py --model_type nafnet --seed 100 -c configs/nafnet_denoising.yaml --output_path test_tipc/output/
+--device:gpu
+null:null
+null:null
+null:null
+null:null
+null:null
+--model_path:
+null:null
+null:null
+--benchmark:True
+null:null
diff --git a/test_tipc/configs/singan/train_infer_python.txt b/test_tipc/configs/singan/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..1d7f13da0921f51d6e194021294d38012c99ae19
--- /dev/null
+++ b/test_tipc/configs/singan/train_infer_python.txt
@@ -0,0 +1,51 @@
+===========================train_params===========================
+model_name:singan
+python:python3.7
+gpu_list:0
+##
+auto_cast:null
+total_iters:lite_train_lite_infer=100|whole_train_whole_infer=100000
+output_dir:./output/
+snapshot_config.interval:lite_train_lite_infer=25|whole_train_whole_infer=10000
+pretrained_model:null
+train_model_name:singan*/*checkpoint.pdparams
+train_infer_img_dir:./data/stone
+null:null
+##
+trainer:norm_train
+norm_train:tools/main.py -c configs/singan_universal.yaml --seed 123 -o log_config.interval=50
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+--output_dir:./output/
+load:null
+norm_export:tools/export_model.py -c configs/singan_universal.yaml --inputs_size=1 --load
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+inference_dir:singan_random_sample
+train_model:./inference/singan/singan_random_sample
+infer_export:null
+infer_quant:False
+inference:tools/inference.py --model_type singan --seed 123 -c configs/singan_universal.yaml --output_path test_tipc/output/
+--device:cpu
+null:null
+null:null
+null:null
+null:null
+null:null
+--model_path:
+null:null
+null:null
+--benchmark:True
+null:null
\ No newline at end of file
diff --git a/test_tipc/configs/swinir/train_infer_python.txt b/test_tipc/configs/swinir/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..f41cec2d4338c3c02f9e34190eb9595ac7944b11
--- /dev/null
+++ b/test_tipc/configs/swinir/train_infer_python.txt
@@ -0,0 +1,51 @@
+===========================train_params===========================
+model_name:swinir
+python:python3.7
+gpu_list:0
+##
+auto_cast:null
+total_iters:lite_train_lite_infer=10
+output_dir:./output/
+snapshot_config.interval:lite_train_lite_infer=10
+pretrained_model:null
+train_model_name:swinir*/*checkpoint.pdparams
+train_infer_img_dir:null
+null:null
+##
+trainer:norm_train
+norm_train:tools/main.py -c configs/swinir_denoising.yaml --seed 100 -o log_config.interval=1
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+--output_dir:./output/
+load:null
+norm_export:tools/export_model.py -c configs/swinir_denoising.yaml --inputs_size=1,3,128,128 --model_name inference --load
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+inference_dir:inference
+train_model:./inference/swinir/swinirmodel_generator
+infer_export:null
+infer_quant:False
+inference:tools/inference.py --model_type swinir --seed 100 -c configs/swinir_denoising.yaml --output_path test_tipc/output/
+--device:gpu
+null:null
+null:null
+null:null
+null:null
+null:null
+--model_path:
+null:null
+null:null
+--benchmark:True
+null:null
diff --git a/test_tipc/docs/benchmark_train.md b/test_tipc/docs/benchmark_train.md
new file mode 100644
index 0000000000000000000000000000000000000000..acd85d66370f7273b2bd8341f3ad3b598b018529
--- /dev/null
+++ b/test_tipc/docs/benchmark_train.md
@@ -0,0 +1,52 @@
+
+# TIPC Linux端Benchmark测试文档
+
+该文档为Benchmark测试说明,Benchmark预测功能测试的主程序为`benchmark_train.sh`,用于验证监控模型训练的性能。
+
+# 1. 测试流程
+## 1.1 准备数据和环境安装
+运行`test_tipc/prepare.sh`,完成训练数据准备和安装环境流程。
+
+```shell
+# 运行格式:bash test_tipc/prepare.sh train_benchmark.txt mode
+bash test_tipc/prepare.sh test_tipc/configs/msvsr/train_infer_python.txt benchmark_train
+```
+
+## 1.2 功能测试
+执行`test_tipc/benchmark_train.sh`,完成模型训练和日志解析
+
+```shell
+# 运行格式:bash test_tipc/benchmark_train.sh train_benchmark.txt mode
+bash test_tipc/benchmark_train.sh test_tipc/configs/msvsr/train_infer_python.txt benchmark_train
+```
+
+`test_tipc/benchmark_train.sh`支持根据传入的第三个参数实现只运行某一个训练配置,如下:
+```shell
+# 运行格式:bash test_tipc/benchmark_train.sh train_benchmark.txt mode
+bash test_tipc/benchmark_train.sh test_tipc/configs/msvsr/train_infer_python.txt benchmark_train dynamic_bs4_fp32_DP_N1C1
+```
+dynamic_bs4_fp32_DP_N1C1为test_tipc/benchmark_train.sh传入的参数,格式如下:
+`${modeltype}_${batch_size}_${fp_item}_${run_mode}_${device_num}`
+包含的信息有:模型类型、batchsize大小、训练精度如fp32,fp16等、分布式运行模式以及分布式训练使用的机器信息如单机单卡(N1C1)。
+
+
+## 2. 日志输出
+
+运行后将保存模型的训练日志和解析日志,使用 `test_tipc/configs/basicvsr/train_benchmark.txt` 参数文件的训练日志解析结果是:
+
+```
+{"model_branch": "dygaph", "model_commit": "7c39a1996b19087737c05d883fd346d2f39dbcc0", "model_name": "basicvsr_bs4_fp32_SingleP_DP", "batch_size": 4, "fp_item": "fp32", "run_process_type": "SingleP", "run_mode": "DP", "convergence_value": "5.413110", "convergence_key": "loss:", "ips": 19.333, "speed_unit": "samples/s", "device_num": "N1C1", "model_run_time": "0", "frame_commit": "8cc09552473b842c651ead3b9848d41827a3dbab", "frame_version": "0.0.0"}
+```
+
+训练日志和日志解析结果保存在benchmark_log目录下,文件组织格式如下:
+```
+train_log/
+├── index
+│ ├── PaddleGAN_msvsr_bs4_fp32_SingleP_DP_N1C1_speed
+│ └── PaddleGAN_msvsr_bs4_fp32_SingleP_DP_N1C4_speed
+├── profiling_log
+│ └── PaddleGAN_msvsr_bs4_fp32_SingleP_DP_N1C1_profiling
+└── train_log
+ ├── PaddleGAN_msvsr_bs4_fp32_SingleP_DP_N1C1_log
+ └── PaddleGAN_msvsr_bs4_fp32_MultiP_DP_N1C4_log
+```
diff --git a/test_tipc/docs/compare_right.png b/test_tipc/docs/compare_right.png
new file mode 100644
index 0000000000000000000000000000000000000000..af5766a30f0972e29405fbf5a9a36a8f35aece80
Binary files /dev/null and b/test_tipc/docs/compare_right.png differ
diff --git a/test_tipc/docs/compare_wrong.png b/test_tipc/docs/compare_wrong.png
new file mode 100644
index 0000000000000000000000000000000000000000..3454b54b0a0a722806fb65f76c01a4efdd9b9444
Binary files /dev/null and b/test_tipc/docs/compare_wrong.png differ
diff --git a/test_tipc/docs/test.png b/test_tipc/docs/test.png
new file mode 100644
index 0000000000000000000000000000000000000000..f99f23d7050eb61879cf317c0d7728ef14531b08
Binary files /dev/null and b/test_tipc/docs/test.png differ
diff --git a/test_tipc/docs/test_inference_cpp.md b/test_tipc/docs/test_inference_cpp.md
new file mode 100644
index 0000000000000000000000000000000000000000..5051b3e4be1bcd2fc698ade20cfa4e5a85bf1dd5
--- /dev/null
+++ b/test_tipc/docs/test_inference_cpp.md
@@ -0,0 +1,49 @@
+# C++预测功能测试
+
+C++预测功能测试的主程序为`test_inference_cpp.sh`,可以测试基于C++预测库的模型推理功能。
+
+## 1. 测试结论汇总
+
+| 模型类型 |device | batchsize | tensorrt | mkldnn | cpu多线程 |
+| :----: | :----: | :----: | :----: | :----: | :----: |
+| 正常模型 | GPU | 1 | - | - | - |
+| 正常模型 | CPU | 1 | - | fp32 | 支持 |
+
+## 2. 测试流程
+运行环境配置请参考[文档](../../docs/zh_CN/install.md)的内容安装PaddleGAN,TIPC推荐的环境:
+- PaddlePaddle=2.3.1
+- CUDA=10.2
+- cuDNN=7.6.5
+
+### 2.1 功能测试
+先运行`prepare.sh`准备数据和模型,然后运行`test_inference_cpp.sh`进行测试,msvsr模型的具体测试如下
+
+```bash
+# 准备模型和数据
+bash test_tipc/test_inference_cpp.sh test_tipc/configs/msvsr/inference_cpp.txt
+# cpp推理测试,可修改inference_cpp.txt配置累测试不同配置下的推理结果
+bash test_tipc/test_inference_cpp.sh test_tipc/configs/msvsr/inference_cpp.txt
+```
+
+运行预测指令后,在`test_tipc/output`文件夹下自动会保存运行日志和输出结果,包括以下文件:
+
+```shell
+test_tipc/output
+ ├── infer_cpp/results_cpp_infer.log # 运行指令状态的日志
+ ├── infer_cpp/infer_cpp_GPU.log # 使用GPU推理测试的日志
+ ├── infer_cpp/infer_cpp_CPU_use_mkldnn_threads_1.log # 使用CPU开启mkldnn,thread为1的推理测试日志
+ ├── output.mp4 # 视频超分预测结果
+......
+```
+其中results_cpp_infer.log中包含了每条指令的运行状态,如果运行成功会输出:
+
+```
+Run successfully with command - ./deploy/cpp_infer/build/vsr --model_path=./inference/msvsr/multistagevsrmodel_generator.pdmodel --param_path=./inference/msvsr/multistagevsrmodel_generator.pdiparams --video_path=./data/low_res.mp4 --output_dir=./test_tipc/output/msvsr --frame_num=2 --device=GPU --gpu_id=1 --use_mkldnn=True --cpu_threads=1 > ./test_tipc/output/infer_cpp/infer_cpp_GPU.log 2>&1!
+......
+```
+如果运行失败,会输出:
+```
+Run failed with command - ./deploy/cpp_infer/build/vsr --model_path=./inference/msvsr/multistagevsrmodel_generator.pdmodel --param_path=./inference/msvsr/multistagevsrmodel_generator.pdiparams --video_path=./data/low_res.mp4 --output_dir=./test_tipc/output/msvsr --frame_num=2 --device=GPU --gpu_id=1 --use_mkldnn=True --cpu_threads=1 > ./test_tipc/output/infer_cpp/infer_cpp_GPU.log 2>&1!
+......
+```
+可以根据results_cpp_infer.log中的内容判定哪一个指令运行错误。
diff --git a/test_tipc/docs/test_train_inference_python.md b/test_tipc/docs/test_train_inference_python.md
new file mode 100644
index 0000000000000000000000000000000000000000..0090fe606ace8e59e100cb46d69f4bd515c9c2d9
--- /dev/null
+++ b/test_tipc/docs/test_train_inference_python.md
@@ -0,0 +1,129 @@
+# Linux端基础训练预测功能测试
+
+Linux端基础训练预测功能测试的主程序为`test_train_inference_python.sh`,可以测试基于Python的模型训练、评估、推理等基本功能。
+
+
+## 1. 测试结论汇总
+
+- 训练相关:
+
+| 算法论文 | 模型名称 | 模型类型 | 基础
训练预测 | 更多
训练方式 | 模型压缩 | 其他预测部署 |
+| :--- | :--- | :----: | :--------: | :---- | :---- | :---- |
+| Pix2Pix |Pix2Pix | 生成 | 支持 | 多机多卡 | | |
+| CycleGAN |CycleGAN | 生成 | 支持 | 多机多卡 | | |
+| StyleGAN2 |StyleGAN2 | 生成 | 支持 | 多机多卡 | | |
+| FOMM |FOMM | 生成 | 支持 | 多机多卡 | | |
+| BasicVSR |BasicVSR | 超分 | 支持 | 多机多卡 | | |
+|PP-MSVSR|PP-MSVSR | 超分|
+|edvr|edvr | 超分|支持|
+|esrgan|esrgan | 超分|支持|
+
+- 预测相关:预测功能汇总如下,
+
+| 模型类型 |device | batchsize | tensorrt | mkldnn | cpu多线程 |
+| ---- | ---- | ---- | :----: | :----: | :----: |
+| 正常模型 | GPU | 1/6 | fp32 | - | - |
+
+
+
+## 2. 测试流程
+
+运行环境配置请参考[文档](../../docs/zh_CN/install.md)的内容配置运行环境。
+
+### 2.1 安装依赖
+- 安装PaddlePaddle >= 2.1
+- 安装PaddleGAN依赖
+ ```
+ pip install -v -e .
+ ```
+- 安装autolog(规范化日志输出工具)
+ ```
+ git clone https://github.com/LDOUBLEV/AutoLog
+ cd AutoLog
+ pip3 install -r requirements.txt
+ python3 setup.py bdist_wheel
+ pip3 install ./dist/auto_log-1.0.0-py3-none-any.whl
+ cd ../
+ ```
+
+
+### 2.2 功能测试
+先运行`prepare.sh`准备数据和模型,然后运行`test_train_inference_python.sh`进行测试,最终在```test_tipc/output```目录下生成`python_infer_*.log`格式的日志文件。
+
+
+`test_train_inference_python.sh`包含5种运行模式,每种模式的运行数据不同,分别用于测试速度和精度,分别是:
+
+- 模式1:lite_train_lite_infer,使用少量数据训练,用于快速验证训练到预测的走通流程,不验证精度和速度;
+```shell
+bash test_tipc/prepare.sh ./test_tipc/configs/basicvsr/train_infer_python.txt 'lite_train_lite_infer'
+bash test_tipc/test_train_inference_python.sh ./test_tipc/configs/basicvsr/train_infer_python.txt 'lite_train_lite_infer'
+```
+
+- 模式2:lite_train_whole_infer,使用少量数据训练,一定量数据预测,用于验证训练后的模型执行预测,预测速度是否合理;
+```shell
+bash test_tipc/prepare.sh ./test_tipc/configs/basicvsr/train_infer_python.txt 'lite_train_whole_infer'
+bash test_tipc/test_train_inference_python.sh ./test_tipc/configs/basicvsr/train_infer_python.txt 'lite_train_whole_infer'
+```
+
+- 模式3:whole_infer,不训练,全量数据预测,走通开源模型评估、动转静,检查inference model预测时间和精度;
+```shell
+bash test_tipc/prepare.sh ./test_tipc/configs/basicvsr/train_infer_python.txt 'whole_infer'
+bash test_tipc/test_train_inference_python.sh ./test_tipc/configs/basicvsr/train_infer_python.txt 'whole_infer'
+```
+
+- 模式4:whole_train_whole_infer,CE: 全量数据训练,全量数据预测,验证模型训练精度,预测精度,预测速度;
+```shell
+bash test_tipc/prepare.sh ./test_tipc/configs/basicvsr/train_infer_python.txt 'whole_train_whole_infer'
+bash test_tipc/test_train_inference_python.sh ./test_tipc/configs/basicvsr/train_infer_python.txt 'whole_train_whole_infer'
+```
+
+运行相应指令后,在`test_tipc/output`文件夹下自动会保存运行日志。如'lite_train_lite_infer'模式下,会运行训练+inference的链条,因此,在`test_tipc/output`文件夹有以下文件:
+```
+test_tipc/output/
+|- results_python.log # 运行指令状态的日志
+|- norm_train_gpus_0_autocast_null/ # GPU 0号卡上正常训练的训练日志和模型保存文件夹
+......
+```
+
+其中`results_python.log`中包含了每条指令的运行状态,如果运行成功会输出:
+```
+Run successfully with command - python3.7 tools/main.py -c configs/basicvsr_reds.yaml -o dataset.train.dataset.num_clips=2 output_dir=./test_tipc/output/norm_train_gpus_0_autocast_null total_iters=5 dataset.train.batch_size=1 !
+-=Run successfully with command - python3.7 tools/export_model.py -c configs/basicvsr_reds.yaml --inputs_size="1,6,3,180,320" --load ./test_tipc/output/norm_train_gpus_0_autocast_null/basicvsr_reds-2021-11-22-07-18/iter_1_checkpoint.pdparams --output_dir ./test_tipc/output/norm_train_gpus_0_autocast_null!
+......
+```
+如果运行失败,会输出:
+```
+Run failed with command - python3.7 tools/main.py -c configs/basicvsr_reds.yaml -o dataset.train.dataset.num_clips=2 output_dir=./test_tipc/output/norm_train_gpus_0_autocast_null total_iters=5 dataset.train.batch_size=1 ! !
+Run failed with command - python3.7 tools/export_model.py -c configs/basicvsr_reds.yaml --inputs_size="1,6,3,180,320" --load ./test_tipc/output/norm_train_gpus_0_autocast_null/basicvsr_reds-2021-11-22-07-18/iter_1_checkpoint.pdparams --output_dir ./test_tipc/output/norm_train_gpus_0_autocast_null!
+......
