# PaddleNLP
**Repository Path**: yyzjm/PaddleNLP
## Basic Information
- **Project Name**: PaddleNLP
- **Description**: Easy-to-use and powerful NLP library with Awesome model zoo, supporting wide-range of NLP tasks from research to industrial applications (Neural Search/QA/IE/Sentiment Analysis)
- **Primary Language**: Python
- **License**: Apache-2.0
- **Default Branch**: develop
- **Homepage**: http://paddlenlp.readthedocs.io
- **GVP Project**: No
## Statistics
- **Stars**: 0
- **Forks**: 174
- **Created**: 2022-11-20
- **Last Updated**: 2022-11-20
## Categories & Tags
**Categories**: Uncategorized
**Tags**: None
## README
[简体中文🀄](./README_cn.md) | **English**🌎

------------------------------------------------------------------------------------------









**PaddleNLP** is an *easy-to-use* and *powerful* NLP library with **Awesome** pre-trained model zoo, supporting wide-range of NLP tasks from research to industrial applications.
## News 📢
* 🔥 **2022.11.12 PaddleNLP added AutoPrompt and won the first place in FewCLUE!**
* 🥇 The PaddleNLP team has open-sourced the **AutoPrompt** solution, which is based on the open-source Wenxin ERNIE pre-training language model, combined with domain pre-training and automated prompt learning technology, and ranked first in FewCLUE (a authoritative few-sample learning contest) with a model with 291M parameters. [see details](https://mp.weixin.qq.com/s/_JPiAzFA1f0BZ0igdv-EKA).
* 🔥 **2022.10.27 [PaddleNLP v2.4.2](https://github.com/PaddlePaddle/PaddleNLP/releases/tag/v2.4.2) Released!**
* NLG Upgrade: 📄 Release [**Solution of Text Summarization**](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/text_summarization/pegasus) based on Pegasus;❓ Release [**Solution of Problem Generation**](./examples/question_generation), providing **general problem generation pre-trained model** based on Baidu's UNIMO Text and large-scale multi domain problem generation dataset。Supporting high-performance inference ability based on FasterGeneration , and covering the whole process of training , inference and deployment.
* 🔥 **2022.10.14 [PaddleNLP v2.4.1](https://github.com/PaddlePaddle/PaddleNLP/releases/tag/v2.4.1) Released!**
* 🧾 Release multilingual/cross-lingual pre-trained models [**ERNIE-Layout**](./model_zoo/ernie-layout/) which achieves new SOTA results in 11 downstream tasks. **DocPrompt** 🔖 based on ERNIE-Layout is also released which has the ability for multilingual document information extraction and question ansering.
* 🔥 **2022.9.6 [PaddleNLPv2.4](https://github.com/PaddlePaddle/PaddleNLP/releases/tag/v2.4.0) Released!**
* 💎 NLP Tool:**[Pipelines](./pipelines)** released. Supports for fast construction of search engine and question answering systems, and it is expandable to all kinds of NLP systems. Building end-to-end pipelines for NLP tasks like playing Lego!
* 💢 Industrial application:Release **[Complete Solution of Text Classification](./applications/text_classification)** covering various scenarios of text classification: multi-class, multi-label and hierarchical, it also supports for **few-shot learning** and the training and optimization of **TrustAI**. Upgrade for [**Universal Information Extraction**](./model_zoo/uie) and release **UIE-M**, support both Chinese and English information extraction in a single model; release the data distillation solution for UIE to break the bottleneck of time-consuming of inference.
* 🍭 AIGC: Release code generation SOTA model [**CodeGen**](./examples/code_generation/codegen), supports for multiple programming languages code generation. Integrate [**Text to Image Model**](https://github.com/PaddlePaddle/PaddleNLP/blob/develop/docs/model_zoo/taskflow.md#%E6%96%87%E5%9B%BE%E7%94%9F%E6%88%90) DALL·E Mini, Disco Diffusion, Stable Diffusion, let's play and have some fun! Release [**Chinese Text Summarization Application**](./applications/text_summarization), first release of chinese text summarization model pretrained on a large scale of corpus, it can be use via Taskflow API and support for finetuning on your own data.
