![]()
🍬Java轻量级、免费、离线AI工具箱,致力于帮助Java开发者零门槛使用AI算法模型
像Hutool一样简单易用的Java AI工具箱


![]()
![]()

![]()
|
人脸检测(Face Detection) - 5点人脸关键点定位 |

|
|
|
人脸比对1:1 |

|
|
|
人证核验 |

|
|
|
人脸比对1:N - 人脸注册 - 人脸库查询 - 人脸库删除 |

|
|
|
人脸属性检测 - 性别检测(GenderDetection)- 年龄检测(AgeDetection) - 口罩检测(Face Mask Detection) - 眼睛状态检测(EyeClosenessDetection) - 脸部姿态检测(FacePoseEstimation) |

|
|
|
活体检测 |

|
|
|
人脸表情识别 |

|
|
|
目标检测(Object Detection) - 视频流目标检测:rtsp、摄像头、视频文件等 |

|

|
|
语义分割 |

|
|
|
实例分割 |
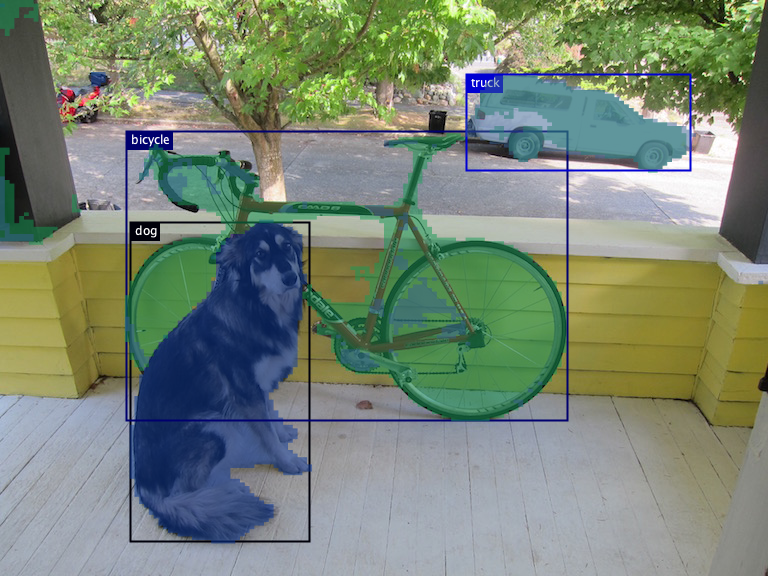
|
|
|
自定义目标训练+检测 |

|
|
|
行人检测(Person Detection) |

|
|
|
人类动作识别 |

|
|
|
OBB旋转框检测 |

|
|
|
姿态估计 |

|
|
|
OCR文字识别 - 支持印刷体识别 - 支持手写字识别 |

|
|
|
OCR文字识别 - 表格识别(Table Structure Recognition) |
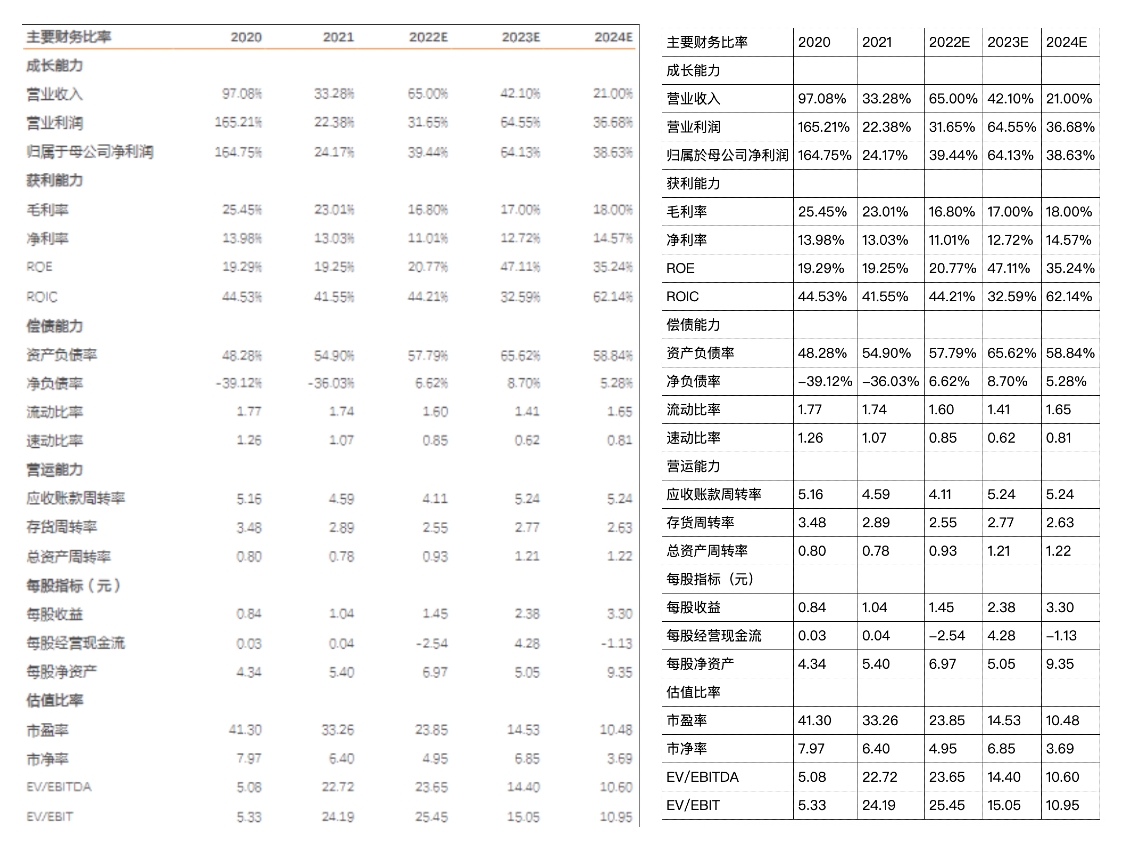
|
|
|
车牌识别 - 车牌颜色识别 |