+```
+可以很方便的根据`results_python.log`中的内容判定哪一个指令运行错误。
+
+
+### 2.3 精度测试
+
+使用compare_results.py脚本比较模型预测的结果是否符合预期,主要步骤包括:
+- 提取日志中的预测坐标;
+- 从本地文件中提取保存好的坐标结果;
+- 比较上述两个结果是否符合精度预期,误差大于设置阈值时会报错。
+
+#### 使用方式
+运行命令:
+```shell
+python3.7 test_tipc/compare_results.py --gt_file=./test_tipc/results/*.txt --log_file=./test_tipc/output/*/*.txt --atol=1e-3 --rtol=1e-3
+```
+
+参数介绍:
+- gt_file: 指向事先保存好的预测结果路径,支持*.txt 结尾,会自动索引*.txt格式的文件,文件默认保存在test_tipc/result/ 文件夹下
+- log_file: 指向运行test_tipc/test_train_inference_python.sh 脚本的infer模式保存的预测日志,预测日志中打印的有预测结果,
+- atol: 设置的绝对误差
+- rtol: 设置的相对误差
+
+#### 运行结果
+
+正常运行效果如下图:
+ +
+出现不一致结果时的运行输出:
+
+
+出现不一致结果时的运行输出:
+ +
diff --git a/test_tipc/prepare.sh b/test_tipc/prepare.sh
new file mode 100644
index 0000000000000000000000000000000000000000..c43542c34d10e2a5a4697ce9140217af508afce0
--- /dev/null
+++ b/test_tipc/prepare.sh
@@ -0,0 +1,202 @@
+#!/bin/bash
+FILENAME=$1
+
+# MODE be one of ['lite_train_lite_infer' 'lite_train_whole_infer' 'whole_train_whole_infer',
+# 'whole_infer', 'benchmark_train', 'cpp_infer']
+
+MODE=$2
+
+dataline=$(cat ${FILENAME})
+
+# parser params
+IFS=$'\n'
+lines=(${dataline})
+function func_parser_key(){
+ strs=$1
+ IFS=":"
+ array=(${strs})
+ tmp=${array[0]}
+ echo ${tmp}
+}
+function func_parser_value(){
+ strs=$1
+ IFS=":"
+ array=(${strs})
+ tmp=${array[1]}
+ echo ${tmp}
+}
+IFS=$'\n'
+# The training params
+model_name=$(func_parser_value "${lines[1]}")
+trainer_list=$(func_parser_value "${lines[14]}")
+
+if [ ${MODE} = "benchmark_train" ];then
+ pip install -r requirements.txt
+ MODE="lite_train_lite_infer"
+fi
+
+if [ ${MODE} = "lite_train_lite_infer" ];then
+
+ case ${model_name} in
+ Pix2pix)
+ rm -rf ./data/pix2pix*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/pix2pix_facade_lite.tar --no-check-certificate
+ cd ./data/ && tar xf pix2pix_facade_lite.tar && cd ../ ;;
+ CycleGAN)
+ rm -rf ./data/cyclegan*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/cyclegan_horse2zebra_lite.tar --no-check-certificate
+ cd ./data/ && tar xf cyclegan_horse2zebra_lite.tar && cd ../ ;;
+ StyleGANv2)
+ rm -rf ./data/ffhq*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/ffhq_256.tar --no-check-certificate
+ cd ./data/ && tar xf ffhq_256.tar && cd ../ ;;
+ FOMM)
+ rm -rf ./data/fom_lite*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/fom_lite.tar --no-check-certificate --no-check-certificate
+ cd ./data/ && tar xf fom_lite.tar && cd ../ ;;
+ edvr|basicvsr|msvsr)
+ rm -rf ./data/reds*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/reds_lite.tar --no-check-certificate
+ cd ./data/ && tar xf reds_lite.tar && cd ../ ;;
+ esrgan)
+ rm -rf ./data/DIV2K*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/DIV2KandSet14paddle.tar --no-check-certificate
+ cd ./data/ && tar xf DIV2KandSet14paddle.tar && cd ../ ;;
+ swinir)
+ rm -rf ./data/*sets
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/swinir_data.zip --no-check-certificate
+ cd ./data/ && unzip -q swinir_data.zip && cd ../ ;;
+ invdn)
+ rm -rf ./data/SIDD_*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/SIDD_mini.zip --no-check-certificate
+ cd ./data/ && unzip -q SIDD_mini.zip && cd ../ ;;
+ nafnet)
+ rm -rf ./data/SIDD*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/SIDD_mini.zip --no-check-certificate
+ cd ./data/ && unzip -q SIDD_mini.zip && mkdir -p SIDD && mv ./SIDD_Medium_Srgb_Patches_512/* ./SIDD/ \
+ && mv ./SIDD_Valid_Srgb_Patches_256/* ./SIDD/ && mv ./SIDD/valid ./SIDD/val \
+ && mv ./SIDD/train/GT ./SIDD/train/target && mv ./SIDD/train/Noisy ./SIDD/train/input \
+ && mv ./SIDD/val/Noisy ./SIDD/val/input && mv ./SIDD/val/GT ./SIDD/val/target && cd ../ ;;
+ singan)
+ rm -rf ./data/singan*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/singan-official_images.zip --no-check-certificate
+ cd ./data/ && unzip -q singan-official_images.zip && cd ../
+ mkdir -p ./data/singan
+ mv ./data/SinGAN-official_images/Images/stone.png ./data/singan ;;
+ GFPGAN)
+ rm -rf ./data/gfpgan*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/gfpgan_tipc_data.zip --no-check-certificate
+ mkdir -p ./data/gfpgan_data
+ cd ./data/ && unzip -q gfpgan_tipc_data.zip -d gfpgan_data/ && cd ../ ;;
+ aotgan)
+ rm -rf ./data/aotgan*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/aotgan.zip --no-check-certificate
+ cd ./data/ && unzip -q aotgan.zip && cd ../ ;;
+ esac
+elif [ ${MODE} = "whole_train_whole_infer" ];then
+ if [ ${model_name} == "Pix2pix" ]; then
+ rm -rf ./data/facades*
+ wget -nc -P ./data/ http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/facades.tar.gz --no-check-certificate
+ cd ./data/ && tar -xzf facades.tar.gz && cd ../
+ elif [ ${model_name} == "CycleGAN" ]; then
+ rm -rf ./data/horse2zebra*
+ wget -nc -P ./data/ https://people.eecs.berkeley.edu/~taesung_park/CycleGAN/datasets/horse2zebra.zip --no-check-certificate
+ cd ./data/ && unzip horse2zebra.zip && cd ../
+ elif [ ${model_name} == "singan" ]; then
+ rm -rf ./data/singan*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/singan-official_images.zip --no-check-certificate
+ cd ./data/ && unzip -q singan-official_images.zip && cd ../
+ mkdir -p ./data/singan
+ mv ./data/SinGAN-official_images/Images/stone.png ./data/singan
+ fi
+elif [ ${MODE} = "lite_train_whole_infer" ];then
+ if [ ${model_name} == "Pix2pix" ]; then
+ rm -rf ./data/facades*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/pix2pix_facade_lite.tar --no-check-certificate
+ cd ./data/ && tar xf pix2pix_facade_lite.tar && cd ../
+ elif [ ${model_name} == "CycleGAN" ]; then
+ rm -rf ./data/horse2zebra*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/cyclegan_horse2zebra_lite.tar --no-check-certificate --no-check-certificate
+ cd ./data/ && tar xf cyclegan_horse2zebra_lite.tar && cd ../
+ elif [ ${model_name} == "FOMM" ]; then
+ rm -rf ./data/first_order*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/fom_lite.tar --no-check-certificate --no-check-certificate
+ cd ./data/ && tar xf fom_lite.tar && cd ../
+ elif [ ${model_name} == "StyleGANv2" ]; then
+ rm -rf ./data/ffhq*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/ffhq_256.tar --no-check-certificate
+ cd ./data/ && tar xf ffhq_256.tar && cd ../
+ elif [ ${model_name} == "basicvsr" ]; then
+ rm -rf ./data/reds*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/reds_lite.tar --no-check-certificate
+ cd ./data/ && tar xf reds_lite.tar && cd ../
+ elif [ ${model_name} == "msvsr" ]; then
+ rm -rf ./data/reds*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/reds_lite.tar --no-check-certificate
+ cd ./data/ && tar xf reds_lite.tar && cd ../
+ elif [ ${model_name} == "singan" ]; then
+ rm -rf ./data/singan*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/singan-official_images.zip --no-check-certificate
+ cd ./data/ && unzip -q singan-official_images.zip && cd ../
+ mkdir -p ./data/singan
+ mv ./data/SinGAN-official_images/Images/stone.png ./data/singan
+ fi
+elif [ ${MODE} = "whole_infer" ];then
+ if [ ${model_name} = "Pix2pix" ]; then
+ rm -rf ./data/facades*
+ rm -rf ./inference/pix2pix*
+ wget -nc -P ./inference https://paddlegan.bj.bcebos.com/static_model/pix2pix_facade.tar --no-check-certificate
+ wget -nc -P ./data https://paddlegan.bj.bcebos.com/datasets/facades_test.tar --no-check-certificate
+ cd ./data && tar xf facades_test.tar && mv facades_test facades && cd ../
+ cd ./inference && tar xf pix2pix_facade.tar && cd ../
+ elif [ ${model_name} = "CycleGAN" ]; then
+ rm -rf ./data/cyclegan*
+ rm -rf ./inference/cyclegan*
+ wget -nc -P ./inference https://paddlegan.bj.bcebos.com/static_model/cyclegan_horse2zebra.tar --no-check-certificate
+ wget -nc -P ./data https://paddlegan.bj.bcebos.com/datasets/cyclegan_horse2zebra_test.tar --no-check-certificate
+ cd ./data && tar xf cyclegan_horse2zebra_test.tar && mv cyclegan_test horse2zebra && cd ../
+ cd ./inference && tar xf cyclegan_horse2zebra.tar && cd ../
+ elif [ ${model_name} == "FOMM" ]; then
+ rm -rf ./data/first_order*
+ rm -rf ./inference/fom_dy2st*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/fom_lite_test.tar --no-check-certificate
+ wget -nc -P ./inference https://paddlegan.bj.bcebos.com/static_model/fom_dy2st.tar --no-check-certificate
+ cd ./data/ && tar xf fom_lite_test.tar && cd ../
+ cd ./inference && tar xf fom_dy2st.tar && cd ../
+ elif [ ${model_name} == "StyleGANv2" ]; then
+ rm -rf ./data/ffhq*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/ffhq_256.tar --no-check-certificate
+ wget -nc -P ./inference https://paddlegan.bj.bcebos.com/static_model/stylegan2_1024.tar --no-check-certificate
+ cd ./inference && tar xf stylegan2_1024.tar && cd ../
+ cd ./data/ && tar xf ffhq_256.tar && cd ../
+ elif [ ${model_name} == "basicvsr" ]; then
+ rm -rf ./data/reds*
+ rm -rf ./inference/basic*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/reds_lite.tar --no-check-certificate
+ wget -nc -P ./inference https://paddlegan.bj.bcebos.com/static_model/basicvsr.tar --no-check-certificate
+ cd ./inference && tar xf basicvsr.tar && cd ../
+ cd ./data/ && tar xf reds_lite.tar && cd ../
+ elif [ ${model_name} == "msvsr" ]; then
+ rm -rf ./data/reds*
+ rm -rf ./inference/msvsr*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/reds_lite.tar --no-check-certificate
+ wget -nc -P ./inference https://paddlegan.bj.bcebos.com/static_model/msvsr.tar --no-check-certificate
+ cd ./inference && tar xf msvsr.tar && cd ../
+ cd ./data/ && tar xf reds_lite.tar && cd ../
+ elif [ ${model_name} == "singan" ]; then
+ rm -rf ./data/singan*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/singan-official_images.zip --no-check-certificate
+ wget -nc -P ./inference https://paddlegan.bj.bcebos.com/datasets/singan.zip --no-check-certificate
+ cd ./data/ && unzip -q singan-official_images.zip && cd ../
+ cd ./inference/ && unzip -q singan.zip && cd ../
+ mkdir -p ./data/singan
+ mv ./data/SinGAN-official_images/Images/stone.png ./data/singan
+ fi
+elif [ ${MODE} = "cpp_infer" ]; then
+ if [ ${model_name} == "msvsr" ]; then
+ rm -rf ./inference/msvsr*
+ wget -nc -P ./inference https://paddlegan.bj.bcebos.com/static_model/msvsr.tar --no-check-certificate
+ cd ./inference && tar xf msvsr.tar && cd ../
+ wget -nc -P ./data https://paddlegan.bj.bcebos.com/datasets/low_res.mp4 --no-check-certificate
+ fi
+fi
diff --git a/test_tipc/results/python_basicvsr_results_fp32.txt b/test_tipc/results/python_basicvsr_results_fp32.txt
new file mode 100644
index 0000000000000000000000000000000000000000..1f0df64217ef2a8454c914a5398bc2f5279e7c7f
--- /dev/null
+++ b/test_tipc/results/python_basicvsr_results_fp32.txt
@@ -0,0 +1,2 @@
+Metric psnr: 27.0864
+Metric ssim: 0.7835
diff --git a/test_tipc/results/python_cyclegan_results_fp32.txt b/test_tipc/results/python_cyclegan_results_fp32.txt
new file mode 100644
index 0000000000000000000000000000000000000000..beffc319e03dee64c28d333f777e12ff4209b7fa
--- /dev/null
+++ b/test_tipc/results/python_cyclegan_results_fp32.txt
@@ -0,0 +1 @@
+Metric fid: 67.9814
diff --git a/test_tipc/results/python_fom_results_fp32.txt b/test_tipc/results/python_fom_results_fp32.txt
new file mode 100644
index 0000000000000000000000000000000000000000..8515822f73d267204eef9f89c9bd51d372c32b56
--- /dev/null
+++ b/test_tipc/results/python_fom_results_fp32.txt
@@ -0,0 +1 @@
+Metric l1 loss: 0.1210
diff --git a/test_tipc/results/python_msvsr_results_fp32.txt b/test_tipc/results/python_msvsr_results_fp32.txt
new file mode 100644
index 0000000000000000000000000000000000000000..01b8907f04d574feeda65c0e8e6c11c1e5cb2fd6
--- /dev/null
+++ b/test_tipc/results/python_msvsr_results_fp32.txt
@@ -0,0 +1,3 @@
+Metric psnr: 23.6020
+Metric ssim: 0.5636
+
diff --git a/test_tipc/results/python_pix2pix_results_fp32.txt b/test_tipc/results/python_pix2pix_results_fp32.txt
new file mode 100644
index 0000000000000000000000000000000000000000..4950de48cdae119a71628a37cbcad4e5e8db9ba8
--- /dev/null
+++ b/test_tipc/results/python_pix2pix_results_fp32.txt
@@ -0,0 +1 @@
+Metric fid: 139.3846
diff --git a/test_tipc/results/python_singan_results_fp32.txt b/test_tipc/results/python_singan_results_fp32.txt
new file mode 100644
index 0000000000000000000000000000000000000000..575aabd0cec4551b638ee62f66b87d0d8a8fef5c
--- /dev/null
+++ b/test_tipc/results/python_singan_results_fp32.txt
@@ -0,0 +1 @@
+Metric fid: 124.0369
diff --git a/test_tipc/results/python_stylegan2_results_fp32.txt b/test_tipc/results/python_stylegan2_results_fp32.txt
new file mode 100644
index 0000000000000000000000000000000000000000..3b384beb7205595a16e380ed2acffb7fd0e591ee
--- /dev/null
+++ b/test_tipc/results/python_stylegan2_results_fp32.txt
@@ -0,0 +1 @@
+Metric fid: 153.9647
diff --git a/test_tipc/test_inference_cpp.sh b/test_tipc/test_inference_cpp.sh
new file mode 100644
index 0000000000000000000000000000000000000000..c5f533c9ade38e3e419fa1e69e8e23b4c1cb1f4a
--- /dev/null
+++ b/test_tipc/test_inference_cpp.sh
@@ -0,0 +1,141 @@
+#!/bin/bash
+source test_tipc/common_func.sh
+
+FILENAME=$1
+MODE=$2
+dataline=$(awk 'NR==1, NR==18{print}' $FILENAME)
+
+# parser params
+IFS=$'\n'
+lines=(${dataline})
+
+# parser cpp inference params
+model_name=$(func_parser_value "${lines[1]}")
+infer_cmd=$(func_parser_value "${lines[2]}")
+model_path=$(func_parser_value "${lines[3]}")
+param_path=$(func_parser_value "${lines[4]}")
+video_path=$(func_parser_value "${lines[5]}")
+output_dir=$(func_parser_value "${lines[6]}")
+frame_num=$(func_parser_value "${lines[7]}")
+device=$(func_parser_value "${lines[8]}")
+gpu_id=$(func_parser_value "${lines[9]}")
+use_mkldnn=$(func_parser_value "${lines[10]}")
+cpu_threads=$(func_parser_value "${lines[11]}")
+
+# only support fp32、bs=1, trt is not supported yet.
+precision="fp32"
+use_trt=false
+batch_size=1
+
+LOG_PATH="./test_tipc/output/${model_name}/${MODE}"
+mkdir -p ${LOG_PATH}
+status_log="${LOG_PATH}/results_cpp.log"
+
+function func_cpp_inference(){
+ # set log
+ if [ ${device} = "GPU" ]; then
+ _save_log_path="${LOG_PATH}/cpp_infer_gpu_usetrt_${use_trt}_precision_${precision}_batchsize_${batch_size}.log"
+ elif [ ${device} = "CPU" ]; then
+ _save_log_path="${LOG_PATH}/cpp_infer_cpu_usemkldnn_${use_mkldnn}_threads_${cpu_threads}_precision_${precision}_batchsize_${batch_size}.log"
+ fi
+
+ # set params
+ set_model_path=$(func_set_params "--model_path" "${model_path}")
+ set_param_path=$(func_set_params "--param_path" "${param_path}")
+ set_video_path=$(func_set_params "--video_path" "${video_path}")
+ set_output_dir=$(func_set_params "--output_dir" "${output_dir}")
+ set_frame_num=$(func_set_params "--frame_num" "${frame_num}")
+ set_device=$(func_set_params "--device" "${device}")
+ set_gpu_id=$(func_set_params "--gpu_id" "${gpu_id}")
+ set_use_mkldnn=$(func_set_params "--use_mkldnn" "${use_mkldnn}")
+ set_cpu_threads=$(func_set_params "--cpu_threads" "${cpu_threads}")
+
+ # run infer
+ cmd="${infer_cmd} ${set_model_path} ${set_param_path} ${set_video_path} ${set_output_dir} ${set_frame_num} ${set_device} ${set_gpu_id} ${set_use_mkldnn} ${set_cpu_threads} > ${_save_log_path} 2>&1"
+ eval $cmd
+ last_status=${PIPESTATUS[0]}
+ status_check $last_status "${cmd}" "${status_log}" "${model_name}"
+}
+
+cd deploy/cpp_infer
+if [ -d "opencv-3.4.7/opencv3/" ] && [ $(md5sum opencv-3.4.7.tar.gz | awk -F ' ' '{print $1}') = "faa2b5950f8bee3f03118e600c74746a" ];then
+ echo "################### build opencv skipped ###################"
+else
+ echo "################### building opencv ###################"
+ rm -rf opencv-3.4.7.tar.gz opencv-3.4.7/
+ wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/test/opencv-3.4.7.tar.gz
+ tar -xf opencv-3.4.7.tar.gz
+
+ cd opencv-3.4.7/
+ install_path=$(pwd)/opencv3
+
+ rm -rf build
+ mkdir build
+ cd build
+
+ cmake .. \
+ -DCMAKE_INSTALL_PREFIX=${install_path} \
+ -DCMAKE_BUILD_TYPE=Release \
+ -DBUILD_SHARED_LIBS=OFF \
+ -DWITH_IPP=OFF \
+ -DBUILD_IPP_IW=OFF \
+ -DWITH_LAPACK=OFF \
+ -DWITH_EIGEN=OFF \
+ -DCMAKE_INSTALL_LIBDIR=lib64 \
+ -DWITH_ZLIB=ON \
+ -DBUILD_ZLIB=ON \
+ -DWITH_JPEG=ON \
+ -DBUILD_JPEG=ON \
+ -DWITH_PNG=ON \
+ -DBUILD_PNG=ON \
+ -DWITH_TIFF=ON \
+ -DBUILD_TIFF=ON \
+ -DWITH_FFMPEG=ON
+
+ make -j
+ make install
+ cd ../../
+ echo "################### building opencv finished ###################"
+fi
+
+if [ -d "paddle_inference" ]; then
+ echo "################### download inference lib skipped ###################"
+else
+ echo "################### downloading inference lib ###################"
+ wget -nc https://paddle-inference-lib.bj.bcebos.com/2.3.1/cxx_c/Linux/GPU/x86-64_gcc8.2_avx_mkl_cuda10.1_cudnn7.6.5_trt6.0.1.5/paddle_inference.tgz
+ tar -xf paddle_inference.tgz
+ echo "################### downloading inference lib finished ###################"
+fi
+
+echo "################### building PaddleGAN demo ####################"
+OPENCV_DIR=$(pwd)/opencv-3.4.7/opencv3
+LIB_DIR=$(pwd)/paddle_inference
+CUDA_LIB_DIR=$(dirname `find /usr -name libcudart.so`)
+CUDNN_LIB_DIR=$(dirname `find /usr -name libcudnn.so`)
+TENSORRT_DIR=''
+
+export LD_LIBRARY_PATH=$(dirname `find ${PWD} -name libonnxruntime.so.1.11.1`):"$LD_LIBRARY_PATH"
+export LD_LIBRARY_PATH=$(dirname `find ${PWD} -name libpaddle2onnx.so.0.9.9`):"$LD_LIBRARY_PATH"
+
+BUILD_DIR=build
+rm -rf ${BUILD_DIR}
+mkdir ${BUILD_DIR}
+cd ${BUILD_DIR}
+cmake .. \
+ -DPADDLE_LIB=${LIB_DIR} \
+ -DWITH_MKL=ON \
+ -DWITH_GPU=ON \
+ -DWITH_STATIC_LIB=OFF \
+ -DWITH_TENSORRT=OFF \
+ -DOPENCV_DIR=${OPENCV_DIR} \
+ -DCUDNN_LIB=${CUDNN_LIB_DIR} \
+ -DCUDA_LIB=${CUDA_LIB_DIR} \
+ -DTENSORRT_DIR=${TENSORRT_DIR}
+
+make -j
+cd ../
+echo "################### building PaddleGAN demo finished ###################"
+
+echo "################### running test ###################"
+cd ../../
+func_cpp_inference
diff --git a/test_tipc/test_train_inference_python.sh b/test_tipc/test_train_inference_python.sh
new file mode 100644
index 0000000000000000000000000000000000000000..c11e9b9a22d43628fad832e68f18beff9803516e
--- /dev/null
+++ b/test_tipc/test_train_inference_python.sh
@@ -0,0 +1,306 @@
+#!/bin/bash
+source test_tipc/common_func.sh
+
+FILENAME=$1
+# MODE be one of ['lite_train_lite_infer' 'lite_train_whole_infer' 'whole_train_whole_infer', 'whole_infer']
+MODE=$2
+
+dataline=$(awk 'NR==1, NR==51{print}' $FILENAME)
+
+# parser params
+IFS=$'\n'
+lines=(${dataline})
+# The training params
+model_name=$(func_parser_value "${lines[1]}")
+python=$(func_parser_value "${lines[2]}")
+gpu_list=$(func_parser_value "${lines[3]}")
+
+autocast_list=$(func_parser_value "${lines[5]}")
+epoch_key=$(func_parser_key "${lines[6]}")
+epoch_num=$(func_parser_params "${lines[6]}")
+save_model_key=$(func_parser_key "${lines[7]}")
+train_batch_key=$(func_parser_key "${lines[8]}")
+train_batch_value=$(func_parser_params "${lines[8]}")
+pretrain_model_key=$(func_parser_key "${lines[9]}")
+pretrain_model_value=$(func_parser_value "${lines[9]}")
+train_model_name=$(func_parser_value "${lines[10]}")
+train_infer_img_dir=$(func_parser_value "${lines[11]}")
+train_param_key1=$(func_parser_key "${lines[12]}")
+train_param_value1=$(func_parser_value "${lines[12]}")
+
+trainer_list=$(func_parser_value "${lines[14]}")
+
+trainer_norm=$(func_parser_key "${lines[15]}")
+norm_trainer=$(func_parser_value "${lines[15]}")
+
+to_static_key=$(func_parser_key "${lines[19]}")
+to_static_trainer=$(func_parser_value "${lines[19]}")
+trainer_key2=$(func_parser_key "${lines[20]}")
+trainer_value2=$(func_parser_value "${lines[20]}")
+
+eval_py=$(func_parser_value "${lines[23]}")
+eval_key1=$(func_parser_key "${lines[24]}")
+eval_value1=$(func_parser_value "${lines[24]}")
+
+save_infer_key=$(func_parser_key "${lines[27]}")
+export_weight=$(func_parser_value "${lines[28]}")
+norm_export=$(func_parser_value "${lines[29]}")
+
+inference_dir=$(func_parser_value "${lines[35]}")
+
+# parser inference model
+infer_model_dir_list=$(func_parser_value "${lines[36]}")
+infer_export_list=$(func_parser_value "${lines[37]}")
+infer_is_quant=$(func_parser_value "${lines[38]}")
+# parser inference
+inference_py=$(func_parser_value "${lines[39]}")
+use_gpu_key=$(func_parser_key "${lines[40]}")
+use_gpu_list=$(func_parser_value "${lines[40]}")
+use_mkldnn_key=$(func_parser_key "${lines[41]}")
+use_mkldnn_list=$(func_parser_value "${lines[41]}")
+cpu_threads_key=$(func_parser_key "${lines[42]}")
+cpu_threads_list=$(func_parser_value "${lines[42]}")
+batch_size_key=$(func_parser_key "${lines[43]}")
+batch_size_list=$(func_parser_value "${lines[43]}")
+use_trt_key=$(func_parser_key "${lines[44]}")
+use_trt_list=$(func_parser_value "${lines[44]}")
+precision_key=$(func_parser_key "${lines[45]}")
+precision_list=$(func_parser_value "${lines[45]}")
+infer_model_key=$(func_parser_key "${lines[46]}")
+image_dir_key=$(func_parser_key "${lines[47]}")
+infer_img_dir=$(func_parser_value "${lines[47]}")
+save_log_key=$(func_parser_key "${lines[48]}")
+infer_key1=$(func_parser_key "${lines[50]}")
+infer_value1=$(func_parser_value "${lines[50]}")
+
+LOG_PATH="./test_tipc/output/${model_name}/${MODE}"
+mkdir -p ${LOG_PATH}
+status_log="${LOG_PATH}/results_python.log"
+
+function func_inference(){
+ IFS='|'
+ _python=$1
+ _script=$2
+ _model_dir=$3
+ _log_path=$4
+ _img_dir=$5
+ _flag_quant=$6
+ # inference
+ for use_gpu in ${use_gpu_list[*]}; do
+ if [ ${use_gpu} = "False" ] || [ ${use_gpu} = "cpu" ]; then
+ for use_mkldnn in ${use_mkldnn_list[*]}; do
+ if [ ${use_mkldnn} = "False" ] && [ ${_flag_quant} = "True" ]; then
+ continue
+ fi
+ for threads in ${cpu_threads_list[*]}; do
+ for batch_size in ${batch_size_list[*]}; do
+ for precision in ${precision_list[*]}; do
+ set_precision=$(func_set_params "${precision_key}" "${precision}")
+
+ _save_log_path="${_log_path}/python_infer_cpu_usemkldnn_${use_mkldnn}_threads_${threads}_precision_${precision}_batchsize_${batch_size}.log"
+ set_infer_data=$(func_set_params "${image_dir_key}" "${_img_dir}")
+ set_benchmark=$(func_set_params "${benchmark_key}" "${benchmark_value}")
+ set_batchsize=$(func_set_params "${batch_size_key}" "${batch_size}")
+ set_cpu_threads=$(func_set_params "${cpu_threads_key}" "${threads}")
+ set_model_dir=$(func_set_params "${infer_model_key}" "${_model_dir}")
+ set_infer_params1=$(func_set_params "${infer_key1}" "${infer_value1}")
+ command="${_python} ${_script} ${use_gpu_key}=${use_gpu} ${set_model_dir} > ${_save_log_path} 2>&1 "
+ eval $command
+ last_status=${PIPESTATUS[0]}
+ eval "cat ${_save_log_path}"
+ status_check $last_status "${command}" "${status_log}" "${model_name}" "${_save_log_path}"
+ done
+ done
+ done
+ done
+ elif [ ${use_gpu} = "True" ] || [ ${use_gpu} = "gpu" ]; then
+ for use_trt in ${use_trt_list[*]}; do
+ for precision in ${precision_list[*]}; do
+ if [[ ${_flag_quant} = "False" ]] && [[ ${precision} =~ "int8" ]]; then
+ continue
+ fi
+ if [[ ${precision} =~ "fp16" || ${precision} =~ "int8" ]] && [ ${use_trt} = "False" ]; then
+ continue
+ fi
+ if [[ ${use_trt} = "False" || ${precision} =~ "int8" ]] && [ ${_flag_quant} = "True" ]; then
+ continue
+ fi
+ for batch_size in ${batch_size_list[*]}; do
+ _save_log_path="${_log_path}/python_infer_gpu_usetrt_${use_trt}_precision_${precision}_batchsize_${batch_size}.log"
+ set_infer_data=$(func_set_params "${image_dir_key}" "${_img_dir}")
+ set_benchmark=$(func_set_params "${benchmark_key}" "${benchmark_value}")
+ set_batchsize=$(func_set_params "${batch_size_key}" "${batch_size}")
+ set_tensorrt=$(func_set_params "${use_trt_key}" "${use_trt}")
+ set_precision=$(func_set_params "${precision_key}" "${precision}")
+ set_model_dir=$(func_set_params "${infer_model_key}" "${_model_dir}")
+ set_infer_params1=$(func_set_params "${infer_key1}" "${infer_value1}")
+ command="${_python} ${_script} ${use_gpu_key}=${use_gpu} ${set_tensorrt} ${set_precision} ${set_model_dir} ${set_batchsize} ${set_infer_data} ${set_benchmark} ${set_infer_params1} > ${_save_log_path} 2>&1 "
+ eval $command
+ last_status=${PIPESTATUS[0]}
+ eval "cat ${_save_log_path}"
+ status_check $last_status "${command}" "${status_log}" "${model_name}" "${_save_log_path}"
+
+ done
+ done
+ done
+ else
+ echo "Does not support hardware other than CPU and GPU Currently!"