* 💪 Framework upgrade: Release [**Auto Model Compression API**](./docs/compression.md), supports for pruning and quantization automatically, lower the barriers of model compression; Release [**Few-shot Prompt**](./applications/text_classification/multi_class/few-shot), includes the algorithms such as PET, P-Tuning and RGL.
## Features
#### 📦 Out-of-Box NLP Toolset
#### 🤗 Awesome Chinese Model Zoo
#### 🎛️ Industrial End-to-end System
#### 🚀 High Performance Distributed Training and Inference
### Out-of-Box NLP Toolset
Taskflow aims to provide off-the-shelf NLP pre-built task covering NLU and NLG technique, in the meanwhile with extreamly fast infernece satisfying industrial scenario.
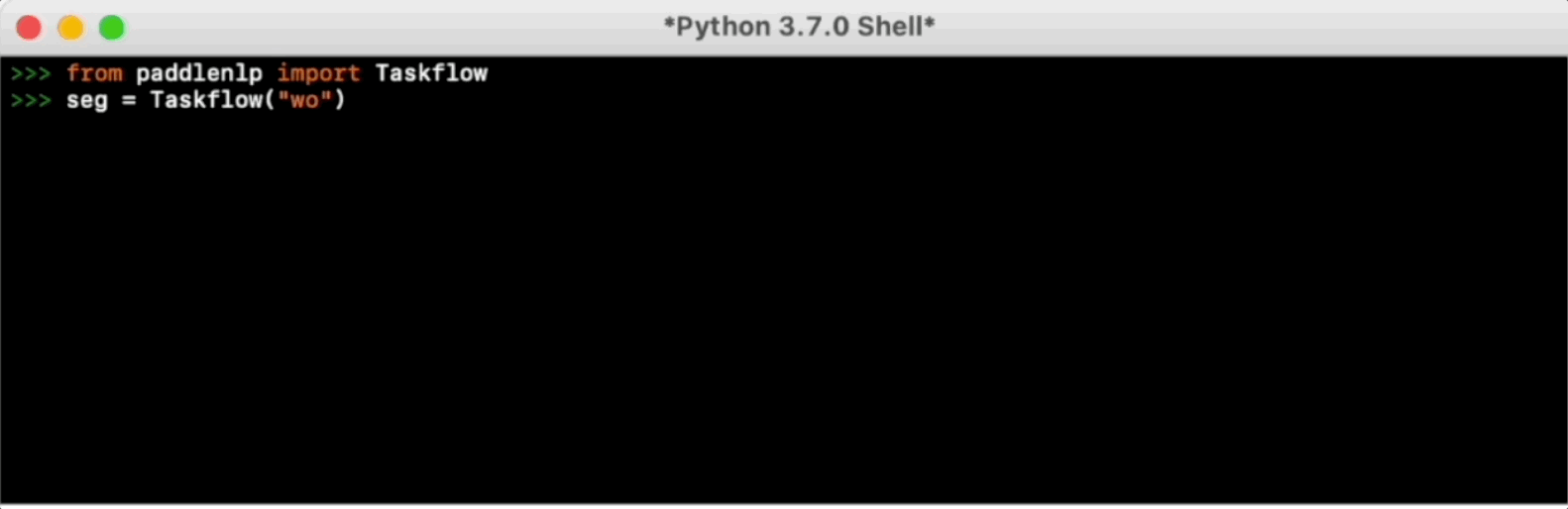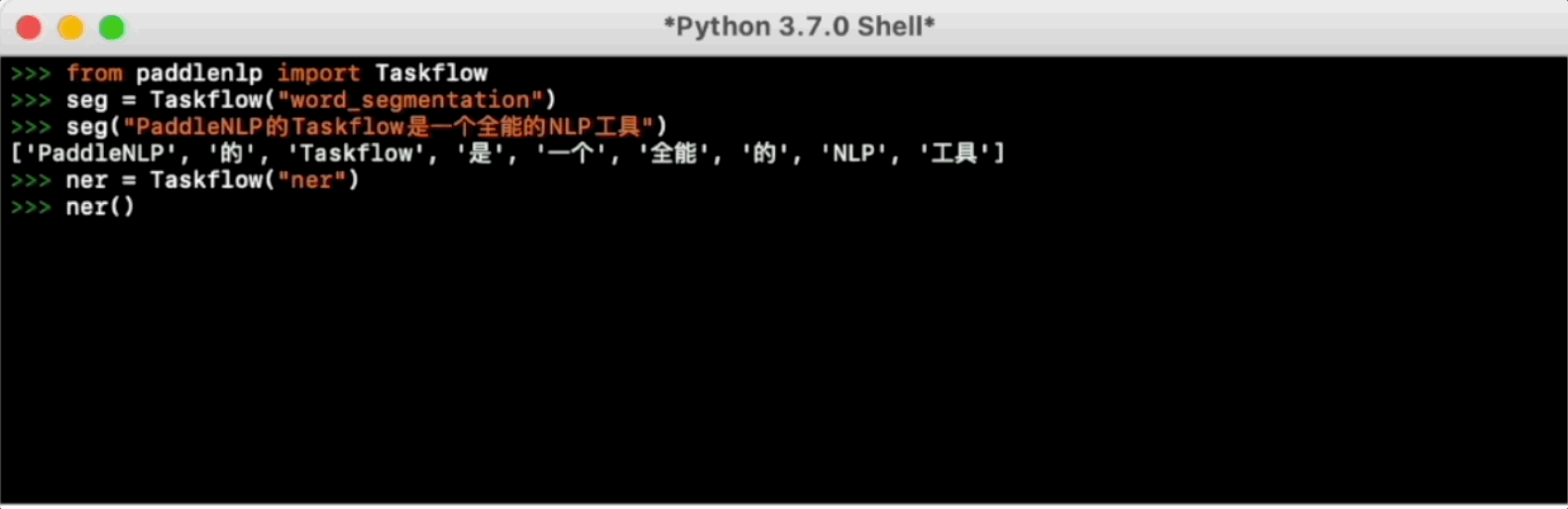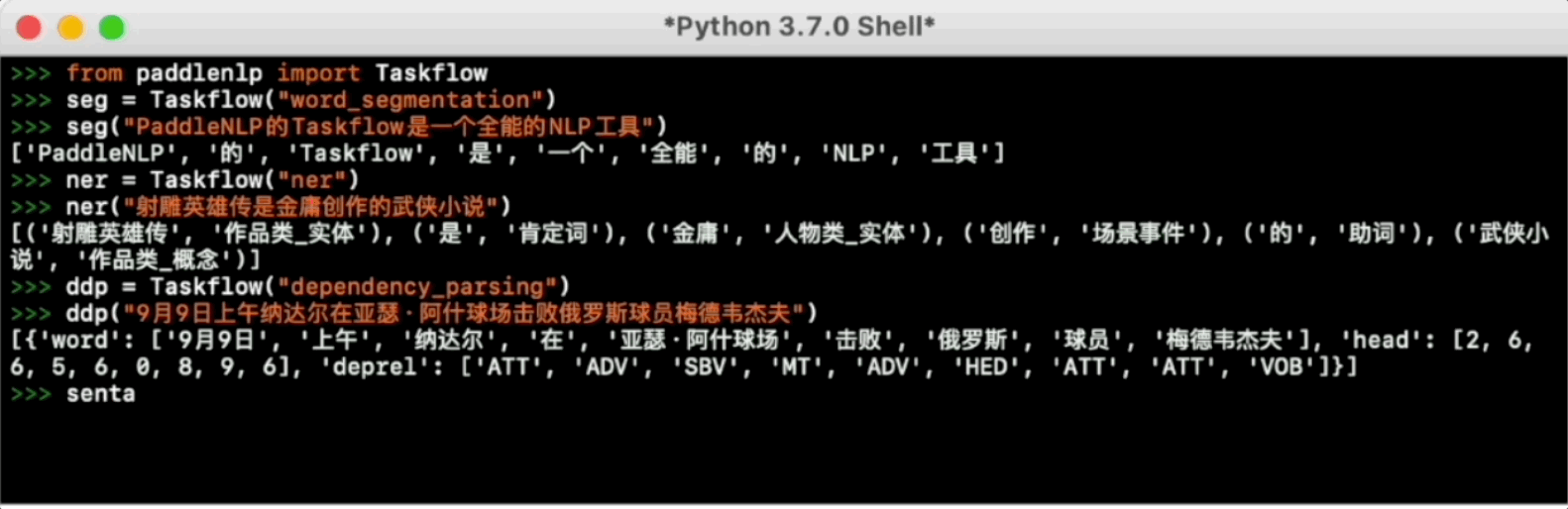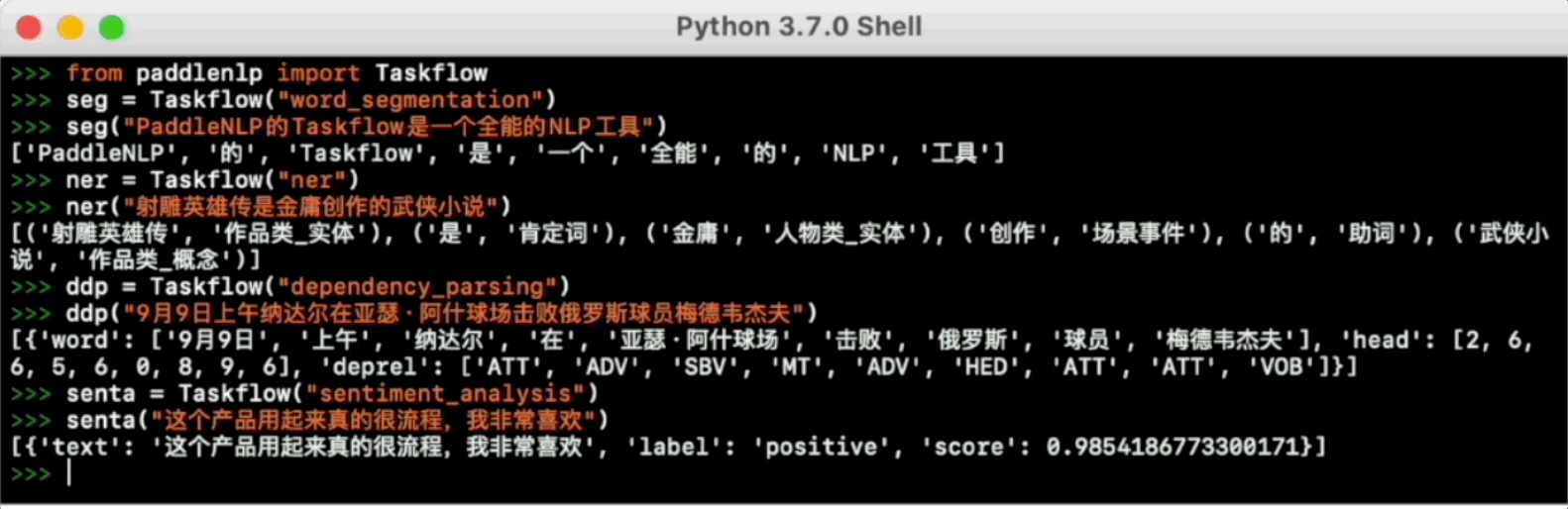
For more usage please refer to [Taskflow Docs](./docs/model_zoo/taskflow.md).
### Awesome Chinese Model Zoo
#### 🀄 Comprehensive Chinese Transformer Models
We provide **45+** network architectures and over **500+** pretrained models. Not only includes all the SOTA model like ERNIE, PLATO and SKEP released by Baidu, but also integrates most of the high-quality Chinese pretrained model developed by other organizations. Use `AutoModel` API to **⚡SUPER FAST⚡** download pretrained models of different architecture. We welcome all developers to contribute your Transformer models to PaddleNLP!