|

|
|
机器翻译 |
|
|
|
语音识别 - 支持实时语音识别 |

|
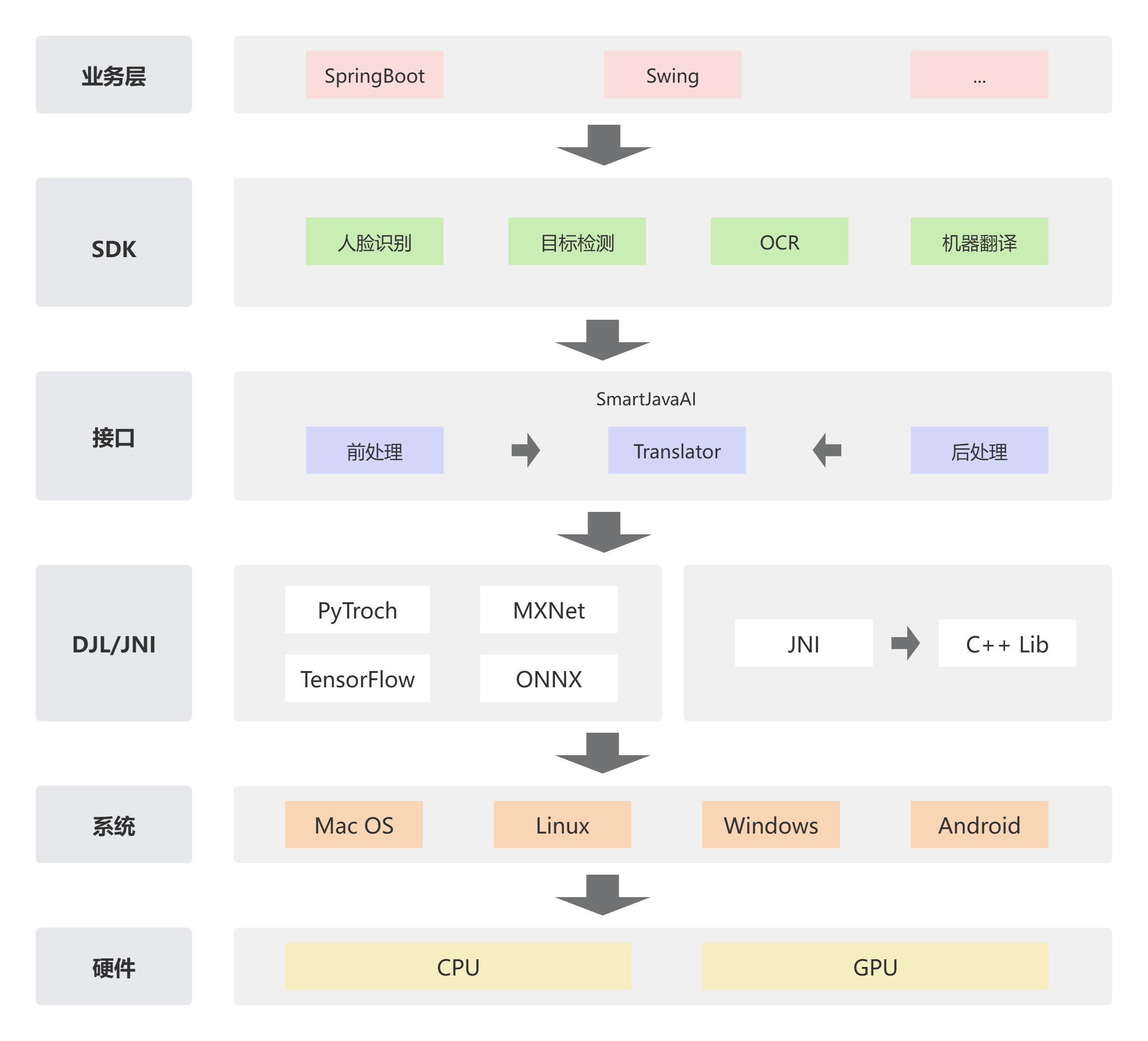 -------------------------------------------------------------------------------
## 📦 安装
### 1、环境要求
- Java 版本:**JDK 8或更高版本**
- 操作系统:不同模型支持的系统不一样,具体请查看[文档](http://doc.smartjavaai.cn)
### 2、Maven
在项目的 `pom.xml` 的 `dependencies` 中可以一次性引入全部功能(如下所示)。
⚠️ **注意:不推荐直接引入全部依赖**,更推荐根据实际需求,按功能模块单独引入,避免引入不必要的包。
详细引入方式请查看 [文档](http://doc.smartjavaai.cn/install.html)、或查看[示例代码](https://gitee.com/dengwenjie/SmartJavaAI/tree/master/examples)
```xml
-------------------------------------------------------------------------------
## 📦 安装
### 1、环境要求
- Java 版本:**JDK 8或更高版本**
- 操作系统:不同模型支持的系统不一样,具体请查看[文档](http://doc.smartjavaai.cn)
### 2、Maven
在项目的 `pom.xml` 的 `dependencies` 中可以一次性引入全部功能(如下所示)。
⚠️ **注意:不推荐直接引入全部依赖**,更推荐根据实际需求,按功能模块单独引入,避免引入不必要的包。
详细引入方式请查看 [文档](http://doc.smartjavaai.cn/install.html)、或查看[示例代码](https://gitee.com/dengwenjie/SmartJavaAI/tree/master/examples)
```xml