+ fi
+ done
+}
+
+if [ ${MODE} = "whole_infer" ]; then
+ GPUID=$3
+ if [ ${#GPUID} -le 0 ];then
+ env=" "
+ else
+ env="export CUDA_VISIBLE_DEVICES=${GPUID}"
+ fi
+ # set CUDA_VISIBLE_DEVICES
+ eval $env
+ export Count=0
+ IFS="|"
+ infer_run_exports=(${infer_export_list})
+ infer_quant_flag=(${infer_is_quant})
+ for infer_model in ${infer_model_dir_list[*]}; do
+ # run export
+ if [ ${infer_run_exports[Count]} != "null" ];then
+ save_infer_dir=$(dirname $infer_model)
+ set_export_weight=$(func_set_params "${export_weight}" "${infer_model}")
+ set_save_infer_key="${save_infer_key} ${save_infer_dir}"
+ export_log_path="${LOG_PATH}_export_${Count}.log"
+ export_cmd="${python} ${infer_run_exports[Count]} ${set_export_weight} ${set_save_infer_key} > ${export_log_path} 2>&1"
+ echo ${infer_run_exports[Count]}
+ echo $export_cmd
+ eval $export_cmd
+ status_export=$?
+ status_check $status_export "${export_cmd}" "${status_log}" "${model_name}" "${export_log_path}"
+ else
+ save_infer_dir=${infer_model}
+ fi
+ #run inference
+ func_inference "${python}" "${inference_py}" "${save_infer_dir}" "${LOG_PATH}" "${infer_img_dir}"
+ Count=$(($Count + 1))
+ done
+else
+ IFS="|"
+ export Count=0
+ USE_GPU_KEY=(${train_use_gpu_value})
+ for gpu in ${gpu_list[*]}; do
+ train_use_gpu=${USE_GPU_KEY[Count]}
+ Count=$(($Count + 1))
+ ips=""
+ if [ ${gpu} = "-1" ];then
+ env=""
+ elif [ ${#gpu} -le 1 ];then
+ env="export CUDA_VISIBLE_DEVICES=${gpu}"
+ eval ${env}
+ elif [ ${#gpu} -le 15 ];then
+ IFS=","
+ array=(${gpu})
+ env="export CUDA_VISIBLE_DEVICES=${gpu}"
+ IFS="|"
+ else
+ IFS=";"
+ array=(${gpu})
+ ips=${array[0]}
+ gpu=${array[1]}
+ IFS="|"
+ env=" "
+ fi
+ for autocast in ${autocast_list[*]}; do
+ if [ ${autocast} = "fp16" ]; then
+ set_amp_config="--amp"
+ set_amp_level="--amp_level=O2"
+ else
+ set_amp_config=" "
+ set_amp_level=" "
+ fi
+ for trainer in ${trainer_list[*]}; do
+ flag_quant=False
+ # In case of @to_static, we re-used norm_traier,
+ # but append "-o Global.to_static=True" for config
+ # to trigger "apply_to_static" logic in 'engine.py'
+ if [ ${trainer} = "${to_static_key}" ]; then
+ run_train="${norm_trainer} ${to_static_trainer}"
+ run_export=${norm_export}
+ else
+ run_train=${norm_trainer}
+ run_export=${norm_export}
+ fi
+
+ if [ ${run_train} = "null" ]; then
+ continue
+ fi
+ set_autocast=$(func_set_params "${autocast_key}" "${autocast}")
+ set_epoch=$(func_set_params "${epoch_key}" "${epoch_num}")
+ set_pretrain=$(func_set_params "${pretrain_model_key}" "${pretrain_model_value}")
+ set_batchsize=$(func_set_params "${train_batch_key}" "${train_batch_value}")
+ set_train_params1=$(func_set_params "${train_param_key1}" "${train_param_value1}")
+ set_use_gpu=$(func_set_params "${train_use_gpu_key}" "${train_use_gpu}")
+ if [ ${#ips} -le 26 ];then
+ save_log="${LOG_PATH}/${trainer}_gpus_${gpu}_autocast_${autocast}"
+ nodes=1
+ else
+ IFS=","
+ ips_array=(${ips})
+ IFS="|"
+ nodes=${#ips_array[@]}
+ save_log="${LOG_PATH}/${trainer}_gpus_${gpu}_autocast_${autocast}_nodes_${nodes}"
+ fi
+ set_save_model=$(func_set_params "${save_model_key}" "${save_log}")
+ if [ ${#gpu} -le 2 ];then # train with cpu or single gpu
+ cmd="${python} ${run_train} ${set_use_gpu} ${set_save_model} ${set_train_params1} ${set_epoch} ${set_pretrain} ${set_batchsize} ${set_amp_config} ${set_amp_level}"
+ elif [ ${#ips} -le 26 ];then # train with multi-gpu
+ cmd="${python} -m paddle.distributed.launch --gpus=${gpu} ${run_train} ${set_use_gpu} ${set_save_model} ${set_train_params1} ${set_epoch} ${set_pretrain} ${set_batchsize} ${set_amp_config} ${set_amp_level}"
+ else # train with multi-machine
+ cmd="${python} -m paddle.distributed.launch --ips=${ips} --gpus=${gpu} ${run_train} ${set_use_gpu} ${set_save_model} ${set_train_params1} ${set_pretrain} ${set_epoch} ${set_batchsize} ${set_amp_config} ${set_amp_level}"
+ fi
+ # run train
+ export FLAGS_cudnn_deterministic=True
+ eval $cmd
+ echo $cmd
+ log_name=${train_model_name/checkpoint.pdparams/.txt}
+ train_log_path=$( echo "${save_log}/${log_name}")
+ eval "cat ${train_log_path} >> ${save_log}.log"
+ status_check $? "${cmd}" "${status_log}" "${model_name}" "${save_log}.log"
+
+ set_eval_pretrain=$(func_set_params "${pretrain_model_key}" "${save_log}/${train_model_name}")
+ # save norm trained models to set pretrain for pact training and fpgm training
+
+ # run eval
+ if [ ${eval_py} != "null" ]; then
+ set_eval_params1=$(func_set_params "${eval_key1}" "${eval_value1}")
+ eval_log_path="${LOG_PATH}/${trainer}_gpus_${gpu}_autocast_${autocast}_nodes_${nodes}_eval.log"
+ eval_cmd="${python} ${eval_py} ${set_eval_pretrain} ${set_use_gpu} ${set_eval_params1} > ${eval_log_path} 2>&1"
+ eval $eval_cmd
+ status_check $? "${eval_cmd}" "${status_log}" "${model_name}" "${eval_log_path}"
+ fi
+ # run export model
+ if [ ${run_export} != "null" ]; then
+ # run export model
+ save_infer_path="${save_log}"
+ set_export_weight="${save_log}/${train_model_name}"
+ set_export_weight_path=$( echo ${set_export_weight})
+ set_save_infer_key="${save_infer_key} ${save_infer_path}"
+ export_log_path="${LOG_PATH}/${trainer}_gpus_${gpu}_autocast_${autocast}_nodes_${nodes}_export.log"
+ export_cmd="${python} ${run_export} ${set_export_weight_path} ${set_save_infer_key} > ${export_log_path} 2>&1"
+ eval "$export_cmd"
+ status_check $? "${export_cmd}" "${status_log}" "${model_name}" "${export_log_path}"
+
+ #run inference
+ eval $env
+ save_infer_path="${save_log}"
+ if [ ${inference_dir} != "null" ] && [ ${inference_dir} != '##' ]; then
+ infer_model_dir="${save_infer_path}/${inference_dir}"
+ else
+ infer_model_dir=${save_infer_path}
+ fi
+ func_inference "${python}" "${inference_py}" "${infer_model_dir}" "${LOG_PATH}" "${train_infer_img_dir}" "${flag_quant}"
+
+ eval "unset CUDA_VISIBLE_DEVICES"
+ fi
+ done # done with: for trainer in ${trainer_list[*]}; do
+ done # done with: for autocast in ${autocast_list[*]}; do
+ done # done with: for gpu in ${gpu_list[*]}; do
+fi # end if [ ${MODE} = "infer" ]; then
diff --git a/test_tipc/test_train_inference_python_npu.sh b/test_tipc/test_train_inference_python_npu.sh
new file mode 100644
index 0000000000000000000000000000000000000000..a1e597236c490770ea6282c319c526d2543d1542
--- /dev/null
+++ b/test_tipc/test_train_inference_python_npu.sh
@@ -0,0 +1,38 @@
+#!/bin/bash
+source test_tipc/common_func.sh
+
+function readlinkf() {
+ perl -MCwd -e 'print Cwd::abs_path shift' "$1";
+}
+
+function func_parser_config() {
+ strs=$1
+ IFS=" "
+ array=(${strs})
+ tmp=${array[2]}
+ echo ${tmp}
+}
+
+BASEDIR=$(dirname "$0")
+REPO_ROOT_PATH=$(readlinkf ${BASEDIR}/../)
+
+FILENAME=$1
+
+# change gpu to npu in tipc txt configs
+sed -i "s/state=GPU/state=NPU/g" $FILENAME
+sed -i "s/--device:gpu/--device:npu/g" $FILENAME
+sed -i "s/--benchmark:True/--benchmark:False/g" $FILENAME
+dataline=`cat $FILENAME`
+
+# change gpu to npu in execution script
+sed -i 's/\"gpu\"/\"npu\"/g' test_tipc/test_train_inference_python.sh
+sed -i 's/--gpus/--npus/g' test_tipc/test_train_inference_python.sh
+
+# parser params
+IFS=$'\n'
+lines=(${dataline})
+
+# pass parameters to test_train_inference_python.sh
+cmd="bash test_tipc/test_train_inference_python.sh ${FILENAME} $2"
+echo $cmd
+eval $cmd
diff --git a/test_tipc/test_train_inference_python_xpu.sh b/test_tipc/test_train_inference_python_xpu.sh
new file mode 100644
index 0000000000000000000000000000000000000000..78dd55683efb4c3916e104f6a81cfc365cae9373
--- /dev/null
+++ b/test_tipc/test_train_inference_python_xpu.sh
@@ -0,0 +1,38 @@
+#!/bin/bash
+source test_tipc/common_func.sh
+
+function readlinkf() {
+ perl -MCwd -e 'print Cwd::abs_path shift' "$1";
+}
+
+function func_parser_config() {
+ strs=$1
+ IFS=" "
+ array=(${strs})
+ tmp=${array[2]}
+ echo ${tmp}
+}
+
+BASEDIR=$(dirname "$0")
+REPO_ROOT_PATH=$(readlinkf ${BASEDIR}/../)
+
+FILENAME=$1
+
+# change gpu to npu in tipc txt configs
+sed -i "s/state=GPU/state=XPU/g" $FILENAME
+sed -i "s/--device:gpu/--device:xpu/g" $FILENAME
+sed -i "s/--benchmark:True/--benchmark:False/g" $FILENAME
+dataline=`cat $FILENAME`
+
+# change gpu to npu in execution script
+sed -i 's/\"gpu\"/\"xpu\"/g' test_tipc/test_train_inference_python.sh
+sed -i 's/--gpus/--xpus/g' test_tipc/test_train_inference_python.sh
+
+# parser params
+IFS=$'\n'
+lines=(${dataline})
+
+# pass parameters to test_train_inference_python.sh
+cmd="bash test_tipc/test_train_inference_python.sh ${FILENAME} $2"
+echo $cmd
+eval $cmd
diff --git a/tools/export_model.py b/tools/export_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..42c5425505003d195de8e0da35a8f9dcb1b7db45
--- /dev/null
+++ b/tools/export_model.py
@@ -0,0 +1,88 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import sys
+import argparse
+
+sys.path.append(".")
+
+import ppgan
+from ppgan.utils.config import get_config
+from ppgan.utils.setup import setup
+from ppgan.engine.trainer import Trainer
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('-c',
+ '--config-file',
+ metavar="FILE",
+ required=True,
+ help="config file path")
+ parser.add_argument("--load",
+ type=str,
+ default=None,
+ required=True,
+ help="put the path to resuming file if needed")
+ # config options
+ parser.add_argument("-o",
+ "--opt",
+ nargs="+",
+ help="set configuration options")
+ parser.add_argument("-s",
+ "--inputs_size",
+ type=str,
+ default=None,
+ required=True,
+ help="the inputs size")
+ parser.add_argument(
+ "--output_dir",
+ default=None,
+ type=str,
+ help="The path prefix of inference model to be used.",
+ )
+ parser.add_argument(
+ "--export_serving_model",
+ default=False,
+ type=bool,
+ help="export serving model.",
+ )
+ parser.add_argument(
+ "--model_name",
+ default=None,
+ type=str,
+ help="model_name.",
+ )
+ args = parser.parse_args()
+ return args
+
+
+def main(args, cfg):
+ inputs_size = [[int(size) for size in input_size.split(',')]
+ for input_size in args.inputs_size.split(';')]
+ model = ppgan.models.builder.build_model(cfg.model)
+ model.setup_train_mode(is_train=False)
+ state_dicts = ppgan.utils.filesystem.load(args.load)
+ for net_name, net in model.nets.items():
+ if net_name in state_dicts:
+ net.set_state_dict(state_dicts[net_name])
+ model.export_model(cfg.export_model, args.output_dir, inputs_size,
+ args.export_serving_model, args.model_name)
+
+
+if __name__ == "__main__":
+ args = parse_args()
+ cfg = get_config(args.config_file, args.opt)
+ main(args, cfg)
diff --git a/tools/extract_weight.py b/tools/extract_weight.py
new file mode 100644
index 0000000000000000000000000000000000000000..56dffa9f1570fe8bed6bf9e510d9fec66a5de60c
--- /dev/null
+++ b/tools/extract_weight.py
@@ -0,0 +1,40 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import paddle
+import argparse
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='This script extracts weights from a checkpoint')
+ parser.add_argument('checkpoint', help='checkpoint file')
+ parser.add_argument('--net-name',
+ type=str,
+ help='net name in checkpoint dict')
+ parser.add_argument('--output', type=str, help='destination file name')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ assert args.output.endswith(".pdparams")
+ ckpt = paddle.load(args.checkpoint)
+ state_dict = ckpt[args.net_name]
+ paddle.save(state_dict, args.output)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/fom_infer.py b/tools/fom_infer.py
new file mode 100644
index 0000000000000000000000000000000000000000..b3f0969a30e0b42fd49c561da23ff4def9c3d04e
--- /dev/null
+++ b/tools/fom_infer.py
@@ -0,0 +1,245 @@
+import paddle.inference as paddle_infer
+import argparse
+import numpy as np
+import cv2
+import imageio
+import time
+from tqdm import tqdm
+import os
+from functools import reduce
+import paddle
+from ppgan.utils.filesystem import makedirs
+from pathlib import Path
+
+
+def read_img(path):
+ img = imageio.imread(path)
+ if img.ndim == 2:
+ img = np.expand_dims(img, axis=2)
+ # som images have 4 channels
+ if img.shape[2] > 3:
+ img = img[:, :, :3]
+ return img
+
+
+def read_video(path):
+ reader = imageio.get_reader(path)
+ fps = reader.get_meta_data()['fps']
+ driving_video = []
+ try:
+ for im in reader:
+ driving_video.append(im)
+ except RuntimeError:
+ print("Read driving video error!")
+ pass
+ reader.close()
+ return driving_video, fps
+
+
+def face_detection(img_ori, weight_path):
+ config = paddle_infer.Config(os.path.join(weight_path, '__model__'),
+ os.path.join(weight_path, '__params__'))
+ config.disable_gpu()
+ # disable print log when predict
+ config.disable_glog_info()
+ # enable shared memory
+ config.enable_memory_optim()
+ # disable feed, fetch OP, needed by zero_copy_run
+ config.switch_use_feed_fetch_ops(False)
+ predictor = paddle_infer.create_predictor(config)
+
+ img = img_ori.astype(np.float32)
+ mean = np.array([123, 117, 104])[np.newaxis, np.newaxis, :]
+ std = np.array([127.502231, 127.502231, 127.502231])[np.newaxis,
+ np.newaxis, :]
+ img -= mean
+ img /= std
+ img = img[:, :, [2, 1, 0]]
+ img = img[np.newaxis].transpose([0, 3, 1, 2])
+
+ input_names = predictor.get_input_names()
+ input_tensor = predictor.get_input_handle(input_names[0])
+ input_tensor.copy_from_cpu(img)
+ predictor.run()
+ output_names = predictor.get_output_names()
+ boxes_tensor = predictor.get_output_handle(output_names[0])
+ np_boxes = boxes_tensor.copy_to_cpu()
+ if reduce(lambda x, y: x * y, np_boxes.shape) < 6:
+ print('[WARNNING] No object detected.')