```python
from paddlenlp.transformers import *
ernie = AutoModel.from_pretrained('ernie-3.0-medium-zh')
bert = AutoModel.from_pretrained('bert-wwm-chinese')
albert = AutoModel.from_pretrained('albert-chinese-tiny')
roberta = AutoModel.from_pretrained('roberta-wwm-ext')
electra = AutoModel.from_pretrained('chinese-electra-small')
gpt = AutoModelForPretraining.from_pretrained('gpt-cpm-large-cn')
```
Due to the computation limitation, you can use the ERNIE-Tiny light models to accelerate the deployment of pretrained models.
```python
# 6L768H
ernie = AutoModel.from_pretrained('ernie-3.0-medium-zh')
# 6L384H
ernie = AutoModel.from_pretrained('ernie-3.0-mini-zh')
# 4L384H
ernie = AutoModel.from_pretrained('ernie-3.0-micro-zh')
# 4L312H
ernie = AutoModel.from_pretrained('ernie-3.0-nano-zh')
```
Unified API experience for NLP task like semantic representation, text classification, sentence matching, sequence labeling, question answering, etc.
```python
import paddle
from paddlenlp.transformers import *
tokenizer = AutoTokenizer.from_pretrained('ernie-3.0-medium-zh')
text = tokenizer('natural language processing')
# Semantic Representation
model = AutoModel.from_pretrained('ernie-3.0-medium-zh')
sequence_output, pooled_output = model(input_ids=paddle.to_tensor([text['input_ids']]))
# Text Classificaiton and Matching
model = AutoModelForSequenceClassification.from_pretrained('ernie-3.0-medium-zh')
# Sequence Labeling
model = AutoModelForTokenClassification.from_pretrained('ernie-3.0-medium-zh')
# Question Answering
model = AutoModelForQuestionAnswering.from_pretrained('ernie-3.0-medium-zh')
```
#### Wide-range NLP Task Support
PaddleNLP provides rich examples covering mainstream NLP task to help developers accelerate problem solving. You can find our powerful transformer [Model Zoo](./model_zoo), and wide-range NLP application [exmaples](./examples) with detailed instructions.
Also you can run our interactive [Notebook tutorial](https://aistudio.baidu.com/aistudio/personalcenter/thirdview/574995) on AI Studio, a powerful platform with **FREE** computing resource.
PaddleNLP Transformer model summary (click to show details)
| Model | Sequence Classification | Token Classification | Question Answering | Text Generation | Multiple Choice |
| :----------------- | ----------------------- | -------------------- | ------------------ | --------------- | --------------- |
| ALBERT | ✅ | ✅ | ✅ | ❌ | ✅ |
| BART | ✅ | ✅ | ✅ | ✅ | ❌ |
| BERT | ✅ | ✅ | ✅ | ❌ | ✅ |
| BigBird | ✅ | ✅ | ✅ | ❌ | ✅ |