+ exit()
+ w, h = img.shape[2:]
+ np_boxes[:, 2] *= h
+ np_boxes[:, 3] *= w
+ np_boxes[:, 4] *= h
+ np_boxes[:, 5] *= w
+ expect_boxes = (np_boxes[:, 1] > 0.5) & (np_boxes[:, 0] > -1)
+ rect = np_boxes[expect_boxes, :][0][2:]
+ bh = rect[3] - rect[1]
+ bw = rect[2] - rect[0]
+ cy = rect[1] + int(bh / 2)
+ cx = rect[0] + int(bw / 2)
+ margin = max(bh, bw)
+ y1 = max(0, cy - margin)
+ x1 = max(0, cx - int(0.8 * margin))
+ y2 = min(h, cy + margin)
+ x2 = min(w, cx + int(0.8 * margin))
+ return int(y1), int(y2), int(x1), int(x2)
+
+
+def main():
+ args = parse_args()
+
+ source_path = args.source_path
+ driving_path = Path(args.driving_path)
+ makedirs(args.output_path)
+ if driving_path.is_dir():
+ driving_paths = list(driving_path.iterdir())
+ else:
+ driving_paths = [driving_path]
+
+ # 创建 config
+ kp_detector_config = paddle_infer.Config(
+ os.path.join(args.model_path, "kp_detector.pdmodel"),
+ os.path.join(args.model_path, "kp_detector.pdiparams"))
+ generator_config = paddle_infer.Config(
+ os.path.join(args.model_path, "generator.pdmodel"),
+ os.path.join(args.model_path, "generator.pdiparams"))
+ if args.device == "gpu":
+ kp_detector_config.enable_use_gpu(100, 0)
+ generator_config.enable_use_gpu(100, 0)
+ elif args.device == "xpu":
+ kp_detector_config.enable_xpu()
+ generator_config.enable_xpu()
+ elif args.device == "npu":
+ kp_detector_config.enable_npu()
+ generator_config.enable_npu()
+ else:
+ kp_detector_config.set_mkldnn_cache_capacity(10)
+ kp_detector_config.enable_mkldnn()
+ generator_config.set_mkldnn_cache_capacity(10)
+ generator_config.enable_mkldnn()
+ kp_detector_config.disable_gpu()
+ kp_detector_config.set_cpu_math_library_num_threads(6)
+ generator_config.disable_gpu()
+ generator_config.set_cpu_math_library_num_threads(6)
+ # 根据 config 创建 predictor
+ kp_detector_predictor = paddle_infer.create_predictor(kp_detector_config)
+ generator_predictor = paddle_infer.create_predictor(generator_config)
+ test_loss = []
+ for k in range(len(driving_paths)):
+ driving_path = driving_paths[k]
+ driving_video, fps = read_video(driving_path)
+ driving_video = [
+ cv2.resize(frame, (256, 256)) / 255.0 for frame in driving_video
+ ]
+ driving_len = len(driving_video)
+ driving_video = np.array(driving_video).astype(np.float32).transpose(
+ [0, 3, 1, 2])
+
+ if source_path == None:
+ source = driving_video[0:1]
+ else:
+ source_img = read_img(source_path)
+ #Todo:add blazeface static model
+ #left, right, up, bottom = face_detection(source_img, "/workspace/PaddleDetection/static/inference_model/blazeface/")
+ source = source_img #[left:right, up:bottom]
+ source = cv2.resize(source, (256, 256)) / 255.0
+ source = source[np.newaxis].astype(np.float32).transpose(
+ [0, 3, 1, 2])
+
+ # 获取输入的名称
+ kp_detector_input_names = kp_detector_predictor.get_input_names()
+ kp_detector_input_handle = kp_detector_predictor.get_input_handle(
+ kp_detector_input_names[0])
+
+ kp_detector_input_handle.reshape([args.batch_size, 3, 256, 256])
+ kp_detector_input_handle.copy_from_cpu(source)
+ kp_detector_predictor.run()
+ kp_detector_output_names = kp_detector_predictor.get_output_names()
+ kp_detector_output_handle = kp_detector_predictor.get_output_handle(
+ kp_detector_output_names[0])
+ source_j = kp_detector_output_handle.copy_to_cpu()
+ kp_detector_output_handle = kp_detector_predictor.get_output_handle(
+ kp_detector_output_names[1])
+ source_v = kp_detector_output_handle.copy_to_cpu()
+
+ kp_detector_input_handle.reshape([args.batch_size, 3, 256, 256])
+ kp_detector_input_handle.copy_from_cpu(driving_video[0:1])
+ kp_detector_predictor.run()
+ kp_detector_output_names = kp_detector_predictor.get_output_names()
+ kp_detector_output_handle = kp_detector_predictor.get_output_handle(
+ kp_detector_output_names[0])
+ driving_init_j = kp_detector_output_handle.copy_to_cpu()
+ kp_detector_output_handle = kp_detector_predictor.get_output_handle(
+ kp_detector_output_names[1])
+ driving_init_v = kp_detector_output_handle.copy_to_cpu()
+ start_time = time.time()
+ results = []
+ for i in tqdm(range(0, driving_len)):
+ kp_detector_input_handle.copy_from_cpu(driving_video[i:i + 1])
+ kp_detector_predictor.run()
+ kp_detector_output_names = kp_detector_predictor.get_output_names()
+ kp_detector_output_handle = kp_detector_predictor.get_output_handle(
+ kp_detector_output_names[0])
+ driving_j = kp_detector_output_handle.copy_to_cpu()
+ kp_detector_output_handle = kp_detector_predictor.get_output_handle(
+ kp_detector_output_names[1])
+ driving_v = kp_detector_output_handle.copy_to_cpu()
+ generator_inputs = [
+ source, source_j, source_v, driving_j, driving_v,
+ driving_init_j, driving_init_v
+ ]
+ generator_input_names = generator_predictor.get_input_names()
+ for i in range(len(generator_input_names)):
+ generator_input_handle = generator_predictor.get_input_handle(
+ generator_input_names[i])
+ generator_input_handle.copy_from_cpu(generator_inputs[i])
+ generator_predictor.run()
+ generator_output_names = generator_predictor.get_output_names()
+ generator_output_handle = generator_predictor.get_output_handle(
+ generator_output_names[0])
+ output_data = generator_output_handle.copy_to_cpu()
+ loss = paddle.abs(
+ paddle.to_tensor(output_data) -
+ paddle.to_tensor(driving_video[i])).mean().cpu().numpy()
+ test_loss.append(loss)
+ output_data = np.transpose(output_data, [0, 2, 3, 1])[0] * 255.0
+
+ #Todo:add blazeface static model
+ #frame = source_img.copy()
+ #frame[left:right, up:bottom] = cv2.resize(output_data.astype(np.uint8), (bottom - up, right - left), cv2.INTER_AREA)
+ results.append(output_data.astype(np.uint8))
+ print(time.time() - start_time)
+ imageio.mimsave(os.path.join(args.output_path,
+ "result_" + str(k) + ".mp4"),
+ [frame for frame in results],
+ fps=fps)
+ metric_file = os.path.join(args.output_path, "metric.txt")
+ log_file = open(metric_file, 'a')
+ loss_string = "Metric {}: {:.4f}".format("l1 loss", np.mean(test_loss))
+ log_file.close()
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--model_path", type=str, help="model filename profix")
+ parser.add_argument("--batch_size", type=int, default=1, help="batch size")
+ parser.add_argument("--source_path",
+ type=str,
+ default=None,
+ help="source_path")
+ parser.add_argument("--driving_path",
+ type=str,
+ default=None,
+ help="driving_path")
+ parser.add_argument("--output_path",
+ type=str,
+ default="infer_output/fom/",
+ help="output_path")
+ parser.add_argument("--device", type=str, default="gpu", help="device")
+
+ return parser.parse_args()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/tools/inference.py b/tools/inference.py
new file mode 100644
index 0000000000000000000000000000000000000000..11ea4f4026e83e49672fc5732ca1eb835d12294b
--- /dev/null
+++ b/tools/inference.py
@@ -0,0 +1,471 @@
+import paddle
+import argparse
+import numpy as np
+import random
+import os
+from collections import OrderedDict
+import sys
+import cv2
+
+sys.path.append(".")
+
+from ppgan.utils.config import get_config
+from ppgan.datasets.builder import build_dataloader
+from ppgan.engine.trainer import IterLoader
+from ppgan.utils.visual import save_image
+from ppgan.utils.visual import tensor2img
+from ppgan.utils.filesystem import makedirs
+from ppgan.metrics import build_metric
+
+
+MODEL_CLASSES = ["pix2pix", "cyclegan", "wav2lip", "esrgan", \
+ "edvr", "fom", "stylegan2", "basicvsr", "msvsr", \
+ "singan", "swinir", "invdn", "aotgan", "nafnet"]
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "--model_path",
+ default=None,
+ type=str,
+ required=True,
+ help="The path prefix of inference model to be used.",
+ )
+ parser.add_argument("--model_type",
+ default=None,
+ type=str,
+ required=True,
+ help="Model type selected in the list: " +
+ ", ".join(MODEL_CLASSES))
+ parser.add_argument(
+ "--device",
+ default="gpu",
+ type=str,
+ choices=["cpu", "gpu", "xpu", "npu"],
+ help="The device to select to train the model, is must be cpu/gpu/xpu.")
+ parser.add_argument('-c',
+ '--config-file',
+ metavar="FILE",
+ help='config file path')
+ parser.add_argument("--output_path",
+ type=str,
+ default="infer_output",
+ help="output_path")
+ # config options
+ parser.add_argument("-o",
+ "--opt",
+ nargs='+',
+ help="set configuration options")
+ # fix random numbers by setting seed
+ parser.add_argument('--seed',
+ type=int,
+ default=None,
+ help='fix random numbers by setting seed\".')
+ # for tensorRT
+ parser.add_argument("--run_mode",
+ default="fluid",
+ type=str,
+ choices=["fluid", "trt_fp32", "trt_fp16"],
+ help="mode of running(fluid/trt_fp32/trt_fp16)")
+ parser.add_argument("--trt_min_shape",
+ default=1,
+ type=int,
+ help="trt_min_shape for tensorRT")
+ parser.add_argument("--trt_max_shape",
+ default=1280,
+ type=int,
+ help="trt_max_shape for tensorRT")
+ parser.add_argument("--trt_opt_shape",
+ default=640,
+ type=int,
+ help="trt_opt_shape for tensorRT")
+ parser.add_argument("--min_subgraph_size",
+ default=3,
+ type=int,
+ help="trt_opt_shape for tensorRT")
+ parser.add_argument("--batch_size",
+ default=1,
+ type=int,
+ help="batch_size for tensorRT")
+ parser.add_argument("--use_dynamic_shape",
+ dest="use_dynamic_shape",
+ action="store_true",
+ help="use_dynamic_shape for tensorRT")
+ parser.add_argument("--trt_calib_mode",
+ dest="trt_calib_mode",
+ action="store_true",
+ help="trt_calib_mode for tensorRT")
+ args = parser.parse_args()
+ return args
+
+
+def create_predictor(model_path,
+ device="gpu",
+ run_mode='fluid',
+ batch_size=1,
+ min_subgraph_size=3,
+ use_dynamic_shape=False,
+ trt_min_shape=1,
+ trt_max_shape=1280,
+ trt_opt_shape=640,
+ trt_calib_mode=False):
+ config = paddle.inference.Config(model_path + ".pdmodel",
+ model_path + ".pdiparams")
+ if device == "gpu":
+ config.enable_use_gpu(100, 0)
+ elif device == "cpu":
+ config.disable_gpu()
+ elif device == "npu":
+ config.enable_npu()
+ elif device == "xpu":
+ config.enable_xpu()
+ else:
+ config.disable_gpu()
+
+ precision_map = {
+ 'trt_int8': paddle.inference.Config.Precision.Int8,
+ 'trt_fp32': paddle.inference.Config.Precision.Float32,
+ 'trt_fp16': paddle.inference.Config.Precision.Half
+ }
+ if run_mode in precision_map.keys():
+ config.enable_tensorrt_engine(workspace_size=1 << 25,
+ max_batch_size=batch_size,
+ min_subgraph_size=min_subgraph_size,
+ precision_mode=precision_map[run_mode],
+ use_static=False,
+ use_calib_mode=trt_calib_mode)
+
+ if use_dynamic_shape:
+ min_input_shape = {
+ 'image': [batch_size, 3, trt_min_shape, trt_min_shape]
+ }
+ max_input_shape = {
+ 'image': [batch_size, 3, trt_max_shape, trt_max_shape]
+ }
+ opt_input_shape = {
+ 'image': [batch_size, 3, trt_opt_shape, trt_opt_shape]
+ }
+ config.set_trt_dynamic_shape_info(min_input_shape, max_input_shape,
+ opt_input_shape)
+ print('trt set dynamic shape done!')
+
+ predictor = paddle.inference.create_predictor(config)
+ return predictor
+
+
+def setup_metrics(cfg):
+ metrics = OrderedDict()
+ if isinstance(list(cfg.values())[0], dict):
+ for metric_name, cfg_ in cfg.items():
+ metrics[metric_name] = build_metric(cfg_)
+ else:
+ metric = build_metric(cfg)
+ metrics[metric.__class__.__name__] = metric
+
+ return metrics
+
+
+def main():
+ args = parse_args()
+ if args.seed:
+ paddle.seed(args.seed)
+ random.seed(args.seed)
+ np.random.seed(args.seed)
+ cfg = get_config(args.config_file, args.opt)
+ predictor = create_predictor(args.model_path, args.device, args.run_mode,
+ args.batch_size, args.min_subgraph_size,
+ args.use_dynamic_shape, args.trt_min_shape,
+ args.trt_max_shape, args.trt_opt_shape,
+ args.trt_calib_mode)
+ input_handles = [
+ predictor.get_input_handle(name)
+ for name in predictor.get_input_names()
+ ]
+
+ output_handle = predictor.get_output_handle(predictor.get_output_names()[0])
+ test_dataloader = build_dataloader(cfg.dataset.test,
+ is_train=False,
+ distributed=False)
+
+ max_eval_steps = len(test_dataloader)
+ iter_loader = IterLoader(test_dataloader)
+ min_max = cfg.get('min_max', None)
+ if min_max is None:
+ min_max = (-1., 1.)
+
+ model_type = args.model_type
+ makedirs(os.path.join(args.output_path, model_type))
+
+ validate_cfg = cfg.get('validate', None)
+ metrics = None
+ if validate_cfg and 'metrics' in validate_cfg:
+ metrics = setup_metrics(validate_cfg['metrics'])
+ for metric in metrics.values():
+ metric.reset()
+
+ for i in range(max_eval_steps):
+ data = next(iter_loader)
+ if model_type == "pix2pix":
+ real_A = data['B'].numpy()
+ input_handles[0].copy_from_cpu(real_A)
+ predictor.run()
+ prediction = output_handle.copy_to_cpu()
+ prediction = paddle.to_tensor(prediction)
+ image_numpy = tensor2img(prediction[0], min_max)
+ save_image(
+ image_numpy,
+ os.path.join(args.output_path, "pix2pix/{}.png".format(i)))
+ metric_file = os.path.join(args.output_path, "pix2pix/metric.txt")
+ real_B = paddle.to_tensor(data['A'])
+ for metric in metrics.values():
+ metric.update(prediction, real_B)
+
+ elif model_type == "cyclegan":
+ real_A = data['A'].numpy()
+ input_handles[0].copy_from_cpu(real_A)
+ predictor.run()
+ prediction = output_handle.copy_to_cpu()
+ prediction = paddle.to_tensor(prediction)
+ image_numpy = tensor2img(prediction[0], min_max)
+ save_image(
+ image_numpy,
+ os.path.join(args.output_path, "cyclegan/{}.png".format(i)))
+ metric_file = os.path.join(args.output_path, "cyclegan/metric.txt")
+ real_B = paddle.to_tensor(data['B'])
+ for metric in metrics.values():
+ metric.update(prediction, real_B)
+
+ elif model_type == "wav2lip":
+ indiv_mels, x = data['indiv_mels'].numpy()[0], data['x'].numpy()[0]
+ x = x.transpose([1, 0, 2, 3])
+ input_handles[0].copy_from_cpu(indiv_mels)
+ input_handles[1].copy_from_cpu(x)
+ predictor.run()
+ prediction = output_handle.copy_to_cpu()
+ for j in range(prediction.shape[0]):
+ prediction[j] = prediction[j][::-1, :, :]
+ image_numpy = paddle.to_tensor(prediction[j])
+ image_numpy = tensor2img(image_numpy, (0, 1))
+ save_image(image_numpy,
+ "infer_output/wav2lip/{}_{}.png".format(i, j))
+
+ elif model_type == "esrgan":
+ lq = data['lq'].numpy()
+ input_handles[0].copy_from_cpu(lq)
+ predictor.run()
+ prediction = output_handle.copy_to_cpu()
+ prediction = paddle.to_tensor(prediction[0])
+ image_numpy = tensor2img(prediction, min_max)
+ gt_numpy = tensor2img(data['gt'][0], min_max)
+ save_image(
+ image_numpy,
+ os.path.join(args.output_path, "esrgan/{}.png".format(i)))
+ metric_file = os.path.join(args.output_path, model_type,
+ "metric.txt")
+ for metric in metrics.values():
+ metric.update(image_numpy, gt_numpy)
+ break
+ elif model_type == "edvr":
+ lq = data['lq'].numpy()
+ input_handles[0].copy_from_cpu(lq)
+ predictor.run()
+ prediction = output_handle.copy_to_cpu()
+ prediction = paddle.to_tensor(prediction[0])
+ image_numpy = tensor2img(prediction, min_max)
+ gt_numpy = tensor2img(data['gt'][0, 0], min_max)
+ save_image(image_numpy,
+ os.path.join(args.output_path, "edvr/{}.png".format(i)))
+ metric_file = os.path.join(args.output_path, model_type,
+ "metric.txt")
+ for metric in metrics.values():
+ metric.update(image_numpy, gt_numpy)
+ break
+ elif model_type == "stylegan2":
+ noise = paddle.randn([1, 1, 512]).cpu().numpy()
+ input_handles[0].copy_from_cpu(noise)
+ input_handles[1].copy_from_cpu(np.array([0.7]).astype('float32'))
+ predictor.run()
+ prediction = output_handle.copy_to_cpu()
+ prediction = paddle.to_tensor(prediction)
+ image_numpy = tensor2img(prediction[0], min_max)
+ save_image(
+ image_numpy,
+ os.path.join(args.output_path, "stylegan2/{}.png".format(i)))
+ metric_file = os.path.join(args.output_path, "stylegan2/metric.txt")
+ real_img = paddle.to_tensor(data['A'])
+ for metric in metrics.values():
+ metric.update(prediction, real_img)
+ elif model_type in ["basicvsr", "msvsr"]:
+ lq = data['lq'].numpy()
+ input_handles[0].copy_from_cpu(lq)
+ predictor.run()
+ if len(predictor.get_output_names()) > 1:
+ output_handle = predictor.get_output_handle(
+ predictor.get_output_names()[-1])
+ prediction = output_handle.copy_to_cpu()
+ prediction = paddle.to_tensor(prediction)
+ _, t, _, _, _ = prediction.shape
+
+ out_img = []
+ gt_img = []
+ for ti in range(t):
+ out_tensor = prediction[0, ti]
+ gt_tensor = data['gt'][0, ti]
+ out_img.append(tensor2img(out_tensor, (0., 1.)))
+ gt_img.append(tensor2img(gt_tensor, (0., 1.)))
+
+ image_numpy = tensor2img(prediction[0], min_max)
+ save_image(
+ image_numpy,
+ os.path.join(args.output_path, model_type, "{}.png".format(i)))
+
+ metric_file = os.path.join(args.output_path, model_type,
+ "metric.txt")
+ for metric in metrics.values():
+ metric.update(out_img, gt_img, is_seq=True)
+ elif model_type == "singan":
+ predictor.run()
+ prediction = output_handle.copy_to_cpu()
+ prediction = paddle.to_tensor(prediction)
+ image_numpy = tensor2img(prediction, min_max)
+ save_image(
+ image_numpy,
+ os.path.join(args.output_path, "singan/{}.png".format(i)))
+ metric_file = os.path.join(args.output_path, "singan/metric.txt")
+ for metric in metrics.values():
+ metric.update(prediction, data['A'])
+ elif model_type == 'gfpgan':
+ input_handles[0].copy_from_cpu(data['lq'].numpy())
+ predictor.run()
+ prediction = output_handle.copy_to_cpu()
+ prediction = paddle.to_tensor(prediction)
+ image_numpy = tensor2img(prediction, min_max)
+ save_image(
+ image_numpy,
+ os.path.join(args.output_path, "gfpgan/{}.png".format(i)))
+ elif model_type == "swinir":
+ lq = data[1].numpy()
+ _, _, h_old, w_old = lq.shape
+ window_size = 8
+ tile = 128
+ tile_overlap = 32
+ # after feed data to model, shape of feature map is change
+ h_pad = (h_old // window_size + 1) * window_size - h_old
+ w_pad = (w_old // window_size + 1) * window_size - w_old
+ lq = np.concatenate([lq, np.flip(lq, 2)],
+ axis=2)[:, :, :h_old + h_pad, :]
+ lq = np.concatenate([lq, np.flip(lq, 3)],
+ axis=3)[:, :, :, :w_old + w_pad]
+ lq = lq.astype("float32")
+
+ b, c, h, w = lq.shape
+ tile = min(tile, h, w)
+ assert tile % window_size == 0, "tile size should be a multiple of window_size"
+ sf = 1 # scale
+ stride = tile - tile_overlap
+ h_idx_list = list(range(0, h - tile, stride)) + [h - tile]
+ w_idx_list = list(range(0, w - tile, stride)) + [w - tile]
+ E = np.zeros([b, c, h * sf, w * sf], dtype=np.float32)
+ W = np.zeros_like(E)
+
+ for h_idx in h_idx_list:
+ for w_idx in w_idx_list:
+ in_patch = lq[..., h_idx:h_idx + tile, w_idx:w_idx + tile]
+ input_handles[0].copy_from_cpu(in_patch)
+ predictor.run()
+ out_patch = output_handle.copy_to_cpu()
+ out_patch_mask = np.ones_like(out_patch)
+
+ E[..., h_idx * sf:(h_idx + tile) * sf,
+ w_idx * sf:(w_idx + tile) * sf] += out_patch
+ W[..., h_idx * sf:(h_idx + tile) * sf,
+ w_idx * sf:(w_idx + tile) * sf] += out_patch_mask
+
+ output = np.true_divide(E, W)
+ prediction = output[..., :h_old * sf, :w_old * sf]
+
+ prediction = paddle.to_tensor(prediction)
+ target = tensor2img(data[0], (0., 1.))
+ prediction = tensor2img(prediction, (0., 1.))
+
+ metric_file = os.path.join(args.output_path, model_type,
+ "metric.txt")
+ for metric in metrics.values():
+ metric.update(prediction, target)
+
+ lq = tensor2img(data[1], (0., 1.))
+
+ sample_result = np.concatenate((lq, prediction, target), 1)
+ sample = cv2.cvtColor(sample_result, cv2.COLOR_RGB2BGR)
+ file_name = os.path.join(args.output_path, model_type,
+ "{}.png".format(i))
+ cv2.imwrite(file_name, sample)
+ elif model_type == "invdn":
+ noisy = data[0].numpy()
+ noise_channel = 3 * 4**(cfg.model.generator.down_num) - 3
+ input_handles[0].copy_from_cpu(noisy)
+ input_handles[1].copy_from_cpu(
+ np.random.randn(noisy.shape[0], noise_channel, noisy.shape[2],
+ noisy.shape[3]).astype(np.float32))
+ predictor.run()
+ output_handles = [
+ predictor.get_output_handle(name)
+ for name in predictor.get_output_names()
+ ]
+ prediction = output_handles[0].copy_to_cpu()
+ prediction = paddle.to_tensor(prediction[0])
+ image_numpy = tensor2img(prediction, min_max)
+ gt_numpy = tensor2img(data[1], min_max)
+ save_image(image_numpy,
+ os.path.join(args.output_path, "invdn/{}.png".format(i)))
+ metric_file = os.path.join(args.output_path, model_type,
+ "metric.txt")
+ for metric in metrics.values():
+ metric.update(image_numpy, gt_numpy)
+ break
+
+ elif model_type == "nafnet":
+ lq = data[1].numpy()
+ input_handles[0].copy_from_cpu(lq)
+ predictor.run()
+ prediction = output_handle.copy_to_cpu()
+ prediction = paddle.to_tensor(prediction)
+ target = tensor2img(data[0], (0., 1.))
+ prediction = tensor2img(prediction, (0., 1.))
+
+ metric_file = os.path.join(args.output_path, model_type,
+ "metric.txt")
+ for metric in metrics.values():
+ metric.update(prediction, target)
+
+ lq = tensor2img(data[1], (0., 1.))
+
+ sample_result = np.concatenate((lq, prediction, target), 1)
+ sample = cv2.cvtColor(sample_result, cv2.COLOR_RGB2BGR)
+ file_name = os.path.join(args.output_path, model_type,
+ "{}.png".format(i))
+ cv2.imwrite(file_name, sample)
+ elif model_type == 'aotgan':
+ input_data = paddle.concat((data['img'], data['mask']),
+ axis=1).numpy()
+ input_handles[0].copy_from_cpu(input_data)
+ predictor.run()
+ prediction = output_handle.copy_to_cpu()
+ prediction = paddle.to_tensor(prediction)
+ image_numpy = tensor2img(prediction, min_max)
+ save_image(
+ image_numpy,
+ os.path.join(args.output_path, "aotgan/{}.png".format(i)))
+
+ if metrics:
+ log_file = open(metric_file, 'a')
+ for metric_name, metric in metrics.items():
+ loss_string = "Metric {}: {:.4f}".format(metric_name,
+ metric.accumulate())
+ print(loss_string, file=log_file)
+ log_file.close()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/main.py b/tools/main.py
index 7d40c11c5b4b93ae9cd4678909efc8b4526dedde..b7e2b82607401d87fa6b2309528e776d2f0f2f92 100644
--- a/tools/main.py
+++ b/tools/main.py
@@ -51,6 +51,6 @@ def main(args, cfg):
if __name__ == '__main__':
args = parse_args()
- cfg = get_config(args.config_file)
+ cfg = get_config(args.config_file, args.opt)
main(args, cfg)
diff --git a/tools/styleclip_getf.py b/tools/styleclip_getf.py
new file mode 100644
index 0000000000000000000000000000000000000000..57767dc7e129cd23825ef9edd6aeff5f78231e50
--- /dev/null
+++ b/tools/styleclip_getf.py
@@ -0,0 +1,89 @@
+import argparse
+from tqdm import tqdm
+import paddle
+import numpy as np
+
+from ppgan.apps.styleganv2_predictor import StyleGANv2Predictor
+
+
+def concat_style_paddle(s_lst, n_layers):
+ result = [list() for _ in range(n_layers)]
+ assert n_layers == len(s_lst[0])
+ for i in range(n_layers):
+ for s_ in s_lst:
+ result[i].append(s_[i])
+ for i in range(n_layers):
+ result[i] = paddle.concat(result[i])
+ return result
+
+
+def to_np(s_lst):
+ for i in range(len(s_lst)):
+ s_lst[i] = s_lst[i].numpy()
+ return s_lst
+
+
+def concat_style_np(s_lst, n_layers):
+ result = [list() for _ in range(n_layers)]
+ assert n_layers == len(s_lst[0])
+ for i in range(n_layers):
+ for s_ in s_lst:
+ result[i].append(s_[i])
+ for i in range(n_layers):
+ result[i] = np.concatenate(result[i])
+ return result
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--dataset_name', type=str, default='ffhq-config-f')
+ parser.add_argument('--seed', type=int, default=1234)
+ args = parser.parse_args()
+
+ dataset_name = args.dataset_name
+ G = StyleGANv2Predictor(model_type=dataset_name).generator
+ w_idx_lst = G.w_idx_lst
+
+ with paddle.no_grad():
+ # get intermediate latent of 100000 samples
+ w_lst = list()
+ z = paddle.to_tensor(
+ np.random.RandomState(args.seed).randn(
+ 1000, 100, G.style_dim).astype('float32'))
+ #z = paddle.randn([1000, 100, G.style_dim])
+ for i in tqdm(range(1000)): # 100 * 1000 = 100000 # 1000
+ # apply truncation_psi=.7 truncation_cutoff=8
+ w_lst.append(
+ G.get_latents(z[i], truncation=0.7, truncation_cutoff=8))
+ #paddle.save(paddle.concat(w_lst[:20]), f'W-{dataset_name}.pdparams')
+
+ s_lst = []
+ # get style of first 2000 sample in W
+ for i in tqdm(range(20)): # 2*1000
+ s_ = G.style_affine(w_lst[i])
+ s_lst.append(s_)
+ paddle.save(concat_style_paddle(s_lst, len(w_idx_lst)),
+ f'S-{dataset_name}.pdparams')
+
+ for i in tqdm(range(20)): # 2*1000
+ s_lst[i] = to_np(s_lst[i])
+
+ # get std, mean of 100000 style samples
+ for i in tqdm(range(20, 1000)): # 100 * 1000
+ s_ = G.style_affine(w_lst[i])
+ s_lst.append(to_np(s_))
+ del w_lst, z, s_, G
+ s_lst = concat_style_np(s_lst, len(w_idx_lst))
+ s_mean = [
+ paddle.mean(paddle.to_tensor(s_lst[i]), axis=0)
+ for i in range(len(w_idx_lst))
+ ]
+ s_std = [
+ paddle.std(paddle.to_tensor(s_lst[i]), axis=0)
+ for i in range(len(w_idx_lst))
+ ]
+ paddle.save({
+ 'mean': s_mean,
+ 'std': s_std
+ }, f'stylegan2-{dataset_name}-styleclip-stats.pdparams')
+ print("Done.")
+
diff --git a/test_tipc/prepare.sh b/test_tipc/prepare.sh
new file mode 100644
index 0000000000000000000000000000000000000000..c43542c34d10e2a5a4697ce9140217af508afce0
--- /dev/null
+++ b/test_tipc/prepare.sh
@@ -0,0 +1,202 @@
+#!/bin/bash
+FILENAME=$1
+
+# MODE be one of ['lite_train_lite_infer' 'lite_train_whole_infer' 'whole_train_whole_infer',
+# 'whole_infer', 'benchmark_train', 'cpp_infer']
+
+MODE=$2
+
+dataline=$(cat ${FILENAME})
+
+# parser params
+IFS=$'\n'
+lines=(${dataline})
+function func_parser_key(){
+ strs=$1
+ IFS=":"
+ array=(${strs})
+ tmp=${array[0]}
+ echo ${tmp}
+}
+function func_parser_value(){
+ strs=$1
+ IFS=":"
+ array=(${strs})
+ tmp=${array[1]}
+ echo ${tmp}
+}
+IFS=$'\n'
+# The training params
+model_name=$(func_parser_value "${lines[1]}")
+trainer_list=$(func_parser_value "${lines[14]}")
+
+if [ ${MODE} = "benchmark_train" ];then
+ pip install -r requirements.txt
+ MODE="lite_train_lite_infer"
+fi
+
+if [ ${MODE} = "lite_train_lite_infer" ];then
+
+ case ${model_name} in
+ Pix2pix)
+ rm -rf ./data/pix2pix*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/pix2pix_facade_lite.tar --no-check-certificate
+ cd ./data/ && tar xf pix2pix_facade_lite.tar && cd ../ ;;
+ CycleGAN)
+ rm -rf ./data/cyclegan*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/cyclegan_horse2zebra_lite.tar --no-check-certificate
+ cd ./data/ && tar xf cyclegan_horse2zebra_lite.tar && cd ../ ;;
+ StyleGANv2)
+ rm -rf ./data/ffhq*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/ffhq_256.tar --no-check-certificate
+ cd ./data/ && tar xf ffhq_256.tar && cd ../ ;;
+ FOMM)
+ rm -rf ./data/fom_lite*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/fom_lite.tar --no-check-certificate --no-check-certificate
+ cd ./data/ && tar xf fom_lite.tar && cd ../ ;;
+ edvr|basicvsr|msvsr)
+ rm -rf ./data/reds*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/reds_lite.tar --no-check-certificate
+ cd ./data/ && tar xf reds_lite.tar && cd ../ ;;
+ esrgan)
+ rm -rf ./data/DIV2K*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/DIV2KandSet14paddle.tar --no-check-certificate
+ cd ./data/ && tar xf DIV2KandSet14paddle.tar && cd ../ ;;
+ swinir)
+ rm -rf ./data/*sets
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/swinir_data.zip --no-check-certificate
+ cd ./data/ && unzip -q swinir_data.zip && cd ../ ;;
+ invdn)
+ rm -rf ./data/SIDD_*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/SIDD_mini.zip --no-check-certificate
+ cd ./data/ && unzip -q SIDD_mini.zip && cd ../ ;;
+ nafnet)
+ rm -rf ./data/SIDD*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/SIDD_mini.zip --no-check-certificate
+ cd ./data/ && unzip -q SIDD_mini.zip && mkdir -p SIDD && mv ./SIDD_Medium_Srgb_Patches_512/* ./SIDD/ \
+ && mv ./SIDD_Valid_Srgb_Patches_256/* ./SIDD/ && mv ./SIDD/valid ./SIDD/val \
+ && mv ./SIDD/train/GT ./SIDD/train/target && mv ./SIDD/train/Noisy ./SIDD/train/input \
+ && mv ./SIDD/val/Noisy ./SIDD/val/input && mv ./SIDD/val/GT ./SIDD/val/target && cd ../ ;;
+ singan)
+ rm -rf ./data/singan*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/singan-official_images.zip --no-check-certificate
+ cd ./data/ && unzip -q singan-official_images.zip && cd ../
+ mkdir -p ./data/singan
+ mv ./data/SinGAN-official_images/Images/stone.png ./data/singan ;;
+ GFPGAN)
+ rm -rf ./data/gfpgan*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/gfpgan_tipc_data.zip --no-check-certificate
+ mkdir -p ./data/gfpgan_data
+ cd ./data/ && unzip -q gfpgan_tipc_data.zip -d gfpgan_data/ && cd ../ ;;
+ aotgan)
+ rm -rf ./data/aotgan*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/aotgan.zip --no-check-certificate
+ cd ./data/ && unzip -q aotgan.zip && cd ../ ;;
+ esac
+elif [ ${MODE} = "whole_train_whole_infer" ];then
+ if [ ${model_name} == "Pix2pix" ]; then
+ rm -rf ./data/facades*
+ wget -nc -P ./data/ http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/facades.tar.gz --no-check-certificate
+ cd ./data/ && tar -xzf facades.tar.gz && cd ../
+ elif [ ${model_name} == "CycleGAN" ]; then
+ rm -rf ./data/horse2zebra*
+ wget -nc -P ./data/ https://people.eecs.berkeley.edu/~taesung_park/CycleGAN/datasets/horse2zebra.zip --no-check-certificate
+ cd ./data/ && unzip horse2zebra.zip && cd ../
+ elif [ ${model_name} == "singan" ]; then
+ rm -rf ./data/singan*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/singan-official_images.zip --no-check-certificate
+ cd ./data/ && unzip -q singan-official_images.zip && cd ../
+ mkdir -p ./data/singan
+ mv ./data/SinGAN-official_images/Images/stone.png ./data/singan
+ fi
+elif [ ${MODE} = "lite_train_whole_infer" ];then
+ if [ ${model_name} == "Pix2pix" ]; then
+ rm -rf ./data/facades*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/pix2pix_facade_lite.tar --no-check-certificate
+ cd ./data/ && tar xf pix2pix_facade_lite.tar && cd ../
+ elif [ ${model_name} == "CycleGAN" ]; then
+ rm -rf ./data/horse2zebra*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/cyclegan_horse2zebra_lite.tar --no-check-certificate --no-check-certificate
+ cd ./data/ && tar xf cyclegan_horse2zebra_lite.tar && cd ../
+ elif [ ${model_name} == "FOMM" ]; then
+ rm -rf ./data/first_order*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/fom_lite.tar --no-check-certificate --no-check-certificate
+ cd ./data/ && tar xf fom_lite.tar && cd ../
+ elif [ ${model_name} == "StyleGANv2" ]; then
+ rm -rf ./data/ffhq*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/ffhq_256.tar --no-check-certificate
+ cd ./data/ && tar xf ffhq_256.tar && cd ../
+ elif [ ${model_name} == "basicvsr" ]; then
+ rm -rf ./data/reds*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/reds_lite.tar --no-check-certificate
+ cd ./data/ && tar xf reds_lite.tar && cd ../
+ elif [ ${model_name} == "msvsr" ]; then
+ rm -rf ./data/reds*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/reds_lite.tar --no-check-certificate
+ cd ./data/ && tar xf reds_lite.tar && cd ../
+ elif [ ${model_name} == "singan" ]; then
+ rm -rf ./data/singan*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/singan-official_images.zip --no-check-certificate
+ cd ./data/ && unzip -q singan-official_images.zip && cd ../
+ mkdir -p ./data/singan
+ mv ./data/SinGAN-official_images/Images/stone.png ./data/singan
+ fi
+elif [ ${MODE} = "whole_infer" ];then
+ if [ ${model_name} = "Pix2pix" ]; then
+ rm -rf ./data/facades*
+ rm -rf ./inference/pix2pix*
+ wget -nc -P ./inference https://paddlegan.bj.bcebos.com/static_model/pix2pix_facade.tar --no-check-certificate
+ wget -nc -P ./data https://paddlegan.bj.bcebos.com/datasets/facades_test.tar --no-check-certificate
+ cd ./data && tar xf facades_test.tar && mv facades_test facades && cd ../
+ cd ./inference && tar xf pix2pix_facade.tar && cd ../
+ elif [ ${model_name} = "CycleGAN" ]; then
+ rm -rf ./data/cyclegan*
+ rm -rf ./inference/cyclegan*
+ wget -nc -P ./inference https://paddlegan.bj.bcebos.com/static_model/cyclegan_horse2zebra.tar --no-check-certificate
+ wget -nc -P ./data https://paddlegan.bj.bcebos.com/datasets/cyclegan_horse2zebra_test.tar --no-check-certificate
+ cd ./data && tar xf cyclegan_horse2zebra_test.tar && mv cyclegan_test horse2zebra && cd ../
+ cd ./inference && tar xf cyclegan_horse2zebra.tar && cd ../
+ elif [ ${model_name} == "FOMM" ]; then
+ rm -rf ./data/first_order*
+ rm -rf ./inference/fom_dy2st*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/fom_lite_test.tar --no-check-certificate
+ wget -nc -P ./inference https://paddlegan.bj.bcebos.com/static_model/fom_dy2st.tar --no-check-certificate
+ cd ./data/ && tar xf fom_lite_test.tar && cd ../
+ cd ./inference && tar xf fom_dy2st.tar && cd ../
+ elif [ ${model_name} == "StyleGANv2" ]; then
+ rm -rf ./data/ffhq*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/ffhq_256.tar --no-check-certificate
+ wget -nc -P ./inference https://paddlegan.bj.bcebos.com/static_model/stylegan2_1024.tar --no-check-certificate
+ cd ./inference && tar xf stylegan2_1024.tar && cd ../
+ cd ./data/ && tar xf ffhq_256.tar && cd ../
+ elif [ ${model_name} == "basicvsr" ]; then
+ rm -rf ./data/reds*
+ rm -rf ./inference/basic*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/reds_lite.tar --no-check-certificate
+ wget -nc -P ./inference https://paddlegan.bj.bcebos.com/static_model/basicvsr.tar --no-check-certificate
+ cd ./inference && tar xf basicvsr.tar && cd ../
+ cd ./data/ && tar xf reds_lite.tar && cd ../
+ elif [ ${model_name} == "msvsr" ]; then
+ rm -rf ./data/reds*
+ rm -rf ./inference/msvsr*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/reds_lite.tar --no-check-certificate
+ wget -nc -P ./inference https://paddlegan.bj.bcebos.com/static_model/msvsr.tar --no-check-certificate
+ cd ./inference && tar xf msvsr.tar && cd ../
+ cd ./data/ && tar xf reds_lite.tar && cd ../
+ elif [ ${model_name} == "singan" ]; then
+ rm -rf ./data/singan*
+ wget -nc -P ./data/ https://paddlegan.bj.bcebos.com/datasets/singan-official_images.zip --no-check-certificate
+ wget -nc -P ./inference https://paddlegan.bj.bcebos.com/datasets/singan.zip --no-check-certificate
+ cd ./data/ && unzip -q singan-official_images.zip && cd ../
+ cd ./inference/ && unzip -q singan.zip && cd ../
+ mkdir -p ./data/singan
+ mv ./data/SinGAN-official_images/Images/stone.png ./data/singan
+ fi
+elif [ ${MODE} = "cpp_infer" ]; then
+ if [ ${model_name} == "msvsr" ]; then
+ rm -rf ./inference/msvsr*
+ wget -nc -P ./inference https://paddlegan.bj.bcebos.com/static_model/msvsr.tar --no-check-certificate
+ cd ./inference && tar xf msvsr.tar && cd ../
+ wget -nc -P ./data https://paddlegan.bj.bcebos.com/datasets/low_res.mp4 --no-check-certificate
+ fi
+fi
diff --git a/test_tipc/results/python_basicvsr_results_fp32.txt b/test_tipc/results/python_basicvsr_results_fp32.txt
new file mode 100644
index 0000000000000000000000000000000000000000..1f0df64217ef2a8454c914a5398bc2f5279e7c7f
--- /dev/null
+++ b/test_tipc/results/python_basicvsr_results_fp32.txt
@@ -0,0 +1,2 @@
+Metric psnr: 27.0864
+Metric ssim: 0.7835
diff --git a/test_tipc/results/python_cyclegan_results_fp32.txt b/test_tipc/results/python_cyclegan_results_fp32.txt
new file mode 100644
index 0000000000000000000000000000000000000000..beffc319e03dee64c28d333f777e12ff4209b7fa
--- /dev/null
+++ b/test_tipc/results/python_cyclegan_results_fp32.txt
@@ -0,0 +1 @@
+Metric fid: 67.9814
diff --git a/test_tipc/results/python_fom_results_fp32.txt b/test_tipc/results/python_fom_results_fp32.txt
new file mode 100644
index 0000000000000000000000000000000000000000..8515822f73d267204eef9f89c9bd51d372c32b56
--- /dev/null
+++ b/test_tipc/results/python_fom_results_fp32.txt
@@ -0,0 +1 @@
+Metric l1 loss: 0.1210
diff --git a/test_tipc/results/python_msvsr_results_fp32.txt b/test_tipc/results/python_msvsr_results_fp32.txt
new file mode 100644
index 0000000000000000000000000000000000000000..01b8907f04d574feeda65c0e8e6c11c1e5cb2fd6
--- /dev/null
+++ b/test_tipc/results/python_msvsr_results_fp32.txt
@@ -0,0 +1,3 @@
+Metric psnr: 23.6020
+Metric ssim: 0.5636
+
diff --git a/test_tipc/results/python_pix2pix_results_fp32.txt b/test_tipc/results/python_pix2pix_results_fp32.txt
new file mode 100644
index 0000000000000000000000000000000000000000..4950de48cdae119a71628a37cbcad4e5e8db9ba8
--- /dev/null
+++ b/test_tipc/results/python_pix2pix_results_fp32.txt
@@ -0,0 +1 @@
+Metric fid: 139.3846
diff --git a/test_tipc/results/python_singan_results_fp32.txt b/test_tipc/results/python_singan_results_fp32.txt
new file mode 100644
index 0000000000000000000000000000000000000000..575aabd0cec4551b638ee62f66b87d0d8a8fef5c
--- /dev/null
+++ b/test_tipc/results/python_singan_results_fp32.txt
@@ -0,0 +1 @@
+Metric fid: 124.0369
diff --git a/test_tipc/results/python_stylegan2_results_fp32.txt b/test_tipc/results/python_stylegan2_results_fp32.txt
new file mode 100644
index 0000000000000000000000000000000000000000..3b384beb7205595a16e380ed2acffb7fd0e591ee
--- /dev/null
+++ b/test_tipc/results/python_stylegan2_results_fp32.txt
@@ -0,0 +1 @@
+Metric fid: 153.9647
diff --git a/test_tipc/test_inference_cpp.sh b/test_tipc/test_inference_cpp.sh
new file mode 100644
index 0000000000000000000000000000000000000000..c5f533c9ade38e3e419fa1e69e8e23b4c1cb1f4a
--- /dev/null
+++ b/test_tipc/test_inference_cpp.sh
@@ -0,0 +1,141 @@
+#!/bin/bash
+source test_tipc/common_func.sh
+
+FILENAME=$1
+MODE=$2
+dataline=$(awk 'NR==1, NR==18{print}' $FILENAME)
+
+# parser params
+IFS=$'\n'
+lines=(${dataline})
+
+# parser cpp inference params
+model_name=$(func_parser_value "${lines[1]}")
+infer_cmd=$(func_parser_value "${lines[2]}")
+model_path=$(func_parser_value "${lines[3]}")
+param_path=$(func_parser_value "${lines[4]}")
+video_path=$(func_parser_value "${lines[5]}")
+output_dir=$(func_parser_value "${lines[6]}")
+frame_num=$(func_parser_value "${lines[7]}")
+device=$(func_parser_value "${lines[8]}")
+gpu_id=$(func_parser_value "${lines[9]}")
+use_mkldnn=$(func_parser_value "${lines[10]}")
+cpu_threads=$(func_parser_value "${lines[11]}")
+
+# only support fp32、bs=1, trt is not supported yet.