| BlenderBot | ❌ | ❌ | ❌ | ✅ | ❌ |
| ChineseBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| ConvBERT | ✅ | ✅ | ✅ | ❌ | ✅ |
| CTRL | ✅ | ❌ | ❌ | ❌ | ❌ |
| DistilBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| ELECTRA | ✅ | ✅ | ✅ | ❌ | ✅ |
| ERNIE | ✅ | ✅ | ✅ | ❌ | ✅ |
| ERNIE-CTM | ❌ | ✅ | ❌ | ❌ | ❌ |
| ERNIE-Doc | ✅ | ✅ | ✅ | ❌ | ❌ |
| ERNIE-GEN | ❌ | ❌ | ❌ | ✅ | ❌ |
| ERNIE-Gram | ✅ | ✅ | ✅ | ❌ | ❌ |
| ERNIE-M | ✅ | ✅ | ✅ | ❌ | ❌ |
| FNet | ✅ | ✅ | ✅ | ❌ | ✅ |
| Funnel-Transformer | ✅ | ✅ | ✅ | ❌ | ❌ |
| GPT | ✅ | ✅ | ❌ | ✅ | ❌ |
| LayoutLM | ✅ | ✅ | ❌ | ❌ | ❌ |
| LayoutLMv2 | ❌ | ✅ | ❌ | ❌ | ❌ |
| LayoutXLM | ❌ | ✅ | ❌ | ❌ | ❌ |
| LUKE | ❌ | ✅ | ✅ | ❌ | ❌ |
| mBART | ✅ | ❌ | ✅ | ❌ | ✅ |
| MegatronBERT | ✅ | ✅ | ✅ | ❌ | ✅ |
| MobileBERT | ✅ | ❌ | ✅ | ❌ | ❌ |
| MPNet | ✅ | ✅ | ✅ | ❌ | ✅ |
| NEZHA | ✅ | ✅ | ✅ | ❌ | ✅ |
| PP-MiniLM | ✅ | ❌ | ❌ | ❌ | ❌ |
| ProphetNet | ❌ | ❌ | ❌ | ✅ | ❌ |
| Reformer | ✅ | ❌ | ✅ | ❌ | ❌ |
| RemBERT | ✅ | ✅ | ✅ | ❌ | ✅ |
| RoBERTa | ✅ | ✅ | ✅ | ❌ | ✅ |
| RoFormer | ✅ | ✅ | ✅ | ❌ | ❌ |
| SKEP | ✅ | ✅ | ❌ | ❌ | ❌ |
| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| T5 | ❌ | ❌ | ❌ | ✅ | ❌ |
| TinyBERT | ✅ | ❌ | ❌ | ❌ | ❌ |
| UnifiedTransformer | ❌ | ❌ | ❌ | ✅ | ❌ |
| XLNet | ✅ | ✅ | ✅ | ❌ | ✅ |
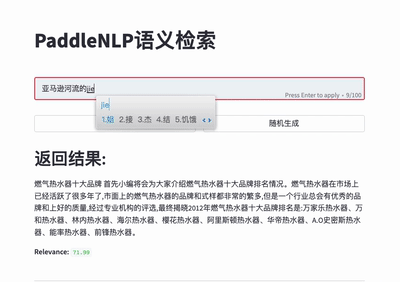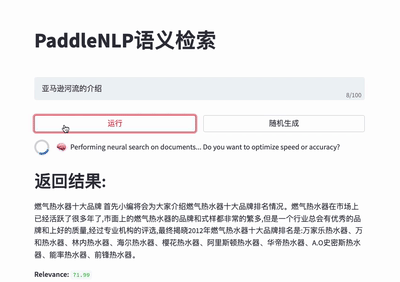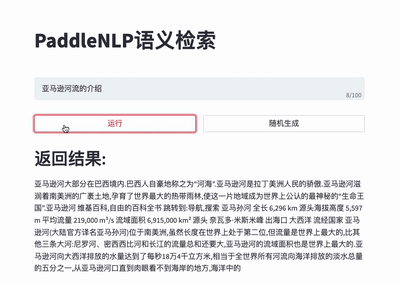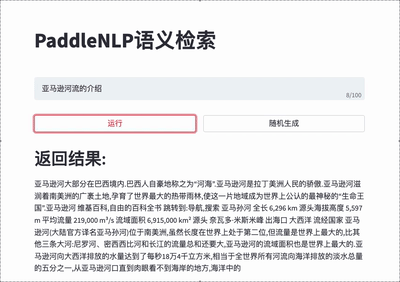
For more details please refer to [Neural Search](./applications/neural_search).
#### ❓ Question Answering System
We provide question answering pipeline which can support FAQ system, Document-level Visual Question answering system based on [🚀RocketQA](https://github.com/PaddlePaddle/RocketQA).

For more details please refer to [Question Answering](./applications/question_answering) and [Document VQA](./applications/document_intelligence/doc_vqa).
#### 💌 Opinion Extraction and Sentiment Analysis
We build an opinion extraction system for product review and fine-grained sentiment analysis based on [SKEP](https://arxiv.org/abs/2005.05635) Model.

For more details please refer to [Sentiment Analysis](./applications/sentiment_analysis).
#### 🎙️ Speech Command Analysis
Integrated ASR Model, Information Extraction, we provide a speech command analysis pipeline that show how to use PaddleNLP and [PaddleSpeech](https://github.com/PaddlePaddle/PaddleSpeech) to solve Speech + NLP real scenarios.

For more details please refer to [Speech Command Analysis](./applications/speech_cmd_analysis).