+precision="fp32"
+use_trt=false
+batch_size=1
+
+LOG_PATH="./test_tipc/output/${model_name}/${MODE}"
+mkdir -p ${LOG_PATH}
+status_log="${LOG_PATH}/results_cpp.log"
+
+function func_cpp_inference(){
+ # set log
+ if [ ${device} = "GPU" ]; then
+ _save_log_path="${LOG_PATH}/cpp_infer_gpu_usetrt_${use_trt}_precision_${precision}_batchsize_${batch_size}.log"
+ elif [ ${device} = "CPU" ]; then
+ _save_log_path="${LOG_PATH}/cpp_infer_cpu_usemkldnn_${use_mkldnn}_threads_${cpu_threads}_precision_${precision}_batchsize_${batch_size}.log"
+ fi
+
+ # set params
+ set_model_path=$(func_set_params "--model_path" "${model_path}")
+ set_param_path=$(func_set_params "--param_path" "${param_path}")
+ set_video_path=$(func_set_params "--video_path" "${video_path}")
+ set_output_dir=$(func_set_params "--output_dir" "${output_dir}")
+ set_frame_num=$(func_set_params "--frame_num" "${frame_num}")
+ set_device=$(func_set_params "--device" "${device}")
+ set_gpu_id=$(func_set_params "--gpu_id" "${gpu_id}")
+ set_use_mkldnn=$(func_set_params "--use_mkldnn" "${use_mkldnn}")
+ set_cpu_threads=$(func_set_params "--cpu_threads" "${cpu_threads}")
+
+ # run infer
+ cmd="${infer_cmd} ${set_model_path} ${set_param_path} ${set_video_path} ${set_output_dir} ${set_frame_num} ${set_device} ${set_gpu_id} ${set_use_mkldnn} ${set_cpu_threads} > ${_save_log_path} 2>&1"
+ eval $cmd
+ last_status=${PIPESTATUS[0]}
+ status_check $last_status "${cmd}" "${status_log}" "${model_name}"
+}
+
+cd deploy/cpp_infer
+if [ -d "opencv-3.4.7/opencv3/" ] && [ $(md5sum opencv-3.4.7.tar.gz | awk -F ' ' '{print $1}') = "faa2b5950f8bee3f03118e600c74746a" ];then
+ echo "################### build opencv skipped ###################"
+else
+ echo "################### building opencv ###################"
+ rm -rf opencv-3.4.7.tar.gz opencv-3.4.7/
+ wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/test/opencv-3.4.7.tar.gz
+ tar -xf opencv-3.4.7.tar.gz
+
+ cd opencv-3.4.7/
+ install_path=$(pwd)/opencv3
+
+ rm -rf build
+ mkdir build
+ cd build
+
+ cmake .. \
+ -DCMAKE_INSTALL_PREFIX=${install_path} \
+ -DCMAKE_BUILD_TYPE=Release \
+ -DBUILD_SHARED_LIBS=OFF \
+ -DWITH_IPP=OFF \
+ -DBUILD_IPP_IW=OFF \
+ -DWITH_LAPACK=OFF \
+ -DWITH_EIGEN=OFF \
+ -DCMAKE_INSTALL_LIBDIR=lib64 \
+ -DWITH_ZLIB=ON \
+ -DBUILD_ZLIB=ON \
+ -DWITH_JPEG=ON \
+ -DBUILD_JPEG=ON \
+ -DWITH_PNG=ON \
+ -DBUILD_PNG=ON \
+ -DWITH_TIFF=ON \
+ -DBUILD_TIFF=ON \
+ -DWITH_FFMPEG=ON
+
+ make -j
+ make install
+ cd ../../
+ echo "################### building opencv finished ###################"
+fi
+
+if [ -d "paddle_inference" ]; then
+ echo "################### download inference lib skipped ###################"
+else
+ echo "################### downloading inference lib ###################"
+ wget -nc https://paddle-inference-lib.bj.bcebos.com/2.3.1/cxx_c/Linux/GPU/x86-64_gcc8.2_avx_mkl_cuda10.1_cudnn7.6.5_trt6.0.1.5/paddle_inference.tgz
+ tar -xf paddle_inference.tgz
+ echo "################### downloading inference lib finished ###################"
+fi
+
+echo "################### building PaddleGAN demo ####################"
+OPENCV_DIR=$(pwd)/opencv-3.4.7/opencv3
+LIB_DIR=$(pwd)/paddle_inference
+CUDA_LIB_DIR=$(dirname `find /usr -name libcudart.so`)
+CUDNN_LIB_DIR=$(dirname `find /usr -name libcudnn.so`)
+TENSORRT_DIR=''
+
+export LD_LIBRARY_PATH=$(dirname `find ${PWD} -name libonnxruntime.so.1.11.1`):"$LD_LIBRARY_PATH"
+export LD_LIBRARY_PATH=$(dirname `find ${PWD} -name libpaddle2onnx.so.0.9.9`):"$LD_LIBRARY_PATH"
+
+BUILD_DIR=build
+rm -rf ${BUILD_DIR}
+mkdir ${BUILD_DIR}
+cd ${BUILD_DIR}
+cmake .. \
+ -DPADDLE_LIB=${LIB_DIR} \
+ -DWITH_MKL=ON \
+ -DWITH_GPU=ON \
+ -DWITH_STATIC_LIB=OFF \
+ -DWITH_TENSORRT=OFF \
+ -DOPENCV_DIR=${OPENCV_DIR} \
+ -DCUDNN_LIB=${CUDNN_LIB_DIR} \
+ -DCUDA_LIB=${CUDA_LIB_DIR} \
+ -DTENSORRT_DIR=${TENSORRT_DIR}
+
+make -j
+cd ../
+echo "################### building PaddleGAN demo finished ###################"
+
+echo "################### running test ###################"
+cd ../../
+func_cpp_inference
diff --git a/test_tipc/test_train_inference_python.sh b/test_tipc/test_train_inference_python.sh
new file mode 100644
index 0000000000000000000000000000000000000000..c11e9b9a22d43628fad832e68f18beff9803516e
--- /dev/null
+++ b/test_tipc/test_train_inference_python.sh
@@ -0,0 +1,306 @@
+#!/bin/bash
+source test_tipc/common_func.sh
+
+FILENAME=$1
+# MODE be one of ['lite_train_lite_infer' 'lite_train_whole_infer' 'whole_train_whole_infer', 'whole_infer']
+MODE=$2
+
+dataline=$(awk 'NR==1, NR==51{print}' $FILENAME)
+
+# parser params
+IFS=$'\n'
+lines=(${dataline})
+# The training params
+model_name=$(func_parser_value "${lines[1]}")
+python=$(func_parser_value "${lines[2]}")
+gpu_list=$(func_parser_value "${lines[3]}")
+
+autocast_list=$(func_parser_value "${lines[5]}")
+epoch_key=$(func_parser_key "${lines[6]}")
+epoch_num=$(func_parser_params "${lines[6]}")
+save_model_key=$(func_parser_key "${lines[7]}")
+train_batch_key=$(func_parser_key "${lines[8]}")
+train_batch_value=$(func_parser_params "${lines[8]}")
+pretrain_model_key=$(func_parser_key "${lines[9]}")
+pretrain_model_value=$(func_parser_value "${lines[9]}")
+train_model_name=$(func_parser_value "${lines[10]}")
+train_infer_img_dir=$(func_parser_value "${lines[11]}")
+train_param_key1=$(func_parser_key "${lines[12]}")
+train_param_value1=$(func_parser_value "${lines[12]}")
+
+trainer_list=$(func_parser_value "${lines[14]}")
+
+trainer_norm=$(func_parser_key "${lines[15]}")
+norm_trainer=$(func_parser_value "${lines[15]}")
+
+to_static_key=$(func_parser_key "${lines[19]}")
+to_static_trainer=$(func_parser_value "${lines[19]}")
+trainer_key2=$(func_parser_key "${lines[20]}")
+trainer_value2=$(func_parser_value "${lines[20]}")
+
+eval_py=$(func_parser_value "${lines[23]}")
+eval_key1=$(func_parser_key "${lines[24]}")
+eval_value1=$(func_parser_value "${lines[24]}")
+
+save_infer_key=$(func_parser_key "${lines[27]}")
+export_weight=$(func_parser_value "${lines[28]}")
+norm_export=$(func_parser_value "${lines[29]}")
+
+inference_dir=$(func_parser_value "${lines[35]}")
+
+# parser inference model
+infer_model_dir_list=$(func_parser_value "${lines[36]}")
+infer_export_list=$(func_parser_value "${lines[37]}")
+infer_is_quant=$(func_parser_value "${lines[38]}")
+# parser inference
+inference_py=$(func_parser_value "${lines[39]}")
+use_gpu_key=$(func_parser_key "${lines[40]}")
+use_gpu_list=$(func_parser_value "${lines[40]}")
+use_mkldnn_key=$(func_parser_key "${lines[41]}")
+use_mkldnn_list=$(func_parser_value "${lines[41]}")
+cpu_threads_key=$(func_parser_key "${lines[42]}")
+cpu_threads_list=$(func_parser_value "${lines[42]}")
+batch_size_key=$(func_parser_key "${lines[43]}")
+batch_size_list=$(func_parser_value "${lines[43]}")
+use_trt_key=$(func_parser_key "${lines[44]}")
+use_trt_list=$(func_parser_value "${lines[44]}")
+precision_key=$(func_parser_key "${lines[45]}")
+precision_list=$(func_parser_value "${lines[45]}")
+infer_model_key=$(func_parser_key "${lines[46]}")
+image_dir_key=$(func_parser_key "${lines[47]}")
+infer_img_dir=$(func_parser_value "${lines[47]}")
+save_log_key=$(func_parser_key "${lines[48]}")
+infer_key1=$(func_parser_key "${lines[50]}")
+infer_value1=$(func_parser_value "${lines[50]}")
+
+LOG_PATH="./test_tipc/output/${model_name}/${MODE}"
+mkdir -p ${LOG_PATH}
+status_log="${LOG_PATH}/results_python.log"
+
+function func_inference(){
+ IFS='|'
+ _python=$1
+ _script=$2
+ _model_dir=$3
+ _log_path=$4
+ _img_dir=$5
+ _flag_quant=$6
+ # inference
+ for use_gpu in ${use_gpu_list[*]}; do
+ if [ ${use_gpu} = "False" ] || [ ${use_gpu} = "cpu" ]; then
+ for use_mkldnn in ${use_mkldnn_list[*]}; do
+ if [ ${use_mkldnn} = "False" ] && [ ${_flag_quant} = "True" ]; then
+ continue
+ fi
+ for threads in ${cpu_threads_list[*]}; do
+ for batch_size in ${batch_size_list[*]}; do
+ for precision in ${precision_list[*]}; do
+ set_precision=$(func_set_params "${precision_key}" "${precision}")
+
+ _save_log_path="${_log_path}/python_infer_cpu_usemkldnn_${use_mkldnn}_threads_${threads}_precision_${precision}_batchsize_${batch_size}.log"
+ set_infer_data=$(func_set_params "${image_dir_key}" "${_img_dir}")
+ set_benchmark=$(func_set_params "${benchmark_key}" "${benchmark_value}")
+ set_batchsize=$(func_set_params "${batch_size_key}" "${batch_size}")
+ set_cpu_threads=$(func_set_params "${cpu_threads_key}" "${threads}")
+ set_model_dir=$(func_set_params "${infer_model_key}" "${_model_dir}")
+ set_infer_params1=$(func_set_params "${infer_key1}" "${infer_value1}")
+ command="${_python} ${_script} ${use_gpu_key}=${use_gpu} ${set_model_dir} > ${_save_log_path} 2>&1 "
+ eval $command
+ last_status=${PIPESTATUS[0]}
+ eval "cat ${_save_log_path}"
+ status_check $last_status "${command}" "${status_log}" "${model_name}" "${_save_log_path}"
+ done
+ done
+ done
+ done
+ elif [ ${use_gpu} = "True" ] || [ ${use_gpu} = "gpu" ]; then
+ for use_trt in ${use_trt_list[*]}; do
+ for precision in ${precision_list[*]}; do
+ if [[ ${_flag_quant} = "False" ]] && [[ ${precision} =~ "int8" ]]; then
+ continue
+ fi
+ if [[ ${precision} =~ "fp16" || ${precision} =~ "int8" ]] && [ ${use_trt} = "False" ]; then
+ continue
+ fi
+ if [[ ${use_trt} = "False" || ${precision} =~ "int8" ]] && [ ${_flag_quant} = "True" ]; then
+ continue
+ fi
+ for batch_size in ${batch_size_list[*]}; do
+ _save_log_path="${_log_path}/python_infer_gpu_usetrt_${use_trt}_precision_${precision}_batchsize_${batch_size}.log"
+ set_infer_data=$(func_set_params "${image_dir_key}" "${_img_dir}")
+ set_benchmark=$(func_set_params "${benchmark_key}" "${benchmark_value}")
+ set_batchsize=$(func_set_params "${batch_size_key}" "${batch_size}")
+ set_tensorrt=$(func_set_params "${use_trt_key}" "${use_trt}")
+ set_precision=$(func_set_params "${precision_key}" "${precision}")
+ set_model_dir=$(func_set_params "${infer_model_key}" "${_model_dir}")
+ set_infer_params1=$(func_set_params "${infer_key1}" "${infer_value1}")
+ command="${_python} ${_script} ${use_gpu_key}=${use_gpu} ${set_tensorrt} ${set_precision} ${set_model_dir} ${set_batchsize} ${set_infer_data} ${set_benchmark} ${set_infer_params1} > ${_save_log_path} 2>&1 "
+ eval $command
+ last_status=${PIPESTATUS[0]}
+ eval "cat ${_save_log_path}"
+ status_check $last_status "${command}" "${status_log}" "${model_name}" "${_save_log_path}"
+
+ done
+ done
+ done
+ else
+ echo "Does not support hardware other than CPU and GPU Currently!"
+ fi
+ done
+}
+
+if [ ${MODE} = "whole_infer" ]; then
+ GPUID=$3
+ if [ ${#GPUID} -le 0 ];then
+ env=" "
+ else
+ env="export CUDA_VISIBLE_DEVICES=${GPUID}"
+ fi
+ # set CUDA_VISIBLE_DEVICES
+ eval $env
+ export Count=0
+ IFS="|"
+ infer_run_exports=(${infer_export_list})
+ infer_quant_flag=(${infer_is_quant})
+ for infer_model in ${infer_model_dir_list[*]}; do
+ # run export
+ if [ ${infer_run_exports[Count]} != "null" ];then
+ save_infer_dir=$(dirname $infer_model)
+ set_export_weight=$(func_set_params "${export_weight}" "${infer_model}")
+ set_save_infer_key="${save_infer_key} ${save_infer_dir}"
+ export_log_path="${LOG_PATH}_export_${Count}.log"
+ export_cmd="${python} ${infer_run_exports[Count]} ${set_export_weight} ${set_save_infer_key} > ${export_log_path} 2>&1"
+ echo ${infer_run_exports[Count]}
+ echo $export_cmd
+ eval $export_cmd
+ status_export=$?
+ status_check $status_export "${export_cmd}" "${status_log}" "${model_name}" "${export_log_path}"
+ else
+ save_infer_dir=${infer_model}
+ fi
+ #run inference
+ func_inference "${python}" "${inference_py}" "${save_infer_dir}" "${LOG_PATH}" "${infer_img_dir}"
+ Count=$(($Count + 1))
+ done
+else
+ IFS="|"
+ export Count=0
+ USE_GPU_KEY=(${train_use_gpu_value})
+ for gpu in ${gpu_list[*]}; do
+ train_use_gpu=${USE_GPU_KEY[Count]}
+ Count=$(($Count + 1))
+ ips=""
+ if [ ${gpu} = "-1" ];then
+ env=""
+ elif [ ${#gpu} -le 1 ];then
+ env="export CUDA_VISIBLE_DEVICES=${gpu}"
+ eval ${env}
+ elif [ ${#gpu} -le 15 ];then
+ IFS=","
+ array=(${gpu})
+ env="export CUDA_VISIBLE_DEVICES=${gpu}"
+ IFS="|"
+ else
+ IFS=";"
+ array=(${gpu})
+ ips=${array[0]}
+ gpu=${array[1]}
+ IFS="|"
+ env=" "
+ fi
+ for autocast in ${autocast_list[*]}; do
+ if [ ${autocast} = "fp16" ]; then
+ set_amp_config="--amp"
+ set_amp_level="--amp_level=O2"
+ else
+ set_amp_config=" "
+ set_amp_level=" "
+ fi
+ for trainer in ${trainer_list[*]}; do
+ flag_quant=False
+ # In case of @to_static, we re-used norm_traier,
+ # but append "-o Global.to_static=True" for config
+ # to trigger "apply_to_static" logic in 'engine.py'
+ if [ ${trainer} = "${to_static_key}" ]; then
+ run_train="${norm_trainer} ${to_static_trainer}"
+ run_export=${norm_export}
+ else
+ run_train=${norm_trainer}
+ run_export=${norm_export}
+ fi
+
+ if [ ${run_train} = "null" ]; then
+ continue
+ fi
+ set_autocast=$(func_set_params "${autocast_key}" "${autocast}")
+ set_epoch=$(func_set_params "${epoch_key}" "${epoch_num}")
+ set_pretrain=$(func_set_params "${pretrain_model_key}" "${pretrain_model_value}")
+ set_batchsize=$(func_set_params "${train_batch_key}" "${train_batch_value}")
+ set_train_params1=$(func_set_params "${train_param_key1}" "${train_param_value1}")
+ set_use_gpu=$(func_set_params "${train_use_gpu_key}" "${train_use_gpu}")
+ if [ ${#ips} -le 26 ];then
+ save_log="${LOG_PATH}/${trainer}_gpus_${gpu}_autocast_${autocast}"
+ nodes=1
+ else
+ IFS=","
+ ips_array=(${ips})
+ IFS="|"
+ nodes=${#ips_array[@]}
+ save_log="${LOG_PATH}/${trainer}_gpus_${gpu}_autocast_${autocast}_nodes_${nodes}"
+ fi
+ set_save_model=$(func_set_params "${save_model_key}" "${save_log}")
+ if [ ${#gpu} -le 2 ];then # train with cpu or single gpu
+ cmd="${python} ${run_train} ${set_use_gpu} ${set_save_model} ${set_train_params1} ${set_epoch} ${set_pretrain} ${set_batchsize} ${set_amp_config} ${set_amp_level}"
+ elif [ ${#ips} -le 26 ];then # train with multi-gpu
+ cmd="${python} -m paddle.distributed.launch --gpus=${gpu} ${run_train} ${set_use_gpu} ${set_save_model} ${set_train_params1} ${set_epoch} ${set_pretrain} ${set_batchsize} ${set_amp_config} ${set_amp_level}"
+ else # train with multi-machine
+ cmd="${python} -m paddle.distributed.launch --ips=${ips} --gpus=${gpu} ${run_train} ${set_use_gpu} ${set_save_model} ${set_train_params1} ${set_pretrain} ${set_epoch} ${set_batchsize} ${set_amp_config} ${set_amp_level}"
+ fi
+ # run train
+ export FLAGS_cudnn_deterministic=True
+ eval $cmd
+ echo $cmd
+ log_name=${train_model_name/checkpoint.pdparams/.txt}
+ train_log_path=$( echo "${save_log}/${log_name}")
+ eval "cat ${train_log_path} >> ${save_log}.log"
+ status_check $? "${cmd}" "${status_log}" "${model_name}" "${save_log}.log"
+
+ set_eval_pretrain=$(func_set_params "${pretrain_model_key}" "${save_log}/${train_model_name}")
+ # save norm trained models to set pretrain for pact training and fpgm training
+
+ # run eval
+ if [ ${eval_py} != "null" ]; then
+ set_eval_params1=$(func_set_params "${eval_key1}" "${eval_value1}")
+ eval_log_path="${LOG_PATH}/${trainer}_gpus_${gpu}_autocast_${autocast}_nodes_${nodes}_eval.log"
+ eval_cmd="${python} ${eval_py} ${set_eval_pretrain} ${set_use_gpu} ${set_eval_params1} > ${eval_log_path} 2>&1"
+ eval $eval_cmd
+ status_check $? "${eval_cmd}" "${status_log}" "${model_name}" "${eval_log_path}"
+ fi
+ # run export model
+ if [ ${run_export} != "null" ]; then
+ # run export model
+ save_infer_path="${save_log}"
+ set_export_weight="${save_log}/${train_model_name}"
+ set_export_weight_path=$( echo ${set_export_weight})
+ set_save_infer_key="${save_infer_key} ${save_infer_path}"
+ export_log_path="${LOG_PATH}/${trainer}_gpus_${gpu}_autocast_${autocast}_nodes_${nodes}_export.log"
+ export_cmd="${python} ${run_export} ${set_export_weight_path} ${set_save_infer_key} > ${export_log_path} 2>&1"
+ eval "$export_cmd"
+ status_check $? "${export_cmd}" "${status_log}" "${model_name}" "${export_log_path}"
+
+ #run inference
+ eval $env
+ save_infer_path="${save_log}"
+ if [ ${inference_dir} != "null" ] && [ ${inference_dir} != '##' ]; then
+ infer_model_dir="${save_infer_path}/${inference_dir}"
+ else
+ infer_model_dir=${save_infer_path}
+ fi
+ func_inference "${python}" "${inference_py}" "${infer_model_dir}" "${LOG_PATH}" "${train_infer_img_dir}" "${flag_quant}"
+
+ eval "unset CUDA_VISIBLE_DEVICES"
+ fi
+ done # done with: for trainer in ${trainer_list[*]}; do
+ done # done with: for autocast in ${autocast_list[*]}; do
+ done # done with: for gpu in ${gpu_list[*]}; do
+fi # end if [ ${MODE} = "infer" ]; then
diff --git a/test_tipc/test_train_inference_python_npu.sh b/test_tipc/test_train_inference_python_npu.sh
new file mode 100644
index 0000000000000000000000000000000000000000..a1e597236c490770ea6282c319c526d2543d1542
--- /dev/null
+++ b/test_tipc/test_train_inference_python_npu.sh
@@ -0,0 +1,38 @@
+#!/bin/bash
+source test_tipc/common_func.sh
+
+function readlinkf() {
+ perl -MCwd -e 'print Cwd::abs_path shift' "$1";
+}
+
+function func_parser_config() {
+ strs=$1
+ IFS=" "
+ array=(${strs})
+ tmp=${array[2]}
+ echo ${tmp}
+}
+
+BASEDIR=$(dirname "$0")
+REPO_ROOT_PATH=$(readlinkf ${BASEDIR}/../)
+
+FILENAME=$1
+
+# change gpu to npu in tipc txt configs
+sed -i "s/state=GPU/state=NPU/g" $FILENAME
+sed -i "s/--device:gpu/--device:npu/g" $FILENAME
+sed -i "s/--benchmark:True/--benchmark:False/g" $FILENAME
+dataline=`cat $FILENAME`
+
+# change gpu to npu in execution script
+sed -i 's/\"gpu\"/\"npu\"/g' test_tipc/test_train_inference_python.sh
+sed -i 's/--gpus/--npus/g' test_tipc/test_train_inference_python.sh
+
+# parser params
+IFS=$'\n'
+lines=(${dataline})
+
+# pass parameters to test_train_inference_python.sh
+cmd="bash test_tipc/test_train_inference_python.sh ${FILENAME} $2"
+echo $cmd
+eval $cmd
diff --git a/test_tipc/test_train_inference_python_xpu.sh b/test_tipc/test_train_inference_python_xpu.sh
new file mode 100644
index 0000000000000000000000000000000000000000..78dd55683efb4c3916e104f6a81cfc365cae9373
--- /dev/null
+++ b/test_tipc/test_train_inference_python_xpu.sh
@@ -0,0 +1,38 @@
+#!/bin/bash
+source test_tipc/common_func.sh
+
+function readlinkf() {
+ perl -MCwd -e 'print Cwd::abs_path shift' "$1";
+}
+
+function func_parser_config() {
+ strs=$1
+ IFS=" "
+ array=(${strs})
+ tmp=${array[2]}
+ echo ${tmp}
+}
+
+BASEDIR=$(dirname "$0")
+REPO_ROOT_PATH=$(readlinkf ${BASEDIR}/../)
+
+FILENAME=$1
+
+# change gpu to npu in tipc txt configs
+sed -i "s/state=GPU/state=XPU/g" $FILENAME
+sed -i "s/--device:gpu/--device:xpu/g" $FILENAME
+sed -i "s/--benchmark:True/--benchmark:False/g" $FILENAME
+dataline=`cat $FILENAME`
+
+# change gpu to npu in execution script
+sed -i 's/\"gpu\"/\"xpu\"/g' test_tipc/test_train_inference_python.sh
+sed -i 's/--gpus/--xpus/g' test_tipc/test_train_inference_python.sh
+
+# parser params
+IFS=$'\n'
+lines=(${dataline})
+
+# pass parameters to test_train_inference_python.sh
+cmd="bash test_tipc/test_train_inference_python.sh ${FILENAME} $2"
+echo $cmd
+eval $cmd
diff --git a/tools/export_model.py b/tools/export_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..42c5425505003d195de8e0da35a8f9dcb1b7db45
--- /dev/null
+++ b/tools/export_model.py
@@ -0,0 +1,88 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import sys
+import argparse
+
+sys.path.append(".")
+
+import ppgan
+from ppgan.utils.config import get_config
+from ppgan.utils.setup import setup
+from ppgan.engine.trainer import Trainer
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('-c',
+ '--config-file',
+ metavar="FILE",
+ required=True,
+ help="config file path")
+ parser.add_argument("--load",
+ type=str,
+ default=None,
+ required=True,
+ help="put the path to resuming file if needed")
+ # config options
+ parser.add_argument("-o",
+ "--opt",
+ nargs="+",
+ help="set configuration options")
+ parser.add_argument("-s",
+ "--inputs_size",
+ type=str,
+ default=None,
+ required=True,
+ help="the inputs size")
+ parser.add_argument(
+ "--output_dir",
+ default=None,
+ type=str,
+ help="The path prefix of inference model to be used.",
+ )
+ parser.add_argument(
+ "--export_serving_model",
+ default=False,
+ type=bool,
+ help="export serving model.",
+ )
+ parser.add_argument(
+ "--model_name",
+ default=None,
+ type=str,
+ help="model_name.",
+ )
+ args = parser.parse_args()
+ return args
+
+
+def main(args, cfg):
+ inputs_size = [[int(size) for size in input_size.split(',')]
+ for input_size in args.inputs_size.split(';')]
+ model = ppgan.models.builder.build_model(cfg.model)
+ model.setup_train_mode(is_train=False)
+ state_dicts = ppgan.utils.filesystem.load(args.load)
+ for net_name, net in model.nets.items():
+ if net_name in state_dicts:
+ net.set_state_dict(state_dicts[net_name])
+ model.export_model(cfg.export_model, args.output_dir, inputs_size,
+ args.export_serving_model, args.model_name)
+
+
+if __name__ == "__main__":
+ args = parse_args()
+ cfg = get_config(args.config_file, args.opt)
+ main(args, cfg)
diff --git a/tools/extract_weight.py b/tools/extract_weight.py
new file mode 100644
index 0000000000000000000000000000000000000000..56dffa9f1570fe8bed6bf9e510d9fec66a5de60c
--- /dev/null
+++ b/tools/extract_weight.py
@@ -0,0 +1,40 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import paddle
+import argparse
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='This script extracts weights from a checkpoint')
+ parser.add_argument('checkpoint', help='checkpoint file')
+ parser.add_argument('--net-name',
+ type=str,
+ help='net name in checkpoint dict')
+ parser.add_argument('--output', type=str, help='destination file name')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ assert args.output.endswith(".pdparams")
+ ckpt = paddle.load(args.checkpoint)
+ state_dict = ckpt[args.net_name]
+ paddle.save(state_dict, args.output)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/fom_infer.py b/tools/fom_infer.py
new file mode 100644
index 0000000000000000000000000000000000000000..b3f0969a30e0b42fd49c561da23ff4def9c3d04e
--- /dev/null
+++ b/tools/fom_infer.py
@@ -0,0 +1,245 @@
+import paddle.inference as paddle_infer
+import argparse
+import numpy as np
+import cv2
+import imageio
+import time
+from tqdm import tqdm
+import os
+from functools import reduce
+import paddle
+from ppgan.utils.filesystem import makedirs
+from pathlib import Path
+
+
+def read_img(path):
+ img = imageio.imread(path)
+ if img.ndim == 2:
+ img = np.expand_dims(img, axis=2)
+ # som images have 4 channels
+ if img.shape[2] > 3:
+ img = img[:, :, :3]
+ return img
+
+
+def read_video(path):
+ reader = imageio.get_reader(path)
+ fps = reader.get_meta_data()['fps']
+ driving_video = []
+ try:
+ for im in reader:
+ driving_video.append(im)
+ except RuntimeError:
+ print("Read driving video error!")
+ pass
+ reader.close()
+ return driving_video, fps
+
+
+def face_detection(img_ori, weight_path):
+ config = paddle_infer.Config(os.path.join(weight_path, '__model__'),
+ os.path.join(weight_path, '__params__'))
+ config.disable_gpu()
+ # disable print log when predict
+ config.disable_glog_info()
+ # enable shared memory
+ config.enable_memory_optim()
+ # disable feed, fetch OP, needed by zero_copy_run
+ config.switch_use_feed_fetch_ops(False)
+ predictor = paddle_infer.create_predictor(config)
+
+ img = img_ori.astype(np.float32)
+ mean = np.array([123, 117, 104])[np.newaxis, np.newaxis, :]
+ std = np.array([127.502231, 127.502231, 127.502231])[np.newaxis,
+ np.newaxis, :]
+ img -= mean
+ img /= std
+ img = img[:, :, [2, 1, 0]]
+ img = img[np.newaxis].transpose([0, 3, 1, 2])
+
+ input_names = predictor.get_input_names()
+ input_tensor = predictor.get_input_handle(input_names[0])
+ input_tensor.copy_from_cpu(img)
+ predictor.run()
+ output_names = predictor.get_output_names()
+ boxes_tensor = predictor.get_output_handle(output_names[0])
+ np_boxes = boxes_tensor.copy_to_cpu()
+ if reduce(lambda x, y: x * y, np_boxes.shape) < 6:
+ print('[WARNNING] No object detected.')
+ exit()
+ w, h = img.shape[2:]
+ np_boxes[:, 2] *= h
+ np_boxes[:, 3] *= w
+ np_boxes[:, 4] *= h
+ np_boxes[:, 5] *= w
+ expect_boxes = (np_boxes[:, 1] > 0.5) & (np_boxes[:, 0] > -1)
+ rect = np_boxes[expect_boxes, :][0][2:]
+ bh = rect[3] - rect[1]
+ bw = rect[2] - rect[0]
+ cy = rect[1] + int(bh / 2)
+ cx = rect[0] + int(bw / 2)
+ margin = max(bh, bw)
+ y1 = max(0, cy - margin)
+ x1 = max(0, cx - int(0.8 * margin))
+ y2 = min(h, cy + margin)
+ x2 = min(w, cx + int(0.8 * margin))
+ return int(y1), int(y2), int(x1), int(x2)
+
+
+def main():
+ args = parse_args()
+
+ source_path = args.source_path
+ driving_path = Path(args.driving_path)
+ makedirs(args.output_path)
+ if driving_path.is_dir():
+ driving_paths = list(driving_path.iterdir())
+ else:
+ driving_paths = [driving_path]
+
+ # 创建 config
+ kp_detector_config = paddle_infer.Config(
+ os.path.join(args.model_path, "kp_detector.pdmodel"),
+ os.path.join(args.model_path, "kp_detector.pdiparams"))
+ generator_config = paddle_infer.Config(
+ os.path.join(args.model_path, "generator.pdmodel"),
+ os.path.join(args.model_path, "generator.pdiparams"))
+ if args.device == "gpu":
+ kp_detector_config.enable_use_gpu(100, 0)
+ generator_config.enable_use_gpu(100, 0)
+ elif args.device == "xpu":
+ kp_detector_config.enable_xpu()
+ generator_config.enable_xpu()
+ elif args.device == "npu":
+ kp_detector_config.enable_npu()
+ generator_config.enable_npu()
+ else:
+ kp_detector_config.set_mkldnn_cache_capacity(10)
+ kp_detector_config.enable_mkldnn()
+ generator_config.set_mkldnn_cache_capacity(10)
+ generator_config.enable_mkldnn()
+ kp_detector_config.disable_gpu()
+ kp_detector_config.set_cpu_math_library_num_threads(6)
+ generator_config.disable_gpu()
+ generator_config.set_cpu_math_library_num_threads(6)
+ # 根据 config 创建 predictor
+ kp_detector_predictor = paddle_infer.create_predictor(kp_detector_config)
+ generator_predictor = paddle_infer.create_predictor(generator_config)
+ test_loss = []
+ for k in range(len(driving_paths)):
+ driving_path = driving_paths[k]
+ driving_video, fps = read_video(driving_path)
+ driving_video = [
+ cv2.resize(frame, (256, 256)) / 255.0 for frame in driving_video
+ ]
+ driving_len = len(driving_video)
+ driving_video = np.array(driving_video).astype(np.float32).transpose(
+ [0, 3, 1, 2])
+
+ if source_path == None:
+ source = driving_video[0:1]
+ else:
+ source_img = read_img(source_path)
+ #Todo:add blazeface static model
+ #left, right, up, bottom = face_detection(source_img, "/workspace/PaddleDetection/static/inference_model/blazeface/")
+ source = source_img #[left:right, up:bottom]
+ source = cv2.resize(source, (256, 256)) / 255.0
+ source = source[np.newaxis].astype(np.float32).transpose(
+ [0, 3, 1, 2])
+
+ # 获取输入的名称
+ kp_detector_input_names = kp_detector_predictor.get_input_names()
+ kp_detector_input_handle = kp_detector_predictor.get_input_handle(
+ kp_detector_input_names[0])
+
+ kp_detector_input_handle.reshape([args.batch_size, 3, 256, 256])
+ kp_detector_input_handle.copy_from_cpu(source)
+ kp_detector_predictor.run()
+ kp_detector_output_names = kp_detector_predictor.get_output_names()
+ kp_detector_output_handle = kp_detector_predictor.get_output_handle(
+ kp_detector_output_names[0])
+ source_j = kp_detector_output_handle.copy_to_cpu()
+ kp_detector_output_handle = kp_detector_predictor.get_output_handle(
+ kp_detector_output_names[1])
+ source_v = kp_detector_output_handle.copy_to_cpu()
+
+ kp_detector_input_handle.reshape([args.batch_size, 3, 256, 256])
+ kp_detector_input_handle.copy_from_cpu(driving_video[0:1])
+ kp_detector_predictor.run()
+ kp_detector_output_names = kp_detector_predictor.get_output_names()
+ kp_detector_output_handle = kp_detector_predictor.get_output_handle(
+ kp_detector_output_names[0])
+ driving_init_j = kp_detector_output_handle.copy_to_cpu()
+ kp_detector_output_handle = kp_detector_predictor.get_output_handle(
+ kp_detector_output_names[1])
+ driving_init_v = kp_detector_output_handle.copy_to_cpu()
+ start_time = time.time()
+ results = []
+ for i in tqdm(range(0, driving_len)):
+ kp_detector_input_handle.copy_from_cpu(driving_video[i:i + 1])
+ kp_detector_predictor.run()
+ kp_detector_output_names = kp_detector_predictor.get_output_names()
+ kp_detector_output_handle = kp_detector_predictor.get_output_handle(
+ kp_detector_output_names[0])
+ driving_j = kp_detector_output_handle.copy_to_cpu()
+ kp_detector_output_handle = kp_detector_predictor.get_output_handle(
+ kp_detector_output_names[1])
+ driving_v = kp_detector_output_handle.copy_to_cpu()
+ generator_inputs = [
+ source, source_j, source_v, driving_j, driving_v,
+ driving_init_j, driving_init_v
+ ]
+ generator_input_names = generator_predictor.get_input_names()
+ for i in range(len(generator_input_names)):
+ generator_input_handle = generator_predictor.get_input_handle(
+ generator_input_names[i])
+ generator_input_handle.copy_from_cpu(generator_inputs[i])
+ generator_predictor.run()
+ generator_output_names = generator_predictor.get_output_names()
+ generator_output_handle = generator_predictor.get_output_handle(
+ generator_output_names[0])
+ output_data = generator_output_handle.copy_to_cpu()
+ loss = paddle.abs(
+ paddle.to_tensor(output_data) -
+ paddle.to_tensor(driving_video[i])).mean().cpu().numpy()
+ test_loss.append(loss)
+ output_data = np.transpose(output_data, [0, 2, 3, 1])[0] * 255.0
+
+ #Todo:add blazeface static model
+ #frame = source_img.copy()
+ #frame[left:right, up:bottom] = cv2.resize(output_data.astype(np.uint8), (bottom - up, right - left), cv2.INTER_AREA)
+ results.append(output_data.astype(np.uint8))
+ print(time.time() - start_time)
+ imageio.mimsave(os.path.join(args.output_path,
+ "result_" + str(k) + ".mp4"),
+ [frame for frame in results],
+ fps=fps)
+ metric_file = os.path.join(args.output_path, "metric.txt")
+ log_file = open(metric_file, 'a')
+ loss_string = "Metric {}: {:.4f}".format("l1 loss", np.mean(test_loss))
+ log_file.close()
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--model_path", type=str, help="model filename profix")
+ parser.add_argument("--batch_size", type=int, default=1, help="batch size")
+ parser.add_argument("--source_path",
+ type=str,
+ default=None,
+ help="source_path")
+ parser.add_argument("--driving_path",
+ type=str,
+ default=None,
+ help="driving_path")
+ parser.add_argument("--output_path",
+ type=str,
+ default="infer_output/fom/",
+ help="output_path")
+ parser.add_argument("--device", type=str, default="gpu", help="device")
+
+ return parser.parse_args()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/tools/inference.py b/tools/inference.py
new file mode 100644
index 0000000000000000000000000000000000000000..11ea4f4026e83e49672fc5732ca1eb835d12294b
--- /dev/null
+++ b/tools/inference.py
@@ -0,0 +1,471 @@
+import paddle
+import argparse
+import numpy as np
+import random
+import os
+from collections import OrderedDict
+import sys
+import cv2
+
+sys.path.append(".")
+
+from ppgan.utils.config import get_config
+from ppgan.datasets.builder import build_dataloader
+from ppgan.engine.trainer import IterLoader
+from ppgan.utils.visual import save_image
+from ppgan.utils.visual import tensor2img
+from ppgan.utils.filesystem import makedirs
+from ppgan.metrics import build_metric
+
+
+MODEL_CLASSES = ["pix2pix", "cyclegan", "wav2lip", "esrgan", \
+ "edvr", "fom", "stylegan2", "basicvsr", "msvsr", \
+ "singan", "swinir", "invdn", "aotgan", "nafnet"]
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "--model_path",
+ default=None,
+ type=str,
+ required=True,
+ help="The path prefix of inference model to be used.",
+ )
+ parser.add_argument("--model_type",
+ default=None,
+ type=str,
+ required=True,
+ help="Model type selected in the list: " +
+ ", ".join(MODEL_CLASSES))
+ parser.add_argument(
+ "--device",
+ default="gpu",
+ type=str,
+ choices=["cpu", "gpu", "xpu", "npu"],
+ help="The device to select to train the model, is must be cpu/gpu/xpu.")