### High Performance Distributed Training and Inference
#### ⚡ FastTokenizer: High Performance Text Preprocessing Library
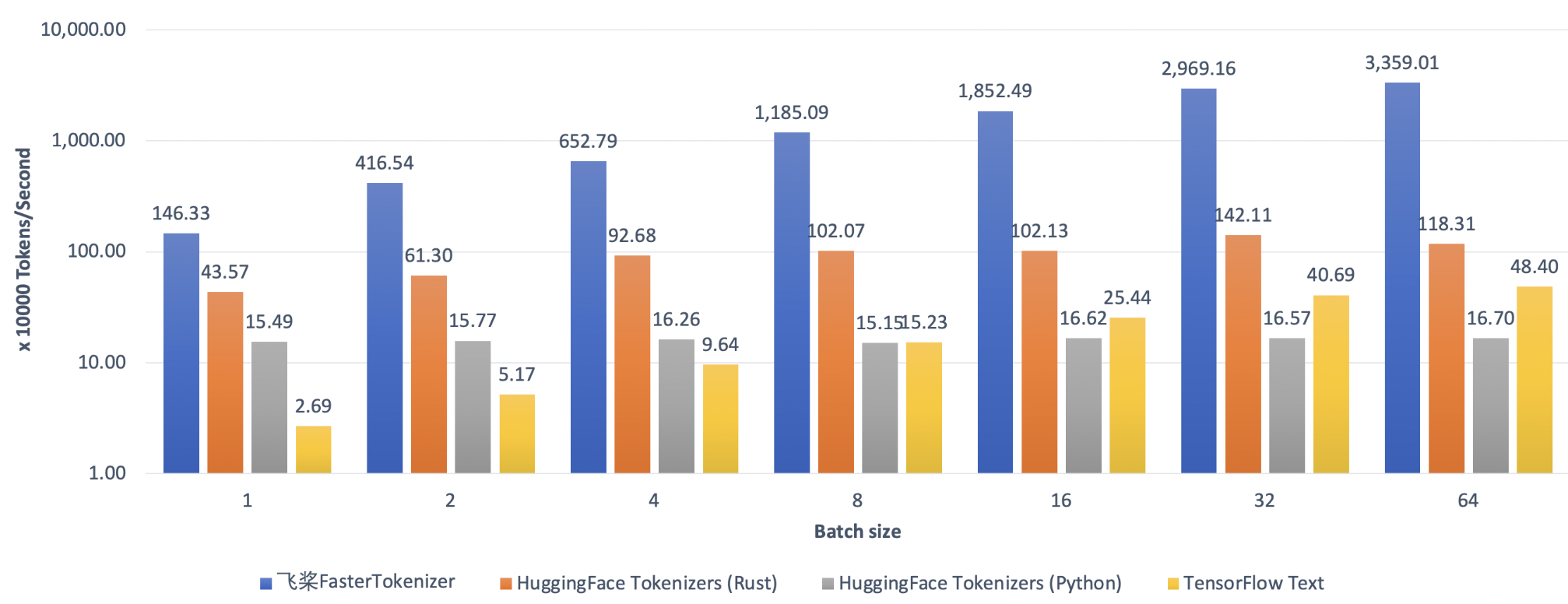
```python
AutoTokenizer.from_pretrained("ernie-3.0-medium-zh", use_fast=True)
```
Set `use_fast=True` to use C++ Tokenizer kernel to achieve 100x faster on text pre-processing. For more usage please refer to [FastTokenizer](./fast_tokenizer).
#### ⚡ FasterGeneration: High Perforance Generation Library

```python
model = GPTLMHeadModel.from_pretrained('gpt-cpm-large-cn')
...
outputs, _ = model.generate(
input_ids=inputs_ids, max_length=10, decode_strategy='greedy_search',
use_faster=True)
```
Set `use_faster=True` to achieve 5x speedup for Transformer, GPT, BART, PLATO, UniLM text generation. For more usage please refer to [FasterGeneration](./faster_generation).
#### 🚀 Fleet: 4D Hybrid Distributed Training

For more super large-scale model pre-training details please refer to [GPT-3](./examples/language_model/gpt-3).