+ parser.add_argument('-c',
+ '--config-file',
+ metavar="FILE",
+ help='config file path')
+ parser.add_argument("--output_path",
+ type=str,
+ default="infer_output",
+ help="output_path")
+ # config options
+ parser.add_argument("-o",
+ "--opt",
+ nargs='+',
+ help="set configuration options")
+ # fix random numbers by setting seed
+ parser.add_argument('--seed',
+ type=int,
+ default=None,
+ help='fix random numbers by setting seed\".')
+ # for tensorRT
+ parser.add_argument("--run_mode",
+ default="fluid",
+ type=str,
+ choices=["fluid", "trt_fp32", "trt_fp16"],
+ help="mode of running(fluid/trt_fp32/trt_fp16)")
+ parser.add_argument("--trt_min_shape",
+ default=1,
+ type=int,
+ help="trt_min_shape for tensorRT")
+ parser.add_argument("--trt_max_shape",
+ default=1280,
+ type=int,
+ help="trt_max_shape for tensorRT")
+ parser.add_argument("--trt_opt_shape",
+ default=640,
+ type=int,
+ help="trt_opt_shape for tensorRT")
+ parser.add_argument("--min_subgraph_size",
+ default=3,
+ type=int,
+ help="trt_opt_shape for tensorRT")
+ parser.add_argument("--batch_size",
+ default=1,
+ type=int,
+ help="batch_size for tensorRT")
+ parser.add_argument("--use_dynamic_shape",
+ dest="use_dynamic_shape",
+ action="store_true",
+ help="use_dynamic_shape for tensorRT")
+ parser.add_argument("--trt_calib_mode",
+ dest="trt_calib_mode",
+ action="store_true",
+ help="trt_calib_mode for tensorRT")
+ args = parser.parse_args()
+ return args
+
+
+def create_predictor(model_path,
+ device="gpu",
+ run_mode='fluid',
+ batch_size=1,
+ min_subgraph_size=3,
+ use_dynamic_shape=False,
+ trt_min_shape=1,
+ trt_max_shape=1280,
+ trt_opt_shape=640,
+ trt_calib_mode=False):
+ config = paddle.inference.Config(model_path + ".pdmodel",
+ model_path + ".pdiparams")
+ if device == "gpu":
+ config.enable_use_gpu(100, 0)
+ elif device == "cpu":
+ config.disable_gpu()
+ elif device == "npu":
+ config.enable_npu()
+ elif device == "xpu":
+ config.enable_xpu()
+ else:
+ config.disable_gpu()
+
+ precision_map = {
+ 'trt_int8': paddle.inference.Config.Precision.Int8,
+ 'trt_fp32': paddle.inference.Config.Precision.Float32,
+ 'trt_fp16': paddle.inference.Config.Precision.Half
+ }
+ if run_mode in precision_map.keys():
+ config.enable_tensorrt_engine(workspace_size=1 << 25,
+ max_batch_size=batch_size,
+ min_subgraph_size=min_subgraph_size,
+ precision_mode=precision_map[run_mode],
+ use_static=False,
+ use_calib_mode=trt_calib_mode)
+
+ if use_dynamic_shape:
+ min_input_shape = {
+ 'image': [batch_size, 3, trt_min_shape, trt_min_shape]
+ }
+ max_input_shape = {
+ 'image': [batch_size, 3, trt_max_shape, trt_max_shape]
+ }
+ opt_input_shape = {
+ 'image': [batch_size, 3, trt_opt_shape, trt_opt_shape]
+ }
+ config.set_trt_dynamic_shape_info(min_input_shape, max_input_shape,
+ opt_input_shape)
+ print('trt set dynamic shape done!')
+
+ predictor = paddle.inference.create_predictor(config)
+ return predictor
+
+
+def setup_metrics(cfg):
+ metrics = OrderedDict()
+ if isinstance(list(cfg.values())[0], dict):
+ for metric_name, cfg_ in cfg.items():
+ metrics[metric_name] = build_metric(cfg_)
+ else:
+ metric = build_metric(cfg)
+ metrics[metric.__class__.__name__] = metric
+
+ return metrics
+
+
+def main():
+ args = parse_args()
+ if args.seed:
+ paddle.seed(args.seed)
+ random.seed(args.seed)
+ np.random.seed(args.seed)
+ cfg = get_config(args.config_file, args.opt)
+ predictor = create_predictor(args.model_path, args.device, args.run_mode,
+ args.batch_size, args.min_subgraph_size,
+ args.use_dynamic_shape, args.trt_min_shape,
+ args.trt_max_shape, args.trt_opt_shape,
+ args.trt_calib_mode)
+ input_handles = [
+ predictor.get_input_handle(name)
+ for name in predictor.get_input_names()
+ ]
+
+ output_handle = predictor.get_output_handle(predictor.get_output_names()[0])
+ test_dataloader = build_dataloader(cfg.dataset.test,
+ is_train=False,
+ distributed=False)
+
+ max_eval_steps = len(test_dataloader)
+ iter_loader = IterLoader(test_dataloader)
+ min_max = cfg.get('min_max', None)
+ if min_max is None:
+ min_max = (-1., 1.)
+
+ model_type = args.model_type
+ makedirs(os.path.join(args.output_path, model_type))
+
+ validate_cfg = cfg.get('validate', None)
+ metrics = None
+ if validate_cfg and 'metrics' in validate_cfg:
+ metrics = setup_metrics(validate_cfg['metrics'])
+ for metric in metrics.values():
+ metric.reset()
+
+ for i in range(max_eval_steps):
+ data = next(iter_loader)
+ if model_type == "pix2pix":
+ real_A = data['B'].numpy()
+ input_handles[0].copy_from_cpu(real_A)
+ predictor.run()
+ prediction = output_handle.copy_to_cpu()
+ prediction = paddle.to_tensor(prediction)
+ image_numpy = tensor2img(prediction[0], min_max)
+ save_image(
+ image_numpy,
+ os.path.join(args.output_path, "pix2pix/{}.png".format(i)))
+ metric_file = os.path.join(args.output_path, "pix2pix/metric.txt")
+ real_B = paddle.to_tensor(data['A'])
+ for metric in metrics.values():
+ metric.update(prediction, real_B)
+
+ elif model_type == "cyclegan":
+ real_A = data['A'].numpy()
+ input_handles[0].copy_from_cpu(real_A)
+ predictor.run()
+ prediction = output_handle.copy_to_cpu()
+ prediction = paddle.to_tensor(prediction)
+ image_numpy = tensor2img(prediction[0], min_max)
+ save_image(
+ image_numpy,
+ os.path.join(args.output_path, "cyclegan/{}.png".format(i)))
+ metric_file = os.path.join(args.output_path, "cyclegan/metric.txt")
+ real_B = paddle.to_tensor(data['B'])
+ for metric in metrics.values():
+ metric.update(prediction, real_B)
+
+ elif model_type == "wav2lip":
+ indiv_mels, x = data['indiv_mels'].numpy()[0], data['x'].numpy()[0]
+ x = x.transpose([1, 0, 2, 3])
+ input_handles[0].copy_from_cpu(indiv_mels)
+ input_handles[1].copy_from_cpu(x)
+ predictor.run()
+ prediction = output_handle.copy_to_cpu()
+ for j in range(prediction.shape[0]):
+ prediction[j] = prediction[j][::-1, :, :]
+ image_numpy = paddle.to_tensor(prediction[j])
+ image_numpy = tensor2img(image_numpy, (0, 1))
+ save_image(image_numpy,
+ "infer_output/wav2lip/{}_{}.png".format(i, j))
+
+ elif model_type == "esrgan":
+ lq = data['lq'].numpy()
+ input_handles[0].copy_from_cpu(lq)
+ predictor.run()
+ prediction = output_handle.copy_to_cpu()
+ prediction = paddle.to_tensor(prediction[0])
+ image_numpy = tensor2img(prediction, min_max)
+ gt_numpy = tensor2img(data['gt'][0], min_max)
+ save_image(
+ image_numpy,
+ os.path.join(args.output_path, "esrgan/{}.png".format(i)))
+ metric_file = os.path.join(args.output_path, model_type,
+ "metric.txt")
+ for metric in metrics.values():
+ metric.update(image_numpy, gt_numpy)
+ break
+ elif model_type == "edvr":
+ lq = data['lq'].numpy()
+ input_handles[0].copy_from_cpu(lq)
+ predictor.run()
+ prediction = output_handle.copy_to_cpu()
+ prediction = paddle.to_tensor(prediction[0])
+ image_numpy = tensor2img(prediction, min_max)
+ gt_numpy = tensor2img(data['gt'][0, 0], min_max)
+ save_image(image_numpy,
+ os.path.join(args.output_path, "edvr/{}.png".format(i)))
+ metric_file = os.path.join(args.output_path, model_type,
+ "metric.txt")
+ for metric in metrics.values():
+ metric.update(image_numpy, gt_numpy)
+ break
+ elif model_type == "stylegan2":
+ noise = paddle.randn([1, 1, 512]).cpu().numpy()
+ input_handles[0].copy_from_cpu(noise)
+ input_handles[1].copy_from_cpu(np.array([0.7]).astype('float32'))
+ predictor.run()
+ prediction = output_handle.copy_to_cpu()
+ prediction = paddle.to_tensor(prediction)
+ image_numpy = tensor2img(prediction[0], min_max)
+ save_image(
+ image_numpy,
+ os.path.join(args.output_path, "stylegan2/{}.png".format(i)))
+ metric_file = os.path.join(args.output_path, "stylegan2/metric.txt")
+ real_img = paddle.to_tensor(data['A'])
+ for metric in metrics.values():
+ metric.update(prediction, real_img)
+ elif model_type in ["basicvsr", "msvsr"]:
+ lq = data['lq'].numpy()
+ input_handles[0].copy_from_cpu(lq)
+ predictor.run()
+ if len(predictor.get_output_names()) > 1:
+ output_handle = predictor.get_output_handle(
+ predictor.get_output_names()[-1])
+ prediction = output_handle.copy_to_cpu()
+ prediction = paddle.to_tensor(prediction)
+ _, t, _, _, _ = prediction.shape
+
+ out_img = []
+ gt_img = []
+ for ti in range(t):
+ out_tensor = prediction[0, ti]
+ gt_tensor = data['gt'][0, ti]
+ out_img.append(tensor2img(out_tensor, (0., 1.)))
+ gt_img.append(tensor2img(gt_tensor, (0., 1.)))
+
+ image_numpy = tensor2img(prediction[0], min_max)
+ save_image(
+ image_numpy,
+ os.path.join(args.output_path, model_type, "{}.png".format(i)))
+
+ metric_file = os.path.join(args.output_path, model_type,
+ "metric.txt")
+ for metric in metrics.values():
+ metric.update(out_img, gt_img, is_seq=True)
+ elif model_type == "singan":
+ predictor.run()
+ prediction = output_handle.copy_to_cpu()
+ prediction = paddle.to_tensor(prediction)
+ image_numpy = tensor2img(prediction, min_max)
+ save_image(
+ image_numpy,
+ os.path.join(args.output_path, "singan/{}.png".format(i)))
+ metric_file = os.path.join(args.output_path, "singan/metric.txt")
+ for metric in metrics.values():
+ metric.update(prediction, data['A'])
+ elif model_type == 'gfpgan':
+ input_handles[0].copy_from_cpu(data['lq'].numpy())
+ predictor.run()
+ prediction = output_handle.copy_to_cpu()
+ prediction = paddle.to_tensor(prediction)
+ image_numpy = tensor2img(prediction, min_max)
+ save_image(
+ image_numpy,
+ os.path.join(args.output_path, "gfpgan/{}.png".format(i)))
+ elif model_type == "swinir":
+ lq = data[1].numpy()
+ _, _, h_old, w_old = lq.shape
+ window_size = 8
+ tile = 128
+ tile_overlap = 32
+ # after feed data to model, shape of feature map is change
+ h_pad = (h_old // window_size + 1) * window_size - h_old
+ w_pad = (w_old // window_size + 1) * window_size - w_old
+ lq = np.concatenate([lq, np.flip(lq, 2)],
+ axis=2)[:, :, :h_old + h_pad, :]
+ lq = np.concatenate([lq, np.flip(lq, 3)],
+ axis=3)[:, :, :, :w_old + w_pad]
+ lq = lq.astype("float32")
+
+ b, c, h, w = lq.shape
+ tile = min(tile, h, w)
+ assert tile % window_size == 0, "tile size should be a multiple of window_size"
+ sf = 1 # scale
+ stride = tile - tile_overlap
+ h_idx_list = list(range(0, h - tile, stride)) + [h - tile]
+ w_idx_list = list(range(0, w - tile, stride)) + [w - tile]
+ E = np.zeros([b, c, h * sf, w * sf], dtype=np.float32)
+ W = np.zeros_like(E)
+
+ for h_idx in h_idx_list:
+ for w_idx in w_idx_list:
+ in_patch = lq[..., h_idx:h_idx + tile, w_idx:w_idx + tile]
+ input_handles[0].copy_from_cpu(in_patch)
+ predictor.run()
+ out_patch = output_handle.copy_to_cpu()
+ out_patch_mask = np.ones_like(out_patch)
+
+ E[..., h_idx * sf:(h_idx + tile) * sf,
+ w_idx * sf:(w_idx + tile) * sf] += out_patch
+ W[..., h_idx * sf:(h_idx + tile) * sf,
+ w_idx * sf:(w_idx + tile) * sf] += out_patch_mask
+
+ output = np.true_divide(E, W)
+ prediction = output[..., :h_old * sf, :w_old * sf]
+
+ prediction = paddle.to_tensor(prediction)
+ target = tensor2img(data[0], (0., 1.))
+ prediction = tensor2img(prediction, (0., 1.))
+
+ metric_file = os.path.join(args.output_path, model_type,
+ "metric.txt")
+ for metric in metrics.values():
+ metric.update(prediction, target)
+
+ lq = tensor2img(data[1], (0., 1.))
+
+ sample_result = np.concatenate((lq, prediction, target), 1)
+ sample = cv2.cvtColor(sample_result, cv2.COLOR_RGB2BGR)
+ file_name = os.path.join(args.output_path, model_type,
+ "{}.png".format(i))
+ cv2.imwrite(file_name, sample)
+ elif model_type == "invdn":
+ noisy = data[0].numpy()
+ noise_channel = 3 * 4**(cfg.model.generator.down_num) - 3
+ input_handles[0].copy_from_cpu(noisy)
+ input_handles[1].copy_from_cpu(
+ np.random.randn(noisy.shape[0], noise_channel, noisy.shape[2],
+ noisy.shape[3]).astype(np.float32))
+ predictor.run()
+ output_handles = [
+ predictor.get_output_handle(name)
+ for name in predictor.get_output_names()
+ ]
+ prediction = output_handles[0].copy_to_cpu()
+ prediction = paddle.to_tensor(prediction[0])
+ image_numpy = tensor2img(prediction, min_max)
+ gt_numpy = tensor2img(data[1], min_max)
+ save_image(image_numpy,
+ os.path.join(args.output_path, "invdn/{}.png".format(i)))
+ metric_file = os.path.join(args.output_path, model_type,
+ "metric.txt")
+ for metric in metrics.values():
+ metric.update(image_numpy, gt_numpy)
+ break
+
+ elif model_type == "nafnet":
+ lq = data[1].numpy()
+ input_handles[0].copy_from_cpu(lq)
+ predictor.run()
+ prediction = output_handle.copy_to_cpu()
+ prediction = paddle.to_tensor(prediction)
+ target = tensor2img(data[0], (0., 1.))
+ prediction = tensor2img(prediction, (0., 1.))
+
+ metric_file = os.path.join(args.output_path, model_type,
+ "metric.txt")
+ for metric in metrics.values():
+ metric.update(prediction, target)
+
+ lq = tensor2img(data[1], (0., 1.))
+
+ sample_result = np.concatenate((lq, prediction, target), 1)
+ sample = cv2.cvtColor(sample_result, cv2.COLOR_RGB2BGR)
+ file_name = os.path.join(args.output_path, model_type,
+ "{}.png".format(i))
+ cv2.imwrite(file_name, sample)
+ elif model_type == 'aotgan':
+ input_data = paddle.concat((data['img'], data['mask']),
+ axis=1).numpy()
+ input_handles[0].copy_from_cpu(input_data)
+ predictor.run()
+ prediction = output_handle.copy_to_cpu()
+ prediction = paddle.to_tensor(prediction)
+ image_numpy = tensor2img(prediction, min_max)
+ save_image(
+ image_numpy,
+ os.path.join(args.output_path, "aotgan/{}.png".format(i)))
+
+ if metrics:
+ log_file = open(metric_file, 'a')
+ for metric_name, metric in metrics.items():
+ loss_string = "Metric {}: {:.4f}".format(metric_name,
+ metric.accumulate())
+ print(loss_string, file=log_file)
+ log_file.close()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/main.py b/tools/main.py
index 7d40c11c5b4b93ae9cd4678909efc8b4526dedde..b7e2b82607401d87fa6b2309528e776d2f0f2f92 100644
--- a/tools/main.py
+++ b/tools/main.py
@@ -51,6 +51,6 @@ def main(args, cfg):
if __name__ == '__main__':
args = parse_args()
- cfg = get_config(args.config_file)
+ cfg = get_config(args.config_file, args.opt)
main(args, cfg)
diff --git a/tools/styleclip_getf.py b/tools/styleclip_getf.py
new file mode 100644
index 0000000000000000000000000000000000000000..57767dc7e129cd23825ef9edd6aeff5f78231e50
--- /dev/null
+++ b/tools/styleclip_getf.py
@@ -0,0 +1,89 @@
+import argparse
+from tqdm import tqdm
+import paddle
+import numpy as np
+
+from ppgan.apps.styleganv2_predictor import StyleGANv2Predictor
+
+
+def concat_style_paddle(s_lst, n_layers):
+ result = [list() for _ in range(n_layers)]
+ assert n_layers == len(s_lst[0])
+ for i in range(n_layers):
+ for s_ in s_lst:
+ result[i].append(s_[i])
+ for i in range(n_layers):
+ result[i] = paddle.concat(result[i])
+ return result
+
+
+def to_np(s_lst):
+ for i in range(len(s_lst)):
+ s_lst[i] = s_lst[i].numpy()
+ return s_lst
+
+
+def concat_style_np(s_lst, n_layers):
+ result = [list() for _ in range(n_layers)]
+ assert n_layers == len(s_lst[0])
+ for i in range(n_layers):
+ for s_ in s_lst:
+ result[i].append(s_[i])
+ for i in range(n_layers):
+ result[i] = np.concatenate(result[i])
+ return result
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--dataset_name', type=str, default='ffhq-config-f')
+ parser.add_argument('--seed', type=int, default=1234)
+ args = parser.parse_args()
+
+ dataset_name = args.dataset_name
+ G = StyleGANv2Predictor(model_type=dataset_name).generator
+ w_idx_lst = G.w_idx_lst
+
+ with paddle.no_grad():
+ # get intermediate latent of 100000 samples
+ w_lst = list()
+ z = paddle.to_tensor(
+ np.random.RandomState(args.seed).randn(
+ 1000, 100, G.style_dim).astype('float32'))
+ #z = paddle.randn([1000, 100, G.style_dim])
+ for i in tqdm(range(1000)): # 100 * 1000 = 100000 # 1000
+ # apply truncation_psi=.7 truncation_cutoff=8
+ w_lst.append(
+ G.get_latents(z[i], truncation=0.7, truncation_cutoff=8))
+ #paddle.save(paddle.concat(w_lst[:20]), f'W-{dataset_name}.pdparams')
+
+ s_lst = []
+ # get style of first 2000 sample in W
+ for i in tqdm(range(20)): # 2*1000
+ s_ = G.style_affine(w_lst[i])
+ s_lst.append(s_)
+ paddle.save(concat_style_paddle(s_lst, len(w_idx_lst)),
+ f'S-{dataset_name}.pdparams')
+
+ for i in tqdm(range(20)): # 2*1000
+ s_lst[i] = to_np(s_lst[i])
+
+ # get std, mean of 100000 style samples
+ for i in tqdm(range(20, 1000)): # 100 * 1000
+ s_ = G.style_affine(w_lst[i])
+ s_lst.append(to_np(s_))
+ del w_lst, z, s_, G
+ s_lst = concat_style_np(s_lst, len(w_idx_lst))
+ s_mean = [
+ paddle.mean(paddle.to_tensor(s_lst[i]), axis=0)
+ for i in range(len(w_idx_lst))
+ ]
+ s_std = [
+ paddle.std(paddle.to_tensor(s_lst[i]), axis=0)
+ for i in range(len(w_idx_lst))
+ ]
+ paddle.save({
+ 'mean': s_mean,
+ 'std': s_std
+ }, f'stylegan2-{dataset_name}-styleclip-stats.pdparams')
+ print("Done.")
 +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+ +
+ 
 +
+ 
 +
+  +
+ 
 +
+ 
 +
+ 
 +
+ 
 +
+ 
 +
+ 
 +扫描二维码回复关键字"GAN"即可加入官方微信交流群!
+
+扫描二维码回复关键字"GAN"即可加入官方微信交流群!
+  +
+