## Installation
### Prerequisites
* python >= 3.6
* paddlepaddle >= 2.2
More information about PaddlePaddle installation please refer to [PaddlePaddle's Website](https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/install/conda/linux-conda.html).
### Python pip Installation
```
pip install --upgrade paddlenlp
```
## Quick Start
**Taskflow** aims to provide off-the-shelf NLP pre-built task covering NLU and NLG scenario, in the meanwhile with extreamly fast infernece satisfying industrial applications.
```python
from paddlenlp import Taskflow
# Chinese Word Segmentation
seg = Taskflow("word_segmentation")
seg("第十四届全运会在西安举办")
>>> ['第十四届', '全运会', '在', '西安', '举办']
# POS Tagging
tag = Taskflow("pos_tagging")
tag("第十四届全运会在西安举办")
>>> [('第十四届', 'm'), ('全运会', 'nz'), ('在', 'p'), ('西安', 'LOC'), ('举办', 'v')]
# Named Entity Recognition
ner = Taskflow("ner")
ner("《孤女》是2010年九州出版社出版的小说,作者是余兼羽")
>>> [('《', 'w'), ('孤女', '作品类_实体'), ('》', 'w'), ('是', '肯定词'), ('2010年', '时间类'), ('九州出版社', '组织机构类'), ('出版', '场景事件'), ('的', '助词'), ('小说', '作品类_概念'), (',', 'w'), ('作者', '人物类_概念'), ('是', '肯定词'), ('余兼羽', '人物类_实体')]
# Dependency Parsing
ddp = Taskflow("dependency_parsing")
ddp("9月9日上午纳达尔在亚瑟·阿什球场击败俄罗斯球员梅德韦杰夫")
>>> [{'word': ['9月9日', '上午', '纳达尔', '在', '亚瑟·阿什球场', '击败', '俄罗斯', '球员', '梅德韦杰夫'], 'head': [2, 6, 6, 5, 6, 0, 8, 9, 6], 'deprel': ['ATT', 'ADV', 'SBV', 'MT', 'ADV', 'HED', 'ATT', 'ATT', 'VOB']}]
# Sentiment Analysis
senta = Taskflow("sentiment_analysis")
senta("这个产品用起来真的很流畅,我非常喜欢")
>>> [{'text': '这个产品用起来真的很流畅,我非常喜欢', 'label': 'positive', 'score': 0.9938690066337585}]
```
## API Reference
- Support [LUGE](https://www.luge.ai/) dataset loading and compatible with Hugging Face [Datasets](https://huggingface.co/datasets). For more details please refer to [Dataset API](https://paddlenlp.readthedocs.io/zh/latest/data_prepare/dataset_list.html).
- Using Hugging Face style API to load 500+ selected transformer models and download with fast speed. For more information please refer to [Transformers API](https://paddlenlp.readthedocs.io/zh/latest/model_zoo/index.html).
- One-line of code to load pre-trained word embedding. For more usage please refer to [Embedding API](https://paddlenlp.readthedocs.io/zh/latest/model_zoo/embeddings.html).
Please find all PaddleNLP API Reference from our [readthedocs](https://paddlenlp.readthedocs.io/).
## Community
### Slack
To connect with other users and contributors, welcome to join our [Slack channel](https://paddlenlp.slack.com/).
### WeChat
Scan the QR code below with your Wechat⬇️. You can access to official technical exchange group. Look forward to your participation.

## Citation
If you find PaddleNLP useful in your research, please consider cite
```
@misc{=paddlenlp,
title={PaddleNLP: An Easy-to-use and High Performance NLP Library},
author={PaddleNLP Contributors},
howpublished = {\url{https://github.com/PaddlePaddle/PaddleNLP}},
year={2021}
}
```
## Acknowledge
We have borrowed from Hugging Face's [Transformers](https://github.com/huggingface/transformers)🤗 excellent design on pretrained models usage, and we would like to express our gratitude to the authors of Hugging Face and its open source community.
## License
PaddleNLP is provided under the [Apache-2.0 License](./LICENSE).